做了一个暑假的pwn还是菜鸡一枚,慢慢前进吧! Jarvis OJ Backdoor题还是看了writeup,这里写一写理解过程吧。
一、题目
这是一个有后门的程序,有个参数可以触发该程序执行后门操作,请找到这个参数,并提交其SHA256摘要。(小写)
FLAG:PCTF{参数的sha256}
给了一个文件vulnerable.rar
给出了提交flag的格式,关键就是要找到触发程序后面的参数。解压这个vulnerable.rar发现不同于之前做的XMAN level,这次的可执行文件是.exe后缀的,显然是windows系统上的[因为linux不同于dos/windows靠文件后缀名来判断是否可执行。而主要是靠文件属性来判断。所以有.exe后缀的,一看就是windows平台上的可执行文件啦],所以不要去linux上执行啦。
但是你在win10上执行,会提示:
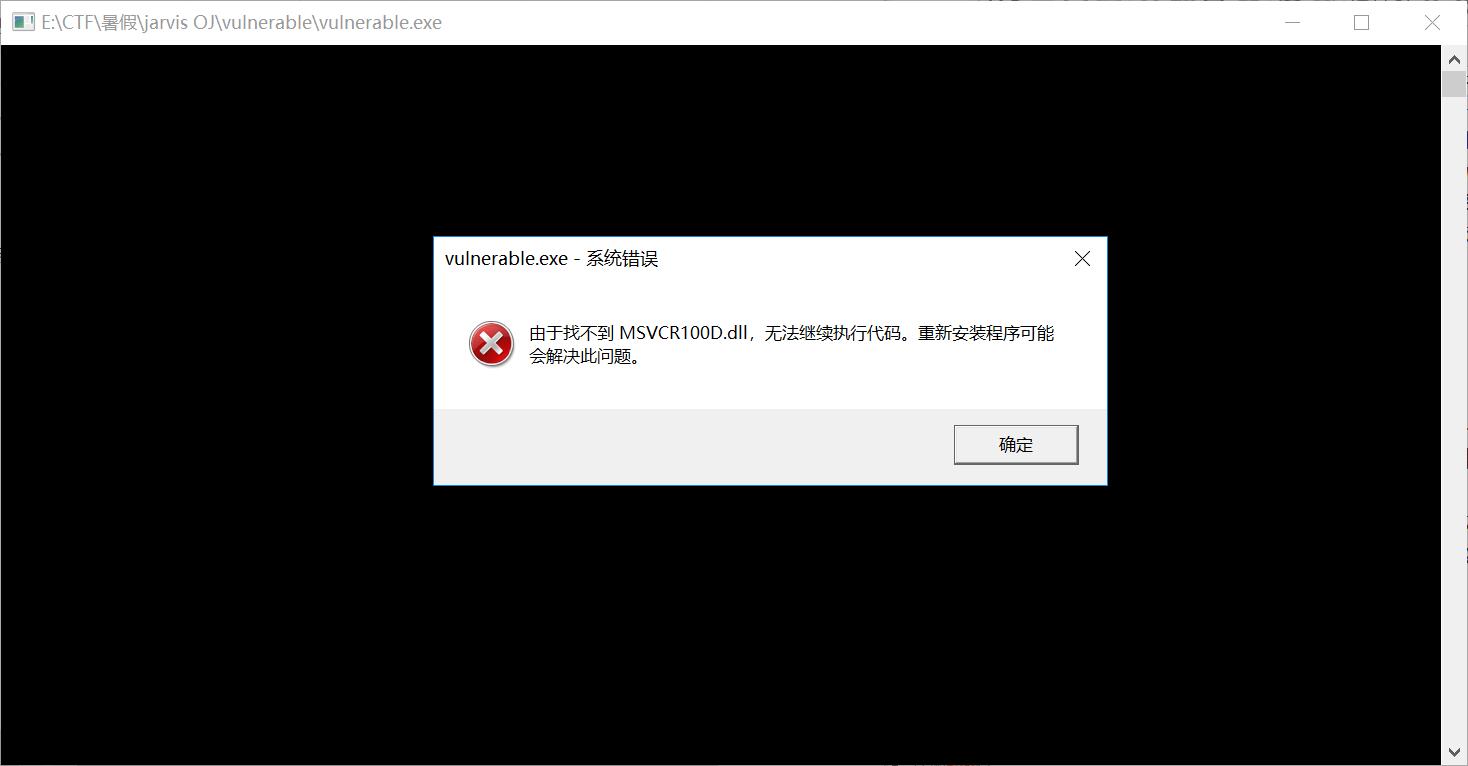
它用了msvcr100d.dll,这个库就是vc++的运行库文件就是vs编译时用debug版本,编译出来时用的dll。
我本地没有这个dll,就网上找一个,放到当前目录就好:http://www.duote.com/dll/msvcr100d_dll.html
执行出来就是一个计算器,接下来开始找找后门吧。
二、解析反汇编
老样子,拖到IDA中反汇编。
一开始进去在函数窗口里面,估计最引人注目的就是wmain毕竟看起来像是main,估计程序要从这里开始了。
wmain
首先我们来回顾一下main:
有些编译器允许将main()的返回类型声明为void,这已不再是合法的C++ main(int argc, char * argv[ ], char **env)才是UNIX和Linux中的标准写法。
argc,argv 用命令行编译程序时有用。
argc: 整数,用来统计你运行程序时送给main函数的命令行参数的个数,这个是自动计算出来的,不用在cmd中手动给出
* argv[ ]: 指针数组,用来存放指向你的字符串参数的指针,每一个元素指向一个参数
argv[0] 指向程序运行的全路径名
argv[1] 指向在DOS命令行中执行程序名后的第一个字符串
argv[2] 指向执行程序名后的第二个字符串
...
argv[argc]为NULL
**env:字符串数组。
env[ ]的每一个元素都包含ENVVAR=value形式的字符 串。其中ENVVAR为环境变量,value 为ENVVAR的对应值。
argc, argv,env是在main( )函数之前被赋值的,编译器生成的可执行文件,main( )不是真正的入口点,而是一个标准的函数,这个函数名与具体的操作系统有关。
1.argc
包含 argv 后面的参数计数的整数。 argc 参数始终大于或等于 1。
2.argv
表示由杂注用户输入的命令行参数的以 null 结尾的字符串的数组。 按照约定,argv[0] 是用于调用程序的命令,argv[1] 是第一个命令行参数,依此类推,直到 argv[argc],它始终为 NULL。
第一个命令行参数始终是 argv[1],且最后一个命令行参数是 argv[argc – 1]
3.示例
对于理解argv[ ]函数很管用:
#include <stdio.h>//#包含<stdio.h>
int main(int argc,char* argv[])//整数类型主函数(整数类型统计参数个数,字符类型指针数组指向字符串参数)
{
printf("%d\n",argc); //格式化输出
while(argc)//当(统计参数个数)
printf("%s\n",argv[--argc]); //格式化输出
return 0; //返回0;正常退出
}
假设将其编译为 test.exe 在命令行下
test.exe test hello
得到的输出结果为
3
hello
test
test.exe
4.找Microsoft文档中对wmain的解释
在 Unicode 编程模型中,可以定义 main 函数的宽字符版本,也就是wmain。 若要编写符合 Unicode 规范的可移植代码,请使用 wmain 而不是 main。
使用与 main 的相似格式声明 wmain 的形参。 然后可以将宽字符参数和宽字符环境指针(可选)传递给该程序。 wmain 的 argv 和 envp 参数为 wchar_t * 类型。 如果程序使用 main 函数,则多字节字符环境由操作系统在程序启动时创建。
int main( int argc[ , char *argv[ ] [, char *envp[ ] ] ] );
int wmain( int argc[ , wchar_t *argv[ ] [, wchar_t *envp[ ] ] ] );
这样说来,wmain只不过是main的unicode版本了,main函数传入的命令行参数值argv是char的数组,wmain函数传入的命令行argv是wchar_t的数组,所以本质上差不多的。
分析wmain程序
通过对wmain的了解,我们大致可以猜测IDA反汇编的结果中wmain(int a1, int a2),其中a1应该就是argc,表示命令行中参数的数量,会自动获取,计算出值。而a2就是wchar_t *argv[],来自于命令行的输入。
至于这里为什么命名为a1、a2,而且类型还是int,很不能理解。估计a2是指wchar_t *argv[]的首地址。我也有看到有人贴了编译成:
int __cdecl main(int argc, const char **argv, const char **envp){
...
}
这就看起来就舒服很多。
现在以我自身反汇编的结果来说吧,本篇最后会附上看起来舒服的IDA结果。
signed int __cdecl wmain(int a1, int a2)
{
char v3; // [esp+50h] [ebp-2C8h]
char v4; // [esp+E1h] [ebp-237h]
char v5; // [esp+E4h] [ebp-234h]
char Source[4]; // [esp+100h] [ebp-218h]
char v7; // [esp+104h] [ebp-214h]
__int16 i; // [esp+108h] [ebp-210h]
char Dest[2]; // [esp+10Ch] [ebp-20Ch]
char Dst; // [esp+10Eh] [ebp-20Ah]
char v11[25]; // [esp+110h] [ebp-208h]
char v12[483]; // [esp+129h] [ebp-1EFh]
__int16 v13; // [esp+30Ch] [ebp-Ch]
LPSTR lpMultiByteStr; // [esp+310h] [ebp-8h]
int cbMultiByte; // [esp+314h] [ebp-4h]
//如果a2是指wchar_t argv[]的首地址,那么a2+4就是argv[1]
cbMultiByte = WideCharToMultiByte(1u, 0, *(LPCWSTR *)(a2 + 4), -1, 0, 0, 0, 0);
lpMultiByteStr = (LPSTR)sub_4011F0(cbMultiByte);
WideCharToMultiByte(1u, 0, *(LPCWSTR *)(a2 + 4), -1, lpMultiByteStr, cbMultiByte, 0, 0); //这以上的部分是unicode和char的转化,把命令行的argv[1]也就是a2放到lpMultiByteStr
v13 = *(_WORD *)lpMultiByteStr; //这里又使用lpMultiByteStr给v13赋值,最终结果就是命令行输入的第一个参数argv[1],就放到了v13这个变量中
if ( v13 < 0 ) //但是v13在定义中是__int16,也就是16位的,两字节哦,不是4字节int
return -1;
v13 ^= 0x6443u; //对输入的命令行参数进行了异或
strcpy(Dest, "0");
memset(&Dst, 0, 0x1FEu);
for ( i = 0; i < v13; ++i ) //命令行的第一个参数的数值有多少,就填充几个'A'在栈中,但是实际Dest[2],就2个字节的空间,v13大一点就会越界
Dest[i] = 65; //65其实是'A',这里看上去就是padding了吧
*(_DWORD *)Source = 0x7FFA4512;//0x7FFA4512是windows上一个万能的jmp esp(几乎所有平台这个地址上都是jmp esp)
v7 = 0;
strcpy(&Dest[v13], Source);//这里把0x7FFA4512这个地址传到了Dest[v13]。这里应该为Dest[]添加了结束符\0(Source把结束符给给了Dest[v13])
qmemcpy(&v5, &unk_4021FC, 0x1Au); //后面就是一些随意的填充了,把栈的某些位置的数据改了改
strcpy(&v11[v13], &v5);
qmemcpy(&v3, &unk_402168, 0x91u);
v4 = 0;
strcpy(&v12[v13], &v3);
sub_401000(Dest); //这里说不定也有bug呢
return 0;
}
分析到这里我们差不多已经可以确定溢出点了。我们只要给定命令行参数一个合适的值x[最后会赋值给v13],通过给定较大的v13越界栈上的char Dest[2]。通过for ( i = 0; i < v13; ++i ) Dest[i] = ‘A’;将栈上布满padding:A。 又由于* (_DWORD *)Source = 0x7FFA4512;和strcpy(&Dest[v13], Source);使得Dest[v13]会得到一个jmp esp的地址。假如正好Dest[v13]对应栈上返回地址的位置,那么我们的程序就会跳转到jmp esp指令执行,jmp esp将返回地址后面的4字节内存单元的数据作为地址,跳转。假如这个地址被我们设置成一个恶意程序地址[本题中设置的是一个开启计算器程序的首地址],那么攻击就实现了。所以这就是一个有后门的程序[存在缺陷,可以相应实施攻击]
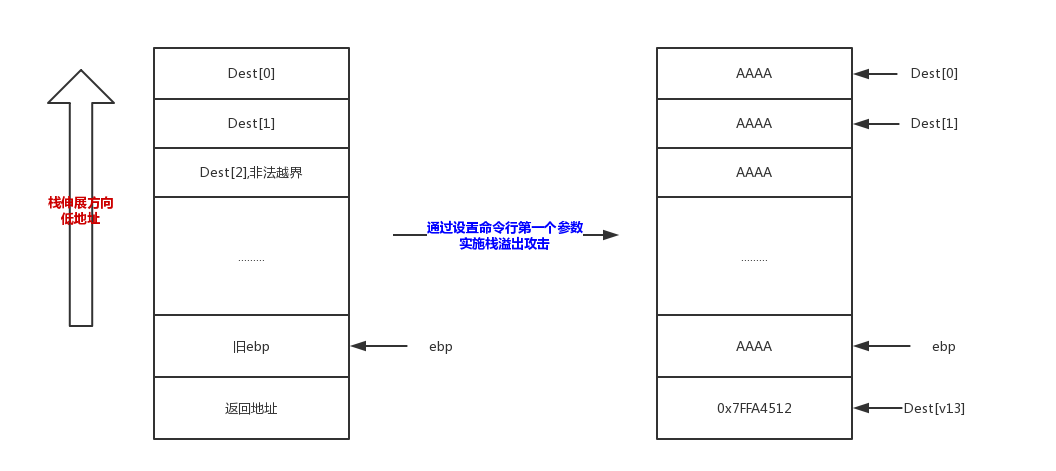
总的来说,那个v13就是padding的长度,我们的输入就是合适的offset ^ 0x6443[这样就抵消了v13 ^= 0x6443u中的异或]。
假如你在main里栈溢出,会不成功。缘由就在于,突然在栈布局里,v13就在dest的高地址方向。如果dest溢出去覆盖ret,那v13会被改成”AAAA”,这个数太大。那么for ( i = 0; i < v13; ++i )就要循环很久了,甚至离开栈段,可能会直接GG。更何况strcpy(&Dest[v13], Source);执行时,v13就不是设置好的初始给命令行的参数值了,0x7FFA4512就会放到很高很高的地址处了。那么jmp esp也就不会执行了
PS:在反汇编窗口中双击变量,就可以得到静态栈帧布局

和反汇编结果的注释一致:
char Source[4]; // [esp+100h] [ebp-218h]
char Dest[2]; // [esp+10Ch] [ebp-20Ch]
__int16 v13; // [esp+30Ch] [ebp-Ch]
好在source在Dest[]上面不会被padding覆盖。
三、那么可疑点剩下sub_401000(Dest)
在wmain中将sub_401000(Dest);数据送到函数sub_401000中。
IDA反汇编结果:
int __cdecl sub_401000(char *Source)
{
char Dest[2]; // [esp+4Ch] [ebp-20h]
int v3; // [esp+4Eh] [ebp-1Eh]
int v4; // [esp+52h] [ebp-1Ah]
int v5; // [esp+56h] [ebp-16h]
int v6; // [esp+5Ah] [ebp-12h]
int v7; // [esp+5Eh] [ebp-Eh]
int v8; // [esp+62h] [ebp-Ah]
int v9; // [esp+66h] [ebp-6h]
__int16 v10; // [esp+6Ah] [ebp-2h]
strcpy(Dest, "0");
v3 = 0;
v4 = 0;
v5 = 0;
v6 = 0;
v7 = 0;
v8 = 0;
v9 = 0;
v10 = 0;
strcpy(Dest, Source);
return 0;
}
这里把Source赋值给了Dest,而Source在main中就是Dest[]( main中strcpy(&Dest[v13], Source);中为Dest[v13]后加了NULL,strcpy:把从src地址开始且含有NULL结束符的字符串复制到以dest开始的地址空间),所以在这个函数栈中,Dest得到了前面的paddings(‘A’)+0x7FFA4512。
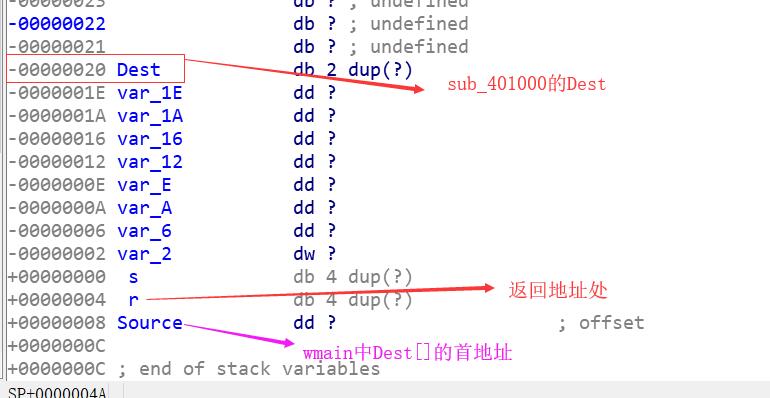
既然有v13可以设置padding大小,还有0x7FFA4512。那么可以尝试在sub_401000(Dest);里进行栈溢出。
char Dest[2]; // [sp+4Ch] [bp-20h]
显然只需要paddings大小为0x20+4【覆盖旧ebp】,还有4字节的0x7FFA4512。
所以传入的source,也就是wmain中Dest[]只需要占用wmain栈帧中的0x28字节。
这点空间,对于从ebp-20Ch开始的Dest,完全覆盖不到,ebp-Ch的v13
char Dest[2]; // [esp+10Ch] [ebp-20Ch]
__int16 v13; // [esp+30Ch] [ebp-Ch]
所以v13只需要设置成0x24^0x6443就好[2字节的v13]。
因此输入的命令行参数就是chr(0x24^0x43),chr(0x00^0x64)。【对应char* argv[1]=chr(0x24^0x43)chr(0x00^0x64)。在我的IDA结果中,a2是char * argv[]的首地址,那么a2+4就是char* agrv[1]的地址。那么在wmain中前几行转换中的* (LPCWSTR *)(a2 + 4)赋值给lpMultiByteStr,也就是将agrv[1]的值给了lpMultiByteStr】
四、执行后门的脚本
import hashlib
flag=""
flag+=chr(0x24^0x43)
flag+=chr(0x00^0x64)
print hashlib.sha256(flag).hexdigest()
或者:
import hashlib
offset = 0x20 + 4
a = hex(offset ^ 0x6443)[2:]
a = a.decode('hex')[::-1] //[::-1]反向,比如"abc" 变成"cba"
print "PCTF{" + hashlib.sha256(a).hexdigest() + "}"
flag : PCTF{2b88144311832d59ef138600c90be12a821c7cf01a9dc56a925893325c0af99f}
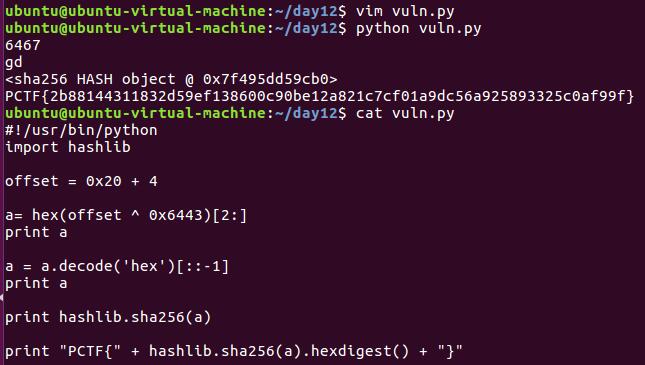
所以输入命令行的参数就是gb[b:0x00^0x64,g:0x24^0x43],对字符串而言,b为高地址,转化成int v13后,高地址的b就对应v13的高位[v13可是__int 16,两字节的],所以v13就是0x0024
五、要记住
1.7FFA4512h地址上是windows上一个万能的jmp esp
2.摘要算法/hash算法——hashlib
-
摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)。摘要算法就是通过摘要函数f()对任意长度的数据data计算出固定长度的摘要digest。目的可以减少数据长度,此外还可以发现原始数据是否被人篡改过。摘要算法之所以能指出数据是否被篡改过,就是因为摘要函数是一个单向函数,计算f(data)很容易,但通过digest反推data却非常困难。而且,对原始数据做一个bit的修改,都会导致计算出的摘要完全不同。
-
hashlib 是一个提供了一些流行的hash算法的 Python 标准库.其中所包括的算法有 md5, sha1, sha224, sha256, sha384, sha512
-
hash.digest() 返回摘要,作为二进制数据字符串值
-
hash.hexdigest() 返回摘要,作为十六进制数据字符串值
举例: 以常见的摘要算法MD5为例,计算出一个字符串的MD5值:
import hashlib
md5 = hashlib.md5()
md5.update('how to use md5 in python hashlib?')
print md5.hexdigest()
计算结果如下:
d26a53750bc40b38b65a520292f69306
如果数据量很大,可以分块多次调用update(),最后计算的结果是一样的:
md5 = hashlib.md5()
md5.update('how to use md5 in ')
md5.update('python hashlib?')
print md5.hexdigest()
MD5是最常见的摘要算法,速度很快,生成结果是固定的128 bit字节,通常用一个32位的16进制字符串表示。
六、可参考的main反汇编结果
int __cdecl main(int argc, const char **argv, const char **envp)
{
int result; // eax@2
char v4; // [sp+50h] [bp-2C8h]@6
char v5; // [sp+E1h] [bp-237h]@6
char v6; // [sp+E4h] [bp-234h]@6
char Source[4]; // [sp+100h] [bp-218h]@6
__int16 i; // [sp+108h] [bp-210h]@3
char Dest[512]; // [sp+10Ch] [bp-20Ch]@3
__int16 offset; // [sp+30Ch] [bp-Ch]@1
LPSTR lpMultiByteStr; // [sp+310h] [bp-8h]@1
int cbMultiByte; // [sp+314h] [bp-4h]@1
cbMultiByte = WideCharToMultiByte(1u, 0, (LPCWSTR)argv[1], -1, 0, 0, 0, 0);
lpMultiByteStr = (LPSTR)unknown_libname_1(cbMultiByte);
WideCharToMultiByte(1u, 0, (LPCWSTR)argv[1], -1, lpMultiByteStr, cbMultiByte, 0, 0);
offset = *(_WORD *)lpMultiByteStr;// 上面一坨不用管,总之就是unicode和char的转换
if ( offset >= 0 )
{
offset ^= 0x6443u; // padding
strcpy(Dest, "0");
memset(&Dest[2], 0, 510u);
for ( i = 0; i < offset; ++i )
Dest[i] = 'A';
strcpy(Source, "\x12E"); // 7FFA4512h->jmp esp
strcpy(&Dest[offset], Source);
qmemcpy(&v6, &code_nop, 26u); // nopnopnop
strcpy(&Dest[offset + 4], &v6);
qmemcpy(&v4, &code, 0x91u);
v5 = 0;
strcpy(&Dest[offset + 29], &v4);
sub_401000(Dest);
result = 0;
}
else
{
result = -1;
}
return result;
}