基础环境
通过git clone https://pdos.csail.mit.edu/6.828/2018/jos.git lab搭建实验环境,并在lab目录中输入make(或BSD系统上的gmake)来构建最小的6.828引导加载程序[boot loader]和内核。
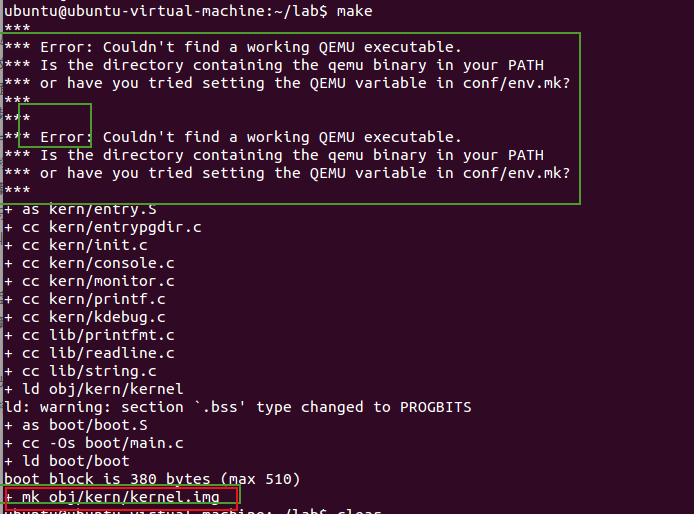
make后生成了一个 kernel.img 的镜像。
-
但是出现了Error,之前构建的之后没有加入到PATH。
-
sudo vim /etc/profile,在该配置文件中最后一行加入export PATH=”<路径>:$PATH"
-
使用. 或source执行这个shell,以生效。
-
make clean后,重新make还是有这个错误
-
尝试提示的在conf/env.mk中设置QEMU变量,解决
现在运行QEMU,将上面创建的文件obj / kern / kernel.img作为模拟PC“虚拟硬盘”的内容以提供。此硬盘映像包含我们的引导加载程序(obj / boot / boot)和内核(obj / kernel)。
执行 make qemu 就会用 qemu 去运行这个镜像.
- 使用make qemu,输入和输出是会在QEMU显示窗口和常规shell窗口中同步的
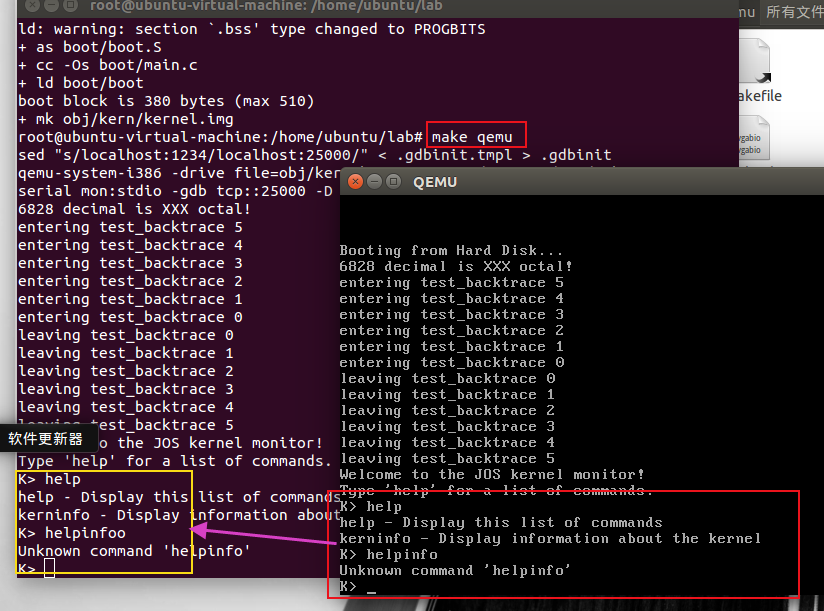
至此,环境完全搭建好了。使用ctrl+a x退出QEMU
实验指导中提到,生成的obj/kern/kernel.img文件是可以放到真实的物理硬件上来执行的。
即通过将obj / kern / kernel.img的内容复制到真实硬盘的前几个扇区,将该硬盘插入真正的PC,打开它,然后看到和当前完全相同的东西。【当然不建议真机测试,毕竟将kernel.img复制到其硬盘的开头将废弃主引导记录和第一个分区的开头】
PC物理地址空间布局
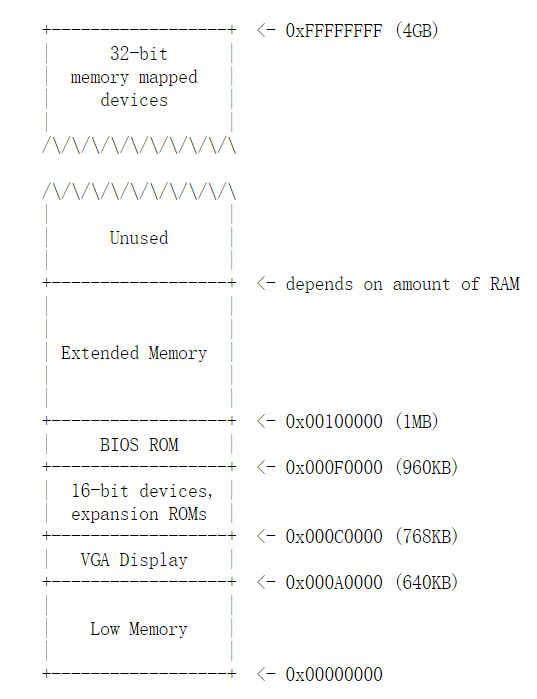
RAM由Extended Memory和Low Memory两个分隔的部分组成,中间是一些固件等。
- 早期,基于16位Intel 8088处理器的PC仅能够处理1MB的物理内存。因此,早期PC的物理地址空间将从0x00000000开始,但以0x000FFFFF而不是0xFFFFFFFF结束。标有“low memory”的640KB区域是早期PC可以使用的唯一随机存取存储器(RAM);【事实上,最早的PC只能配置16KB,32KB或64KB的RAM】
- 从0x000A0000到0x000FFFFF的384KB区域由硬件保留用于特殊用途,例如视频显示缓冲区和非易失性存储器中保存的固件。此保留区域最重要的部分是基本输入/输出系统(BIOS),它占用从0x000F0000到0x000FFFFF的64KB区域。【在早期的PC中,BIOS保存在真正的只读存储器(ROM)中,但是当前的PC将BIOS存储在可更新的闪存中。 BIOS负责执行基本系统初始化,例如激活视频卡和检查安装的内存量。执行此初始化后,BIOS从某些适当的位置(如软盘,硬盘,CD-ROM或网络)加载操作系统,并将机器的控制权交给操作系统。】
- 当英特尔最终分别支持16MB和4GB物理地址空间的80286和80386处理器,PC架构师仍保留了原有的低1MB物理地址空间布局,以确保向后兼容现有软件。【故视频显示缓冲区和固件部分没动,而在他们之上增加RAM】
- 因此,现代PC在物理内存中有一个“hole”,从0x000A0000到0x00100000,将RAM分为“low memory”【0x0x00000000-0x000A0000=640KB】和“extended memory”【中间有一个存放固件,eg:BIOS的洞】。此外,PC的32位物理地址空间【 above all physical RAM】顶部的一些空间,现在通常由BIOS保留,供32位PCI设备【总线】使用【即32-bit memory mapped devices】。
- 现在x86处理器可以支持4GB以上的物理RAM,因此RAM可以进一步扩展到0xFFFFFFFF以上【>4GB】。在这种情况下,BIOS必须安排在32位可寻址区域顶部的系统RAM中留下第二个“hole ”【在大于4GB的地址空间扩展RAM】,为这些32位设备留出空间。
注:由于设计限制,无论如何,JOS将只使用PC的物理内存的低地址处的256MB,所以现在我们将假装所有PC仅拥有32位物理地址空间。
THE ROM BIOS
用到QEMU的debug功能来深入了解IA-32计算机的启动流程。 进入lab目录,打开两个termainal
- 一个窗口运行
make qemu-nox-gdb/make qemu-gdb- 这将启动QEMU,但QEMU在处理器执行第一条指令之前停止,并等待来自GDB的调试连接。
- 另外一个窗口运行
make gdb- 因为提供了一个
.gdbinit文件,能够自动地attach到想要调试的程序【the 16-bit code used during early boot 】上来
- 因为提供了一个
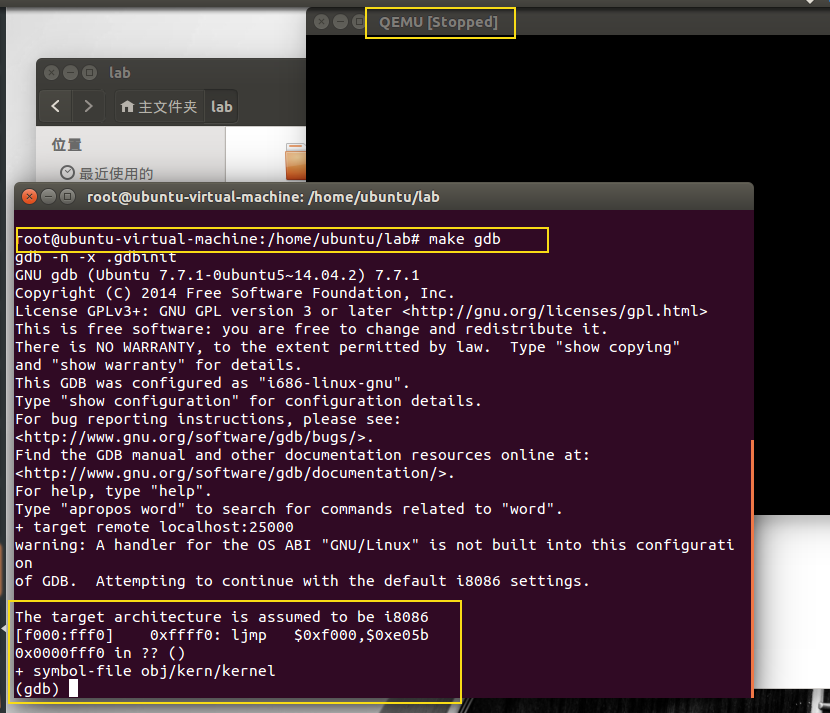
[f000:fff0] 0xffff0: ljmp $0xf000,$0xe05b
是GDB反汇编出的第一条执行指令,这条指令表面了:
- IBM PC 执行的起始物理地址为 0x000ffff0
- [f000:fff0]:PC 的偏移方式为 CS = 0xf000,IP = 0xfff0
- 第一条指令执行的是 jmp指令,跳转到段地址 CS = 0xf000,IP = 0xe05b
QEMU模拟了8088处理器的启动,当启动电源,BIOS最先控制机器【由于PC中的BIOS与物理地址范围0x000f0000-0x000fffff“硬连线”,因此该设计可确保BIOS在上电或任何系统重启后始终首先控制机器】,这时还没有其他程序执行,之后处理器进入实模式也就是设置 CS 为 0xf000,IP 为 0xfff0。
在启动电源也就是实模式【20位】时,地址转译根据:物理地址 = 16 * 段地址 + 偏移量。所以 PC 中 CS 为 0xf000,IP 为 0xfff0 的物理地址为:
16 * 0xf000 + 0xfff0 # 十六进制中乘16很容易
= 0xf0000 + 0xfff0 # 仅仅添加一个0.
= 0xffff0
0xffff0 是BIOS (0x100000)结束前的16个字节,但是它不可能在16个字节内完成任务,因此就调用了jmp指令,跳转到0xfe05b
用gdb的si指令来单步执行,看看BIOS的功能:
- 当BIOS在运行的时候。会在内存的超始地址处建立一个各种设备的16位的中断向量表,并且初始化各种设备【我记得有鼠标位置,VGA显示器啥的——因此你可以看到QEMU中输出”Start SeaBIOS”】
- 当初始化PCI总线和硬件设备之后。BIOS就开始找可引导的设备【如软盘,硬盘驱动器或CD-ROM。】,最终会在硬盘的起始sector里面找0x55, 0xaa这标志位的扇区【即为bootable disk】。BIOS从可引导磁盘中读取boot loader并将控制权转移给它.【加载到0x7c00处开始运行。也就是(31KB)的位置】。
[f000:fff0] 0xffff0: ljmp $0xf000,$0xe05b # 跳到一个较早的位置
[f000:e05b] 0xfe05b: cmpl $0x0,%cs:0x6ac8
[f000:e062] 0xfe062: jne 0xfd2e1 # 测试cs段的0x6ac8字是否为0
[f000:e066] 0xfe066: xor %dx,%dx # 测试为0
[f000:e068] 0xfe068: mov %dx,%ss
[f000:e06a] 0xfe06a: mov $0x7000,%esp # 设置栈段寄存器和栈指针寄存器
# 栈的延伸方向和代码段延伸方向相反
[f000:e070] 0xfe070: mov $0xf34c2,%edx # 设置edx寄存器值
[f000:e076] 0xfe076: jmp 0xfd15c # 跳转
[f000:d15c] 0xfd15c: mov %eax,%ecx
[f000:d15f] 0xfd15f: cli # 关闭硬件中断
[f000:d160] 0xfd160: cld # 设置串传送指令方向
[f000:d161] 0xfd161: mov $0x8f,%eax
[f000:d167] 0xfd167: out %al,$0x70 # 关闭不可屏蔽中断
[f000:d169] 0xfd169: in $0x71,%al # 从CMOS读取选择的寄存器
[f000:d16b] 0xfd16b: in $0x92,%al # 读取系统控制端口A
[f000:d16d] 0xfd16d: or $0x2,%al
[f000:d16f] 0xfd16f: out %al,$0x92 # 通过快速A20以启动A20
[f000:d171] 0xfd171: lidtw %cs:0x6ab8 # 将cs:0x6ab8加载进入IDT表
[f000:d177] 0xfd177: lgdtw %cs:0x6a74 # 将cs:0x6a74加载进入GDT表
[f000:d17d] 0xfd17d: mov %cr0,%eax
[f000:d180] 0xfd180: or $0x1,%eax
[f000:d184] 0xfd184: mov %eax,%cr0 # 将cr0寄存器的保护模式位打开!!!
[f000:d187] 0xfd187: ljmpl $0x8,$0xfd18f # 通过ljmp指令进入保护模式
#The target architecture is assumed to be i386
=> 0xfd18f: mov $0x10,%eax # 设置段寄存器
=> 0xfd194: mov %eax,%ds
=> 0xfd196: mov %eax,%es
=> 0xfd198: mov %eax,%ss
=> 0xfd19a: mov %eax,%fs
=> 0xfd19c: mov %eax,%gs
=> 0xfd19e: mov %ecx,%eax
=> 0xfd1a0: jmp *%edx # 跳转
……
The Boot Loader
综述
PC的软盘和硬盘被分为一个个512个字节区域,每个区域被称为扇区。
扇区是磁盘的最小单元:每个读取或写入操作必须是一个或多个扇区,并在扇区边界上对齐。
如果磁盘是可引导的,则第一个扇区称为引导扇区,因为这个扇区是the boot loader code 所在的位置。 当BIOS找到可引导的软盘或硬盘时,它将512字节的引导扇区加载到物理地址0x7c00-0x7dff【512字节大小】的内存中,然后使用jmp指令将CS:IP设置为0000:7c00,将控制权传递给boot loader。 和BIOS读取地址一样,这个地址对于PC来说是固定和标准化的。
Boot from CD-ROM
现代BIOS的boot方式和以往不太相同,现在是从CD-ROM引导【光盘引导】,较为复杂也更为强大。
由于CD-ROM使用的扇区大小为2048字节而不是512,并且BIOS可以在将控制转移到内存之前将更大的引导映像从磁盘加载到内存(而不仅仅是one sector)。具体参阅: the “El Torito” Bootable CD-ROM Format Specification.
Boot from hard disk
对于6.828,我们将使用传统的硬盘启动机制,这意味着我们的启动加载程序必须适合512字节。
the boot loader 【引导加载程序】由一个汇编语言源文件boot/boot.S和一个C源文件boot/main.c组成。
引导加载程序必须执行两个主要功能:
-
将处理器从实模式切换到32位保护模式,因为只有在此模式下,软件才能访问处理器物理地址空间中1MB以上的所有内存【原来的实模式是16-20位线性地址,寻址空间为2^20=1MB,只能寻址到1MB,因此对于1MB以上的空间必须做模式转化,转化为32-bit protected mode,以提高寻址空间】。
-
保护模式:将分段地址(段:偏移对)转换为物理地址在保护模式下的转换方式不同,并且在转换偏移之后转换为32位而不是16位。
-
保护模式地址转化参考:保护模式下的段寄存器值转化为线性地址过程和保护模式下寻址
-
简单来说就是:将段寄存器作为段选择子,以此中的13位为索引,到GDT表或LDT表【全局/局部描述符表】中找到段描述符【64位,包含了32位的段基址,还有优先级和权限保护等段属性和段界限】,从而得到段基址,再加上偏移得到线性地址。
-
全局描述符表第一个项值规定是空值,unused。全局描述符表的首地址由GDTR寄存器给出,这个值是线性地址,不需要解析。GDTR是一个48位的值,16-47位范围共32位表示(Base Address)GDT基地址,0-15位范围共16位(Limit)表示GDT表的大小(以字节计算)。【 在windbg内核模式,可以用r gdtr命令列出32位的GDT基地址,用rgdtl列出16位的GDT大小值。】
-
通过以上转化,逻辑/虚拟地址-线性地址【分段机制】,还要通过页表转化才使得线性地址-物理地址【分页机制】。

-
注意:通用寄存器在保护模式下是32位,段寄存器没有改变,还是16位
-
-
其次,引导加载程序通过x86的特殊I/O指令直接访问IDE磁盘设备寄存器,以从硬盘读取内核。
在了解了引导加载程序源代码之后,请查看文件obj/boot/boot.asm【引导加载程序的反汇编文件】。这个反汇编文件可以很容易地查看所有引导加载程序代码所在的物理内存的确切位置,并且可以更轻松地跟踪在GDB中单步执行引导加载程序时发生的情况。同样,obj/kern/kernel.asm包含一个JOS内核的反汇编,它通常可用于调试。
解析boot loader源码实现
boot loader 【引导加载程序】由一个汇编语言源文件boot/boot.S和一个C源文件boot/main.c组成。
1.boot.S解析
参考解析:mit 6.828 lab——第二部分 引导和boot.S源码解析
首先由BIOS找到引导扇区,将引导扇区【其中包含了boot.S】装载到物理地址0x7c00-0x7dff的内存中,此时还处于实模式,通过%cs=0 %ip=7c00,开始执行0x7c00处的boot.S。
- boot.S 主要将CPU切换至32位保护模式,并且跳转进入C代码【main.c】
- 打开A20地址线,使得1MB以上内存可连续寻址,而非回卷到0
- 加载GDT表基址,设置cr0=1进入保护模式,jmp到保护模式的下一条指令,设置栈顶%esp,并call main.c中的bootmain函数【该函数不应该返回,返回就执行死循环】
- boot.S最后指示了GDT表和GDT表的基址寄存器
- 初始GDT表解析,参考链接:
- http://blog.chinaunix.net/uid-24585655-id-2125527.html
- https://blog.csdn.net/qq_36116842/article/details/79971202
#include <inc/mmu.h>
# Start the CPU: switch to 32-bit protected mode, jump into C.
# The BIOS loads this code from the first sector of the hard disk into
# memory at physical address 0x7c00 and starts executing in real mode
# with %cs=0 %ip=7c00.
# boot.S 主要将CPU切换至32位保护模式,并且跳转进入C代码
#设置.set指令类似于宏定义
.set PROT_MODE_CSEG, 0x8 # kernel code segment selector,内核代码段选择子
.set PROT_MODE_DSEG, 0x10 # kernel data segment selector,内核数据段选择子
.set CR0_PE_ON, 0x1 # protected mode enable flag,保护模式使能标志
#定义一个全局名字start
.globl start
start: # 程序入口
.code16 # Assemble for 16-bit mode 指导生成16位汇编代码
cli # Disable interrupts,关中断
cld # String operations increment,设置串传递顺序递增
# Set up the important data segment registers (DS, ES, SS). 设置重要的段寄存器为0
xorw %ax,%ax # Segment number zero
movw %ax,%ds # -> Data Segment
movw %ax,%es # -> Extra Segment
movw %ax,%ss # -> Stack Segment
# Enable A20:
# For backwards compatibility with the earliest PCs, physical
# address line 20 is tied low, so that addresses higher than
# 1MB wrap around to zero by default. This code undoes this.
# 开启A20
seta20.1:
inb $0x64,%al # Wait for not busy 等待缓冲区可用
testb $0x2,%al # Test for bit1
# if bit1 = 1 then buffer is full
jnz seta20.1 #如果al的第2位为1,说明键盘控制器输入缓冲区为满,不能对0x64端口写,因此循环检查
#直到键盘控制器输入缓冲区为空,对0x64端口写0xd1表示执行相应命令,该命令为:准备写入输出端口
movb $0xd1,%al # 0xd1 -> port 0x64
outb %al,$0x64 # Prepare to write output port
seta20.2:
inb $0x64,%al # Wait for not busy 等待缓冲区可用
testb $0x2,%al
jnz seta20.2 # The same as above 同上
#同理,直到键盘控制器输入缓冲区为空,对0x60输入端口写0xdf表示:打开A20
movb $0xdf,%al # 0xdf -> port 0x60
outb %al,$0x60 # 0xdf -> A20 gate enable command
# Switch from real to protected mode, using a bootstrap GDT
# and segment translation that makes virtual addresses
# identical to their physical addresses, so that the
# effective memory map does not change during the switch.
#gdtesc在该文件最下方,lgdt装载全局描述符的基地址和长度进入全局描述符表寄存器
lgdt gdtdesc # Load gdt size/base to gdtr 设置全局描述符表
movl %cr0, %eax # Control register 0,把控制寄存器cr0加载到eax中
# bit0 is protected enable bit
#cr0中的第0位为1表示处于保护模式,cr0中的第0位为0,表示处于实模式
#orl进行或运算,将结果保存在后一个寄存器,%eax中
orl $CR0_PE_ON, %eax # Set PE ON,将允许保护模式位,置1【$CR0_PE_ON来自于.set定义】
movl %eax, %cr0 # Update Control register 0 设置控制寄存器0的第0位为1
#此时处理器已处于保护模式寻址
# Jump to next instruction, but in 32-bit code segment.
# Switches processor into 32-bit mode.
#跳转到32位模式中的下一条指令。【由于寻址方式的改变,因此要重置相关的指令寄存器】
#下面这条指令执行的结果会将$PROT_MODE_CSEG加载到cs中,cs对应的高速缓冲存储器会加载GDT代码段描述符,同样将$protcseg加载到ip中
ljmp $PROT_MODE_CSEG, $protcseg # 通过ljmp指令(跳转至下一条指令)进入保护模式
.code32 # Assemble for 32-bit mode 指导生成32位汇编代码
protcseg:
# Set up the protected-mode data segment registers 设置保护模式的数据段寄存器
#$PROT_MODE_DSEG来自于.set定义,将数据段选择子装入到ax中
movw $PROT_MODE_DSEG, %ax # Our data segment selector
movw %ax, %ds # -> DS: Data Segment
movw %ax, %es # -> ES: Extra Segment
movw %ax, %fs # -> FS
movw %ax, %gs # -> GS
movw %ax, %ss # -> SS: Stack Segment
# Set up the stack pointer and call into C. 设置栈指针并且调用C
movl $start, %esp # Stack has the opposite extension direction than Code
# 注意栈的延伸方向和代码段相反
call bootmain #调用main.c中的bootmain函数
# If bootmain returns (it shouldn't), loop.
spin:
jmp spin #如果bootmain返回的话,就一直循环,按道理bootmain是不会返回的
# Bootstrap GDT 引导GDT
#强制4字节对齐
.p2align 2 # force 4 byte alignment
#以下是初始的GDT表,其中一个段的段描述符是64位【32位段基址+段界限+段属性】=8字节
#因此code seg的选择子偏移是0x8,data seg的选择子偏移是0x10
#【对应.set PROT_MODE_CSEG, 0x8和 .set PROT_MODE_DSEG, 0x10 】
gdt:
SEG_NULL # null seg 默认第一个段描述符为空
SEG(STA_X|STA_R, 0x0, 0xffffffff) # code seg 设置代码段描述符,第一个字段是权限【可执行/可读】
SEG(STA_W, 0x0, 0xffffffff) # data seg 设置数据段描述符【可写但是不可执行】
# 关于SEG宏可以参考mmu.h:SEG_NULL和SEG()是两个宏,展开后是利用汇编进行的空间申请
gdtdesc: # 用于设置全局段描述符寄存器
.word 0x17 # sizeof(gdt) - 1 # Size of gdt,gdt表的长度,以字节为单位
.long gdt # address gdt # Base address of gdt
注:以上也可以参照obj/boot/boot.asm文件阅读
背景补充:
- 实模式下各内存段均是可读、可写、可执行的,不支持指令优先级,所有的指令均运行在特权级;因此在实模式下16位段寄存器就够了,不需要存储额外的段属性,所有段的属性都一样。而保护模式的段基址+段属性+段界限就要存到64位。
- A20地址线的起源:在8086/8088中,当程序员给出超过1M(100000H-10FFEFH)的地址时,按照堆1M求模的方式进行的,这种技术被称为wrap-around。而到了80286,如果A20 Gate被打开,则当程序员给出100000H-10FFEFH之间的地址的时候,系统将真正访问这块内存区域;如果A20Gate被禁止,系统仍然使用8086/8088的方式,回卷从0起【从0xFFFFF进位到20位时,强制A20为0,因此0x100000回滚到0x00000。】
- 如果A20Gate被禁止,对于80286来说,其地址为24bit,其地址表示为EFFFFF;对于80386极其随后的32-bit芯片来说,其地址表示为FFEFFFFF。这种表示的意思是如果A20Gate被禁止,则其第20-bit在CPU做地址访问的时候是无效的,永远只能被作为0;如果A20 Gate被打开,则其第20-bit是有效的,其值既可以是0,又可以是1。所以,在保护模式下,如果A20Gate被禁止,则可以访问的内存只能是奇数1M段,即1M,3M,5M…,也就是00000-FFFFF,200000-2FFFFF,300000-3FFFFF…。如果A20 Gate被打开,则可以访问的内存则是连续的。因此,进入保护模式前需要先打开A20以获得完全的寻址能力。
- How to Enable A20Gate:多数PC都使用键盘控制器(8042芯片)来处理A20Gate。从理论上讲,打开A20Gate的方法是通过设置8042芯片输出端口(64h)的2nd-bit,但事实上,当你向8042芯片输出端口进行写操作的时候,在键盘缓冲区中,或许还有别的数据尚未处理,因此你必须首先处理这些数据。
- 8042有一个1 Byte的输入缓冲区,一个1 Byte的输出缓冲区、一个1 Byte的状态寄存器、以及一个1 Byte的控制寄存器。前三个寄存器可以直接从0x60和0x64端口进行访问。最后一个寄存器通过“Read Command Byte”命令进行读,通过“Write Command Byte”命令进行写。
- 对0x60端口读会读输入缓冲区;对0x60端口写会写输出缓冲区;对0x64端口读会读状态寄存器;对0x64端口写会发送命令。
- 状态寄存器的2nb-bit为IBF - Input Buffer Full,当该Bit为1时,输入缓冲区满,不能对0x60端口或0x64端口写
- 具体操作:禁止中断,判断输入缓冲区状态,为空时,对0x64端口写,会发送相关命令,比如写0xd1发送:命令是“Write Output Port”写输出端口,表明将参数写入输出端口(即对0x60端口写,写到键盘输出缓冲区)。
- 向输出端口写入0xdf可以打开A20;向输出端口写入0xdd则会关闭A20。
- A20使用的是键盘控制器输出的Bit 1
指令补充:
- cld指令及串操作:串指令常见有串传送指令MOVS、串存储指令STOS、串读取指令LODS等。串操作指令中,源操作数用寄存器SI寻址,默认在数据段DS中,但允许段超越;目的操作数用寄存器DI寻址,默认在附加段ES中,不允许段超越。每执行一次串操作指令,作为源地址指针的SI和作为目的地址指针的DI将自动修 改:+/-1(对于字节串)或+/-2(对于字串)。地址指针时增加还是减少取决于方向标志DF。在系统初始化后或者执行指令CLD指令后,DF=0,此时地址指针增1或2;在执行指令STD后,DF=1,此时地址指针减1或2。
- I/O操作指令:in, out(只能与DX,AX,AL寄存器结合使用),比如inb 从I/O端口读取一个字节,outb 向I/O端口写入一个字节,inw 从I/O端口读取一个字(WORD,即两个字节),outw 向I/O端口写入一个字。
- Test命令将两个操作数进行逻辑与运算,并根据运算结果设置相关的标志位。但是,Test命令的两个操作数不会被改变,运算结果在设置过相关标记位后会被丢弃。符号位SF = 结果的最高位;ZF=结果为0则置1,否则置0;奇偶校验位PF位=结果低8位中1的个数是偶数则置1;否则置0;进位标志CF=0;溢出标志OF=0。
- orl指令:或运算,并保存结果。比如.set CR0_PE_ON, 0x1;orl $CR0_PE_ON, %eax ;将会将%eax设置为0x1
2.main.c解析
实验中的boot loader,是一个简单版本,其唯一的工作是启动来自第一个IDE硬盘的ELF内核映像。
参考链接:main.c解析
回顾如何走到main.c的
①磁盘布局DISK LAYOUT
(boot.S和main.c)是引导程序【boot loader】,存储在磁盘的第一个扇区中。而第二个扇区则存储内核映像。该内核映像必须是ELF格式。
②启动步骤 BOOT UP STEPS
当CPU启动时,它将BIOS加载到内存中并执行它。
而后,BIOS初始化设备、中断向量表,并且读取引导设备(eg:硬盘驱动器)的第一个扇区到内存中,并跳转到这段内存。
假设这个引导加载程序【boot loader 】存储在硬盘的第一个扇区中,则这段内存中的代码接管控制权。首先控制权在boot.S中——设置保护模式,建立栈顶,从而可以运行C代码,然后调用bootmain()。此后main.c中的bootmain()接管控制权,读入内核并跳转到它。
//解读顺序:waitdisk->readsect->readseg->bootmain
#include <inc/elf.h>
#include <inc/x86.h>
#define SECTSIZE 512 //设置扇区大小512字节
//将内核加载到内存的起始地址
#define ELFHDR ((struct Elf *)0x10000) // scratch space
void readsect(void *, uint32_t);
void readseg(uint32_t, uint32_t, uint32_t);
//boot.S后跳转到bootmain,bootmain接管控制权以后,读取kernel到内存并跳转到kernel执行
void bootmain(void) {
struct Proghdr *ph, *eph;//定义了两个程序头表项指针
// read 1st page off disk 从磁盘上的第一个扇区偏移0处,读取第一页(4KB)到ELFHDR地址处
readseg((uint32_t)ELFHDR, SECTSIZE * 8, 0);
// is this a valid ELF? 通过ELF魔数确认ELF有效/合法
if (ELFHDR->e_magic != ELF_MAGIC) goto bad;
//魔数(Magic Number)用于标识此文件类型,ELF文件:其值一般为0x7f,’E’,’L’,’F’。
// load each program segment (ignores ph flags) 读取各个段
//计算各个读取的页中,放置程序头部表program header table的起始地址
//【ELFHDR->e_phoff为program header table的偏移量】
ph = (struct Proghdr *)((uint8_t *)ELFHDR + ELFHDR->e_phoff);
eph = ph + ELFHDR->e_phnum; // 程序头部表的结束地址【总表项数目】
//读取ELF内核文件的各个段
for (; ph < eph; ph++)
// p_pa is the load address of this segment (as well
// as the physical address)
// p_pa是加载地址也是物理地址【关闭了分页机制】
// p_memsz 给出段在内存映像中占用的字节数。
// p_offset 给出从文件头到该段第一个字节的偏移。
readseg(ph->p_pa, ph->p_memsz, ph->p_offset);
// call the entry point from the ELF header 从ELF头调用程序入口,执行内核
//【e_entry保存了程序入口的虚拟地址】
// note: does not return!【永远不会返回】
((void (*)(void))(ELFHDR->e_entry))();
bad:
// stops simulation and breaks into the debug console
outw(0x8A00, 0x8A00);
outw(0x8A00, 0x8E00);
while (1) /* do nothing */;
}
// Read 'count' bytes at 'offset' from kernel into physical address 'pa'.
// 从ELF内核文件偏移offset处读取count个字节到物理地址pa处
// Might copy more than asked 由于扇区对齐,可能会读取超过count个字节
void readseg(uint32_t pa, uint32_t count, uint32_t offset) {
//offset是相对第一个扇区起始地址的偏移
uint32_t end_pa;
end_pa = pa + count; // 结束物理地址
// round down to sector boundary 首地址对齐到扇区
pa &= ~(SECTSIZE - 1);
// translate from bytes to sectors, and kernel starts at sector 1
offset =
(offset / SECTSIZE) + 1; // 算出扇区数.将相对于ELF文件头的偏移量转换为扇区。
//注意内核扇区从1开始(0为引导扇区),因此默认读取从1扇区开始offset
//此时,offset可以理解为当前读取的扇区号/逻辑区块编号
// If this is too slow, we could read lots of sectors at a time.
// We'd write more to memory than asked, but it doesn't matter --
// we load in increasing order.
// 在实际中往往将多个扇区一起读出以提高效率。
while (pa < end_pa) {//每次读取一个扇区
// Since we haven't enabled paging yet and we're using
// an identity segment mapping (see boot.S), we can
// use physical addresses directly. This won't be the
// case once JOS enables the MMU.
// 考虑到没有开启分页以及boot.S中使用了一一对应的映射规则,
// 加载地址和物理地址是一致的。
readsect((uint8_t *)pa, offset);
pa += SECTSIZE;
offset++;
}
}
void waitdisk(void) {
//IDE硬盘控制器的0x1F7端口读:为磁盘0状态寄存器。
//其Bit6为DRY Bit,当其置1表明磁盘上电完成,磁盘驱动器准备好了。在对于磁盘做任何操作(除了复位)之前务必要保证该Bit为1。
//其Bit7为BSY Bit,当其置1表明磁盘忙。在你向磁盘发送任何指令前务必保证该Bit为0。
// wait for disk reaady 等待磁盘准备完毕。
while ((inb(0x1F7) & 0xC0) != 0x40) /* do nothing */;
}
void readsect(void *dst, uint32_t offset) {
// wait for disk to be ready,可以操作磁盘,发送读取命令
waitdisk();
outb(0x1F2, 1); // count = 1 0x1F2 Disk 0 sector count
// Read one sector each time,对0x1F2端口写入1,表示操作1个扇区
//向0x1F3-0x1F5端口依次写入LBA的低24位;outb表示对端口写入1字节
outb(0x1F3, offset); // Disk 0 sector number (CHS Mode)
// First sector's number
outb(0x1F4, offset >> 8); // Cylinder low (CHS Mode)
outb(0x1F5, offset >> 16); // Cylinder high (CHS Mode)
// Cylinder number
//0x1F6寄存器又称Drive/Head寄存器。其低4位是LBA的高4位。
//其Bit5和Bit7一般是1。其Bit6为LBA位,当置1时表示启用LBA寻址。
//其Bit4为DRV位。用来选择驱动器,Master驱动器为0【os所在盘】,Slave驱动器为1。
//这里将0x1F6端口高4位置为1110,低四位为offset【共28bits】的28-24位
outb(0x1F6, (offset >> 24) | 0xE0); // Disk 0 drive/head
// MASK 11100000
// Drive/Head Register: bit 7 and bit 5 should be set to 1
// Bit6: 1 LBA mode, 0 CHS mode
//向0x1F7端口写入0x20:表示执行“扇区读”命令【重试retry模式】
outb(0x1F7, 0x20); // cmd 0x20 - read sectors
/*NB: 21H = read sector without retry.
使用20H之前,必须提供完整的CHS【cylinder/head/sector】
当命令完成(DRQ=DATA READY goes active)时,您可以从磁盘的数据寄存器(0x1F0端口)中读取256个字(一个字=16位)。
*/
// wait for disk to be ready,读取好数据后返回
waitdisk();
// read a sector
insl(0x1F0, dst, SECTSIZE / 4);
//insl port addr cnt指令表示:从(input)port读取cnt dwords到指定的addr(output array addr);dword表示双字,4字节。因此SECTSIZE/4 dwords=(SECTSIZE/4)*4字节=SECTSIZE字节
}
背景补充:
-
IDE接口(Integrated Drive Electronics)是把“硬盘控制器”与“盘体”集成在一起的硬盘驱动器。主板一般拥有两个IDE接口,可分别连接两条IDE数据线。而每条IDE数据线上有两个IDE接口,可分别连接两个IDE设备,这两个IDE接口,就分别是”Master”(主盘)接口和”Slave”(从盘)接口。 顾名思义,”Master”(主盘)就是系统启动首先读取并引导的盘,对于装有操作系统的硬盘来说,最好将它设置为”Master”(主盘),这样系统才能被正确引导。 同时,需要指出的是,在一条IDE线上,仅能同时拥有一个主盘,一个从盘。而不能在同条IDE线上接两个主盘,或两个从盘。
-
首先,ELF文件格式提供了两种视图,分别是链接视图【左侧弧】和执行视图【右侧弧】。
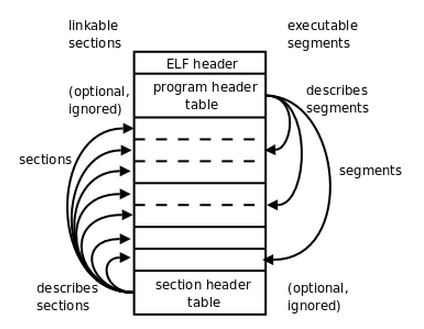
链接视图是以节(section)为单位,执行视图是以段(segment)为单位。
链接视图就是在链接时用到的视图,而执行视图则是在执行时用到的视图。
整个文件可以分为四个部分:
- ELF header: 描述整个文件的组织。
- Program Header Table: 描述文件中的各种segments,用来告诉系统如何创建进程映像的。
- sections 或者 segments:
- segments是从运行的角度来描述elf文件,sections是从链接的角度来描述elf文件,也就是说,在链接阶段,我们可以忽略program header table来处理此文件,在运行阶段可以忽略section header table来处理此程序(所以很多加固手段删除了section header table)。
- 从图中我们也可以看出,segments与sections是包含的关系,一个segment包含若干个section。
- Section Header Table: 包含了文件各个segction的属性信息,我们都将结合例子来解释。
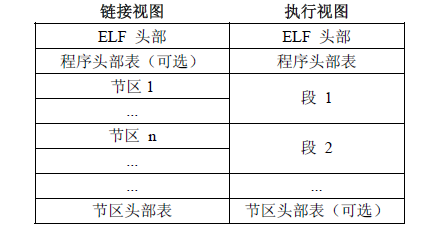
- 程序头部表(Program Header Table),如果存在的话,告诉系统如何创建进程映像。 用来构造进程映像的目标文件必须具有程序头部表,可重定位文件不需要这个表。
- 节区头部表(Section Heade Table)包含了描述文件节区的信息,每个节区在表中都有一项,每一项给出诸如节区名称、节区大小这类信息。用于链接的目标文件必须包含节区头部表,其他目标文件可以有,也可以没有这个表。
- 参考:https://blog.csdn.net/weixin_39831546/article/details/81506678
-
磁盘控制器
磁盘是由盘片构成的。每个盘片有两面或者称为表面,表面覆盖着磁性记录材料。每一个表面是由一组称为磁道的同心圆组成。每个磁道被划分为一组扇区。每个扇区包含相等数量的数据位(通常是512字节),这些数据编码在扇区上的磁性材料中。扇区之间由一些间隙分隔开,这些间隙中不存储数据位。间隙用来标识扇区的格式化位。
对于磁盘的寻址通常分为CHS和LBA两种。
- CHS即柱面(cylinder)-磁头(head)-扇区(sector)寻址。每个盘片都对应着一个磁头,每一个盘片都被划分成柱面,每一个柱面都被划分成多个段。磁盘的最小存储单元是段。早期的IBM PC架构上采用CHS进行磁盘寻址。CHS是一个三元组,包括10bit的柱面号,8bit的磁头号以及6bit的扇区号。这样CHS的最大寻址范围为2^10 × 2^8 × 2^6 × 512 = 8GB。
- 随着磁盘容量的不断扩大,CHS的8GB寻址范围已经不能满足需要,现在的磁盘普遍采用逻辑区块地址(Logical Block Adress)的方式进行寻址来进行抽象【LBA是非常单纯的一种寻址模式﹔从0开始编号来定位区块,第一区块LBA=0,第二区块LBA=1,依此类推。】。LBA是一个整数,代表磁盘上的一个逻辑区块编号,通过将这个整数转换成CHS格式来完成磁盘的具体寻址。LBA为48个bit,最大寻址范围为128PB。在本实验中,LBA按照旧的规范采用28个bit。
- ATA-1规范中定义了28位寻址模式,当成LBA或是CHS都可以。如果用CHS这28位拆成: 磁柱16位、磁头4位、扇区8位。注意CHS模式扇区是从1开始算,所以在这个规范中扇区数【8位表示】最多只有255个,最大扇区编号为255(0xFF)。2002年ATA-6规范采用48位LBA,同样以每扇区512位组计算容量上限可达128 Petabytes。
-
IDE硬盘控制器(IDE Hard Drive Controller)的0x1F7端口:读磁盘状态寄存器。
- 其Bit6为DRY Bit,当其置1表明磁盘上电完成,磁盘驱动器准备好了。在对于磁盘做任何操作(除了复位)之前务必要保证该Bit为1。
- 其Bit7为BSY Bit,当其置1表明磁盘忙。在你向磁盘发送任何指令前务必保证该Bit为0。
-
0x1F6寄存器又称Drive/Head寄存器。其低4位是LBA的高4位。其Bit5和Bit7一般是1。其Bit6为LBA位,当置1时表示启用LBA寻址。其Bit4为DRV位。用来选择驱动器,Master驱动器为0,Slave驱动器为1。这里将高4位置为1110B
-
通过IDE硬盘控制器读取扇区需要如下的步骤:
- 向0x1F2端口写入待操作的扇区数目;
- 向0x1F3-0x1F5端口依次写入LBA的低24位;
- 向0x1F6端口的低4位写入LBA的高4位,向0x1F6端口的高4位写入驱动器地址;
- 向0x1F7端口写入读命令0x20。
注:在使用读命令0x20之前需要完整的设置柱面/磁头/扇区。当这个命令完成,你可以从磁盘的数据寄存器(0x1F0端口)读取256个字(16Bits)。
3.Loading the Kernel【讲的有点乱,可跳过】
使用objdump -h obj/kern/kernel查看ELF文件的节sections。
The C definitions for these ELF headers are in inc/elf.h.
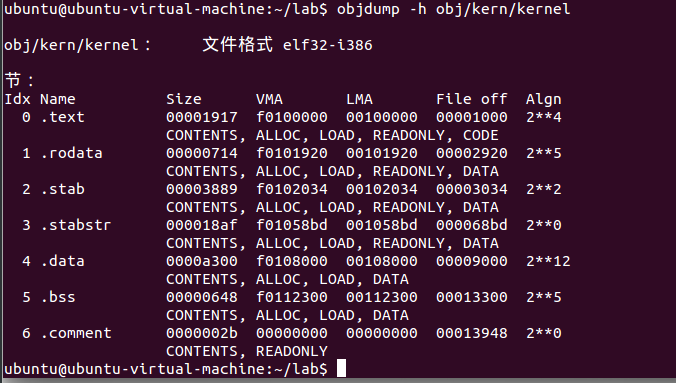
查看到.text/.rodata/.stab/.stabstr/.data/.bss/.comment,其中:
- STAB:调试信息的传统格式被称为 STAB(符号表)。STAB 信息保存在ELF文件的 .stab 和 .stabstr 部分。
- 调试信息通常包含在程序的可执行文件中,但不会被程序加载器加载到内存中
- .conment为注释信息段
.text部分的“VMA”(链接地址or link address)和“LMA”(加载地址or load address)。段的加载地址是应该将该段加载到内存中的内存地址。
The load address of a section is the memory address at which that section should be loaded into memory.
The link address of a section is the memory address from which the section expects to execute.
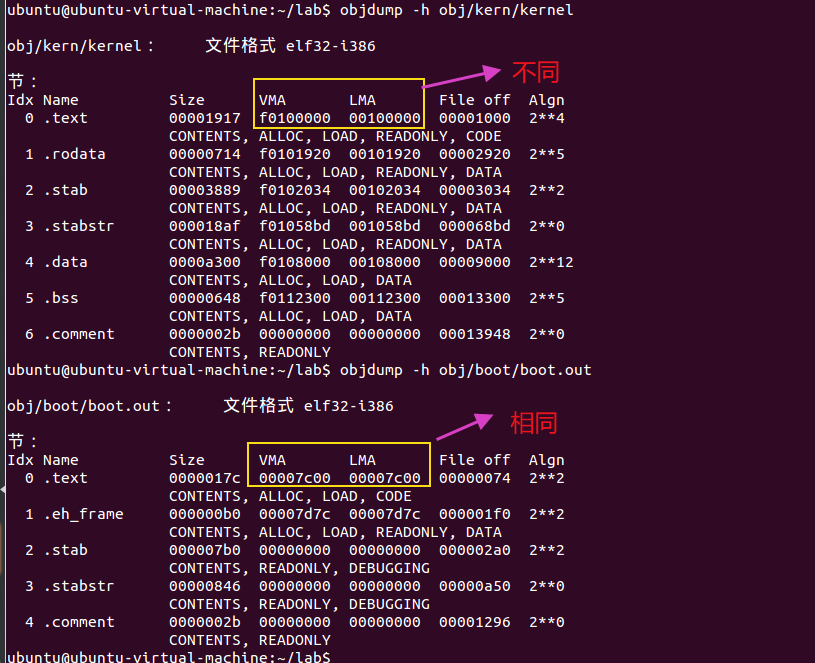
boot loader使用 ELF程序头(Program Headers) 确定如何加载段。程序头指明ELF中哪部分加载进内存【LOAD标识】和其所在的地址。
在运行boot loader时,boot loader中的链接地址(虚拟地址)和加载地址(物理地址)是一样的。但是当进入到内核程序后,这两种地址就不再相同了。
操作系统内核程序在虚拟地址空间通常会被链接到一个非常高的虚拟地址空间处,比如0xf0100000,目的就是能够让处理器的虚拟地址空间的低地址部分能够被用户利用来进行编程。
objdump -x obj/kern/kernel查看程序头 program headers
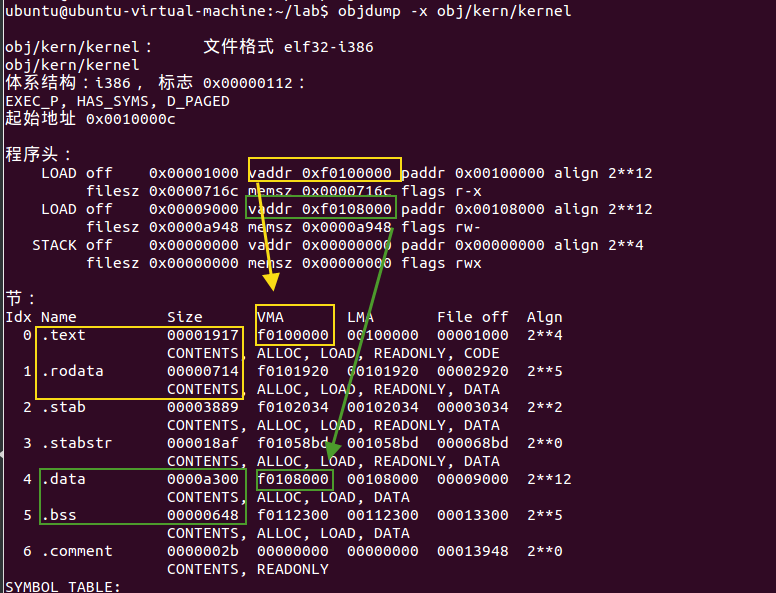
需要加载到内存中的ELF对象的区域是标记为“LOAD”的区域。给出了每个程序头的其他信息,例如虚拟地址(“vaddr”),物理地址(“paddr”)和加载区域的大小(“memsz”和“filesz”)。
BIOS把引导程序boot loader加载到内存地址0x7c00,这也就是引导扇区的加载地址和链接地址。在 boot/Makefrag 中,是通过传 -Ttext 0x7C00 这个参数给链接程序设置了链接地址,因此链接程序在生成的代码中产生正确的内存地址。
Exercise 5
修改 boot/Makefrag 让其加载地址出错。查看这个文件
$(OBJDIR)/boot/boot: $(BOOT_OBJS)
@echo + ld boot/boot
$(V)$(LD) $(LDFLAGS) -N -e start -Ttext 0x7C00 -o $@.out $^ #这里有-Ttext指定了boot loader的加载地址
$(V)$(OBJDUMP) -S $@.out >$@.asm
$(V)$(OBJCOPY) -S -O binary -j .text $@.out $@
$(V)perl boot/sign.pl $(OBJDIR)/boot/boot
可以发现 -Ttext 后面的参数就是入口地址。
如果把这个值修改为0x8C00,保存后回到lab1文件夹下进行make clean & make,查看 obj/boot/boot.asm 会发现
Disassembly of section .text:
00008c00 <start>: #起始地址原来是0x7c00
.set CR0_PE_ON, 0x1 # protected mode enable flag
.globl start
start:
.code16 # Assemble for 16-bit mode
cli # Disable interrupts
8c00: fa cli
cld # String operations increment
8c01: fc cld
可以发现起始地址从原来的 00007c00 变为 00008c00。
虽然此时在0x7c00处打断点然后运行时正常的,但是继续si以后会在 [ 0:7c2d] => 0x7c2d: ljmp $0x8,$0x8c32 出循环,同时qemu端口出现了错误。因为不能ljmp到$0x7c32而是调到了$0x8c32,所以无法执行正确的指令。查看 boot.asm 可以知道上面这个指令是 ljmp $PROT_MODE_CSEG, $protcseg,是为了进入32位模式的。
除了段信息,ELF头中的e_entry字段也很重要。这个字段保存了程序入口点(entry point)的链接地址,也就是程序执行的text字段中的内存地址。使用一下命令查看objdump -f obj/kern/kernel
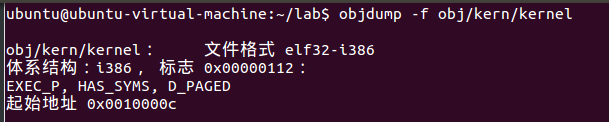
补充
kernel在编译的时候,采用的虚拟地址是0xF0100000【VMA,链接地址】。这是是在链接定义文件 kern/kernel.ld指定的链接的起始地址。
root@debug:~/6.828/lab# cat kern/kernel.ld
/* Link the kernel at this address: "." means the current address */
. = 0xF0100000;
/* AT(...) gives the load address of this section, which tells
the boot loader where to load the kernel in physical memory */
.text : AT(0x100000) {
*(.text .stub .text.* .gnu.linkonce.t.*)
}
kernel在加载到的物理地址【LMA、加载地址】是
#define ELFHDR ((struct Elf *) 0x10000)
这两者之间的映射关系与用户的用应程序没有什么实质上的差异。也是通过页表来实现的。【因此boot loader执行的时候还没有页表的设置,因此链接地址=加载地址。而此后为kernel设置了页表,则两者可以不同。从这点上看,】
kern/entrypgdir.c
完成了内核页表的设置。
__attribute__((__aligned__(PGSIZE)))
pde_t entry_pgdir[NPDENTRIES] = {
// Map VA's [0, 4MB) to PA's [0, 4MB)
[0]
= ((uintptr_t)entry_pgtable - KERNBASE) + PTE_P,
// Map VA's [KERNBASE, KERNBASE+4MB) to PA's [0, 4MB)
[KERNBASE>>PDXSHIFT]
= ((uintptr_t)entry_pgtable - KERNBASE) + PTE_P + PTE_W
};
这里把物理起始地址4MB以及0xF0000000这里的4MB都映射到物理地址的[0, 4MB)
从这里我们可以知道物理内存中:
【extended mem】
0x100000:kernel【extended mem】
0xfe05b:BIOS
【硬件/固件】
0x7c00:boot loader【low mem】
【low mem】
The Kernel
我们现在将开始更详细地研究最小的JOS内核。与引导加载程序一样,内核从一些汇编语言代码开始,这些代码的运行可以初始一些东西,使后面的C代码能执行。
使用虚拟内存来解决位置依赖问题:
当您检查上面的boot loader的链接和加载地址时,它们完全匹配,但内核的链接地址(由objdump -h打印)与其加载地址之间存在(相当大)差异。(链接内核比引导加载程序更复杂。链接和加载地址位于kern / kernel.ld的顶部。)
操作系统内核通常喜欢链接并在非常高的**虚拟**地址(例如0xf0100000)下运行,以便留下处理器虚拟地址空间的下半部分供用户执行程序使用。【在下一个实验中能更清晰的看到原因。】
许多机器物理内存没有那么大,因此在地址0xf0100000处没有任何physical memory,因此我们无法指望能够在那里存储内核。
相反,我们将使用处理器的内存管理硬件【MMU】将虚拟地址0xf0100000(内核代码期望运行的链接地址)映射到物理地址0x00100000(引导加载程序将内核加载到物理内存中,加载地址)。这样,虽然内核的虚拟地址足够高,为用户进程留出足够的地址空间,但它被加载到PC的RAM中1MB位置的物理内存中,就在BIOS ROM上方。这种方法要求PC至少有几兆字节的物理内存(因此物理地址0x00100000可以工作),这对于1990年以后建立的任何PC都适用。
事实上,在下一个实验中,我们将把物理地址0x00000000到0x0fffffff的整个底部256MB的物理地址空间分别映射到虚拟地址0xf0000000到0xffffffff【因此以前认识的linux进程布局内核都在高地址,实际是虚拟空间布局】。现在应该看到为什么JOS只能使用前256MB的物理内存【为了能把它完整映射到虚拟地址空间的顶部】。
kernel的物理地址和虚拟地址转化,涉及了分页机制以及页表。 在kern/entry.S设置CR0_PG标记之前,内存引用被当做线性/物理地址。实际上,由于在boot/boot.S设置了线性地址到物理地址的一致映射,所以线性地址在这里可以等同于物理地址。 当CR0_PG标记被设置了之后,所有的内存引用都被当作虚拟地址。虚拟地址通过虚拟内存硬件被翻译成物理地址。
现在,我们只需映射前4MB的物理内存,这足以启动并运行内核。我们通过纯粹手写kern/entrypgdir.c,静态初始化配置页面目录和页表来完成虚拟地址到物理地址的映射。
kern/entrypgdir.c
- 将0xf0000000到0xf0400000的虚拟地址翻译为物理地址的0x000000到0x400000
- 也将0x00000000到0x00400000的虚拟地址翻译为物理地址的0x00000000到0x00400000。【这一段的固定映射永远不会被改变】
- 引用这些地址范围以外的虚拟地址将会抛出缺页的异常。但是还没有为该异常设置中断处理程序。这会导致QEMU转储机器状态并退出。【如果不使用QEMU的6.828补丁版本,则会无休止地重启】
exercise 7
使用QEMU和GDB跟踪到JOS内核并停在movl%eax,%cr0。检查内存为0x00100000和0xf0100000。现在,使用stepi GDB命令单步执行该指令。再次检查内存为0x00100000和0xf0100000。
查看/lab/kern/entry.S
#include <inc/mmu.h>
#include <inc/memlayout.h>
# Shift Right Logical
#define SRL(val, shamt) (((val) >> (shamt)) & ~(-1 << (32 - (shamt))))
###################################################################
# The kernel (this code) is linked at address ~(KERNBASE + 1 Meg),
# but the bootloader loads it at address ~1 Meg.
#
# RELOC(x) maps a symbol x from its link address to its actual
# location in physical memory (its load address).
###################################################################
#RELOC做了链接地址到实际物理地址的转换
#define RELOC(x) ((x) - KERNBASE)
#define MULTIBOOT_HEADER_MAGIC (0x1BADB002)
#define MULTIBOOT_HEADER_FLAGS (0)
#define CHECKSUM (-(MULTIBOOT_HEADER_MAGIC + MULTIBOOT_HEADER_FLAGS))
###################################################################
# entry point
###################################################################
.text
# The Multiboot header
.align 4
.long MULTIBOOT_HEADER_MAGIC
.long MULTIBOOT_HEADER_FLAGS
.long CHECKSUM
# '_start' specifies the ELF entry point. Since we haven't set up
# virtual memory when the bootloader enters this code, we need the
# bootloader to jump to the *physical* address of the entry point.
#__start是ELF入口点,此前通过objdump -f obj/kern/kernel查看过
#即ELF头中的e_entry字段。这个字段保存了程序入口点(entry point)的链接地址,也就是程序执行的text字段中的内存地址。
#起始地址是0x0010000c
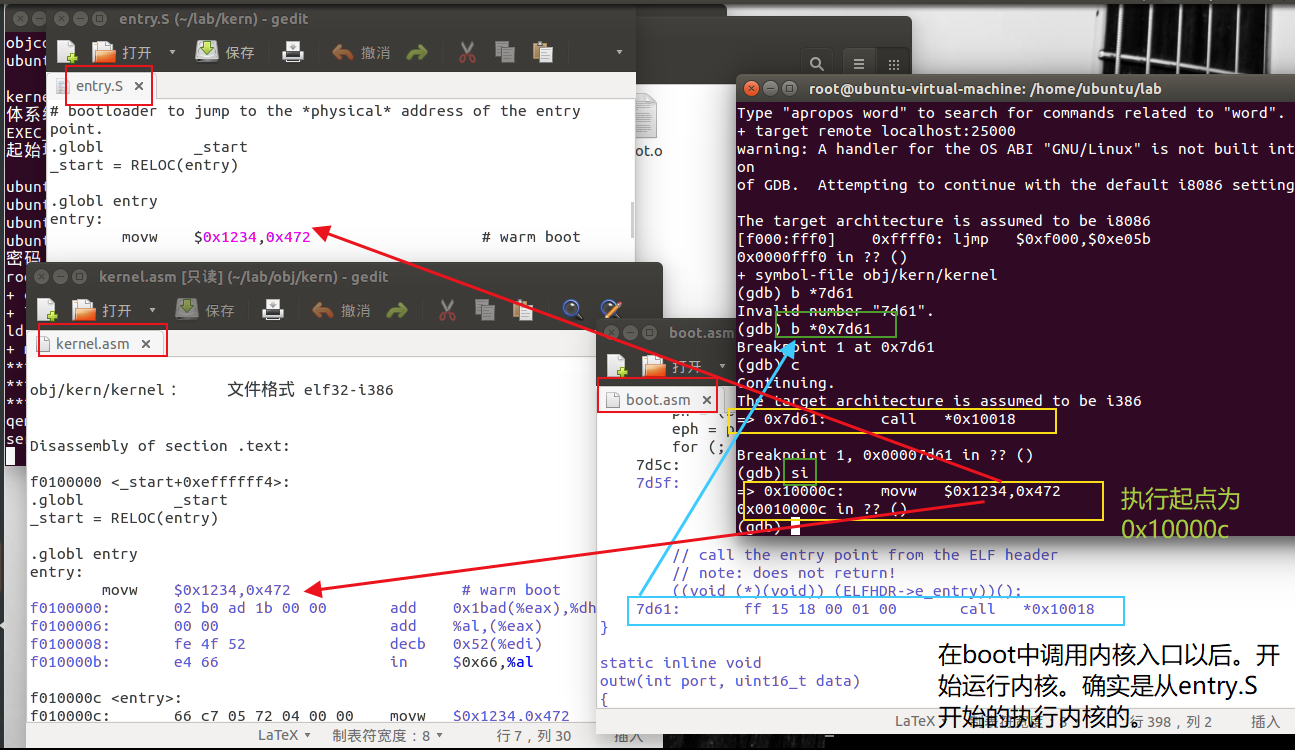
#当bootloader的main.c通过((void (*)(void))(ELFHDR->e_entry))();【跳转到入口点】进入这个kernel代码时,我们还没有开启虚拟地址,因此我们需要使用物理地址来跳转到这个入口点【因此boot.asm中的这个跳转是写死的物理地址,由kern/kernel.ld链接脚本指示】
.globl _start
_start = RELOC(entry)
.globl entry
entry:
movw $0x1234,0x472 # warm boot
# We haven't set up virtual memory yet, so we're running from
# the physical address the boot loader loaded the kernel at: 1MB
# (plus a few bytes). However, the C code is linked to run at
# KERNBASE+1MB. Hence, we set up a trivial page directory that
# translates virtual addresses [KERNBASE, KERNBASE+4MB) to
# physical addresses [0, 4MB). This 4MB region will be
# sufficient until we set up our real page table in mem_init
# in lab 2.
/*
我们还没有设置虚拟内存,因此我们从引导加载程序加载内核的物理地址开始运行:1MB(加上几个字节)。但是,C代码链接到KERNBASE + 1MB运行。因此,我们设置了一个简单的页面目录,将虚拟地址[KERNBASE,KERNBASE + 4MB]转换为物理地址[0,4MB]。在我们在实验2中的mem_init中设置真实页面表之前,这个4MB区域就足够了。
*/
# Load the physical address of entry_pgdir into cr3.
# entry_pgdir is defined in entrypgdir.c.
#这里把页表加载到cr3寄存器。注意加载的时候,由于页表还没有打开,用的是物理地址。
movl $(RELOC(entry_pgdir)), %eax
movl %eax, %cr3
# Turn on paging.
movl %cr0, %eax
orl $(CR0_PE|CR0_PG|CR0_WP), %eax #和之前保护模式设置相似,只是设置了不同的bit位
movl %eax, %cr0 #这里设置cr0寄存器的bit位,开启了虚拟地址-物理地址映射【页表】
# Now paging is enabled, but we're still running at a low EIP
# (why is this okay?). Jump up above KERNBASE before entering
# C code.
mov $relocated, %eax
jmp *%eax
relocated:
查看 kern/entry.S 发现 _start 是ELF入口点,上述提到了入口点是 0x0010000c. 所以在0x0010000c处打断点b *0x0010000c。
接着输入 c 使程序运行到断点处。使用 x/4i 来查看后四条指令,发现 0x00100000 和 0xf0100000 不同。
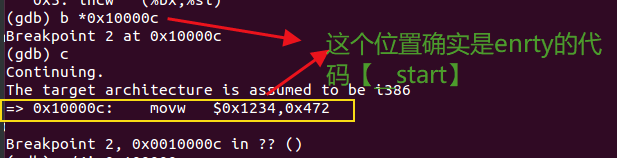
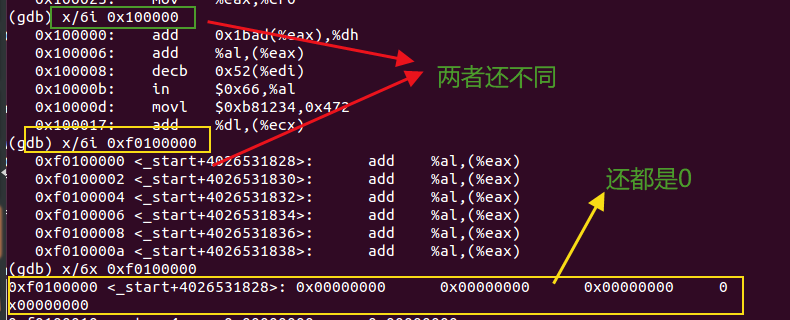
在执行完movl %eax, %cr0以后【6次si】,看到0x00100000 和 0xf0100000 处内容相同。
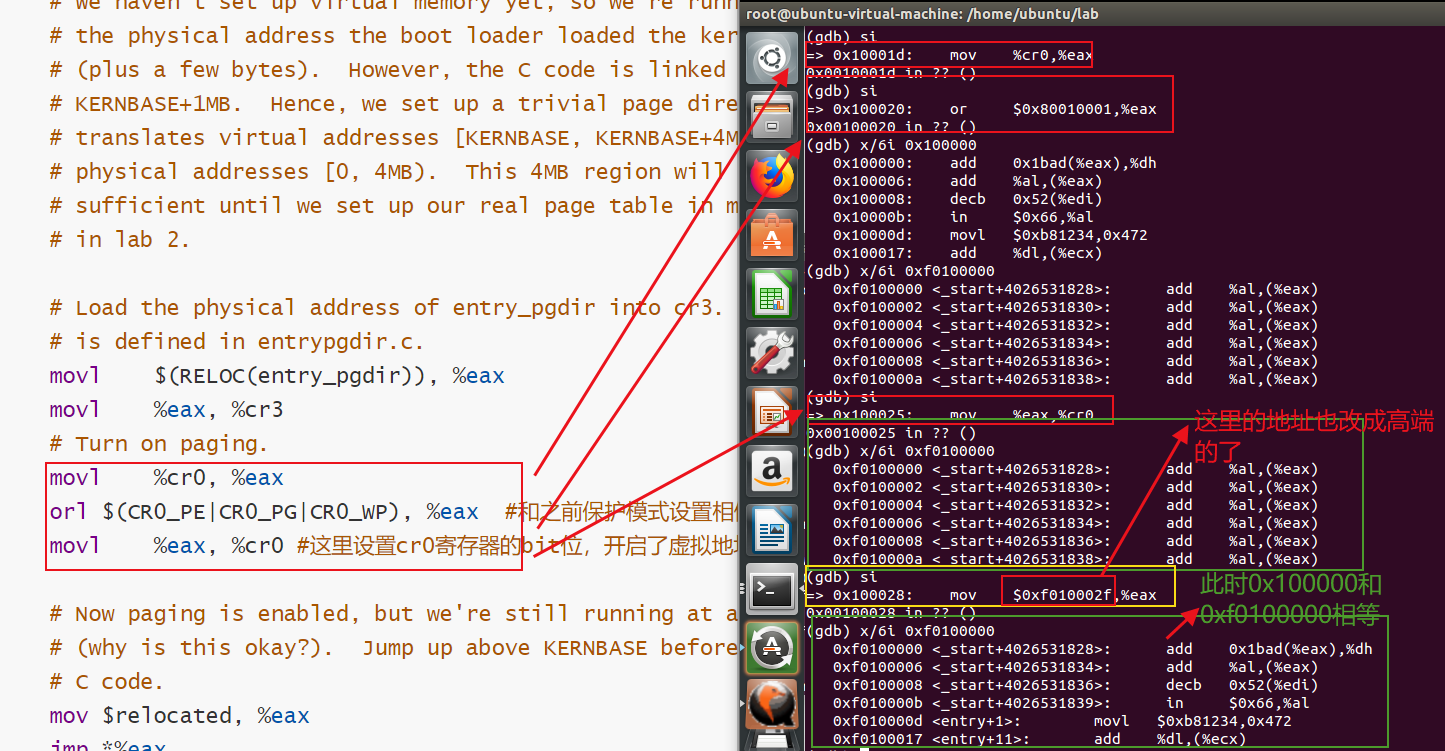
综上,在movl %eax, %cr0指令(启动页表)之前,0x00100000处的内存不为空,是内核代码,而0xf0100000处的内存全为0。
当stepi之后【执行了movl %eax, %cr0指令】,0xf0100000处的内存和0x00100000处的内存完全一样【都是内核指令】。这表明已经成功启用了页表【开启了虚拟地址到物理地址的转化】,完成了地址的映射。
注意:开启地址转换后是将0xf0000000到0xf0400000的虚拟地址翻译为物理地址的0x000000到0x400000,此时也将0x00000000到0x00400000的虚拟地址翻译为物理地址的0x000000到0x00400000。
因此x/4i <内存地址A>,是查看了虚拟地址A下的内容。但是0x000000-0x00400000和0xf0000000-0xf0400000这两段虚拟地址都指向同一段物理地址0x000000到0x00400000,因此两段内容一样,并且0x000000-0x00400000这一段没有改变。
当开启分页之后,立马会进行相应的跳转。这里主要是因为后面会开始执行C语言的函数了。必须设置好相应的CS:IP, esp, ebp, ss等寄存器。
- CPU跑在物理地址空间上,而不是虚拟地址空间上。(尽管CS:IP会被翻译到真正的地址。)
- C语言认为是自己是跑在虚拟地址空间。
通过jmp【到映射好的内核虚拟地址】,可以使得两者正常化。CPU在取指,寻址的时候,就会在有页映射的地址空间里面了。环境设置好,就可以开始跳转到C语言里面了。
注释 movl %eax, %cr0 后,make clean 之后重新编译,再运行。只要后面有涉及到寻址的地方,就会立马出错【因为开启页表后,会使用虚拟地址。但是这里却注释了开启页表的指令,因此将虚拟地址当做物理地址来使用,万一真给了qemu那么大的物理地址空间,那边物理地址也没有内容】。
一步步 si 后出现了问题。

在0x10002a处的jmp指令,要跳到 0xf010002c 处【jmp $relocated】, 然而因为没有分页管理,不会进行虚拟地址映射到物理地址的转化【所以0xf01002c实际是非法地址,会产生缺页异常】,再另一个窗口可以看到错误信息:访问地址超出内存。

1.Formatted Printing to the Console
在OS内核中,我们必须自己实现所有I/O【不然qemu加载JOS内核、栈的过程,就没法打印提示了】。没有c中的printf给你用了。
通读kern/printf.c,lib/printfmt.c和kern/console.c,确保了解它们之间的关系。在后面的实验中将清楚为什么printfmt.c位于单独的lib目录中。
关系分析:kern/printf.c里的 vcprintf, cprintf 都调用 lib/printfmt.c 的 vprintfmt。kern/printf.c里的 putch调用 kern/console.c 的 cputchar。lib/printfmt.c 里也有 putch。
//putch位于printf.c
static void
putch(int ch, int *cnt)
{
cputchar(ch); //位于console.c
*cnt++;
}
所以 kern/printf.c 和 lib/printfmt.c 依赖 kern/console.c。
kern/printf.c 基于 lib/printfmt.c 。
exercise 8
实验省略了一小段代码——使用“%o”形式的模式打印八进制数所需的代码。查找并填写此代码片段。
console.c源码
console.c里面主要是对串口、VGA【视频图形阵列】、控制台、键盘,硬件方面的操作。
- VGA控制器保留了一块内存(0x8b000~0x8bfa0)作为屏幕上字符显示的缓冲区,若要改变屏幕上字符的显示,只需要修改这块内存就好了。
- 参考:console.c大致构架
首先先看看printf.c和printfmt.c中 putch 里调用的 cputchar。
// 'High'-level console I/O. Used by readline and cprintf.
void
cputchar(int c)
{
cons_putc(c);
}
// output a character to the console
static void
cons_putc(int c)
{
serial_putc(c);
lpt_putc(c);
cga_putc(c);
}
cputchar调用的是 cons_putc, 所以 cons_putc 才是关键。 cons_putc 的功能是输出一个字符到控制台。cons_putc 又是由 serial_putc, lpt_putc 和 cga_putc 组成。
因此,要先来看 serial_putc。
#define COM1 0x3F8
#define COM_LSR 5 // In: Line Status Register
#define COM_LSR_TXRDY 0x20 // Transmit buffer avail
#define COM_TX 0 // Out: Transmit buffer (DLAB=0)
static void
serial_putc(int c)
{
int i;
for (i = 0;
!(inb(COM1 + COM_LSR) & COM_LSR_TXRDY) && i < 12800;
i++)
delay();//调用延时函数用ind(0x84)实现
outb(COM1 + COM_TX, c);
}
它控制的是端口0x3F8,inb 读取的是 COM1 + COM_LSR = 0x3FD 端口,outb 输出到了 COM1 + COM_TX = 0x3F8。
详细端口信息查看这个PORTS.LST。

在 inb(COM1 + COM_LSR) 之后, 有 & COM_LSR_TXRDY 这个操作。 !(inb(COM1 + COM_LSR) & COM_LSR_TXRDY) 其实是为了查看读入的数据的第6位,也就是 PORTS.LST 中 03FD 中提到的 bit 5 是否为1。 如果为1,上面的语句结果就是0,停止for循环。这个 bit 5 是判断发送数据缓冲寄存器是否为空。

outb 是将端口 0x3F8 的内容输出到 c。当 0x3F8 被写入数据,它作为发送数据缓冲寄存器,数据是要发给串口。
所以serial_putc是为了把一个字符输出到串口。
再来看 lpt_putc。LPT其实是Parallel_port并行端口
/***** Parallel port output code *****/
// For information on PC parallel port programming, see the class References
// page.
static void
lpt_putc(int c)
{
int i;
for (i = 0; !(inb(0x378+1) & 0x80) && i < 12800; i++)
delay();
outb(0x378+0, c);
outb(0x378+2, 0x08|0x04|0x01);
outb(0x378+2, 0x08);
}
0378-037A是parallel printer port, same as 0278 and 03BC
0x379端口的作用类似于0x3BD,是status port。bit7表示端口是否繁忙。因此端口忙碌的时候delay()
0x378端口是数据寄存器,类似于03BC w data port
0x37A端口的作用类似于0x3BE,是控制寄存器。设置
03BE r/w control port
bit 7-5 reserved
bit 4 = 1 enable IRQ
bit 3 = 1 select printer
bit 2 = 0 initialize printer
bit 1 = 1 automatic line feed
bit 0 = 1 strobe
lpt_putc将字符给并口设备。
最后一个是 cga_putc。根据函数名知道,是输出一个字符到CGA设备【Color Graphics Adapter,IBM的第一款图形显示卡】
/* 以下宏定义位于console.h
#define MONO_BASE 0x3B4
#define MONO_BUF 0xB0000
#define CGA_BASE 0x3D4
#define CGA_BUF 0xB8000
#define CRT_ROWS 25
#define CRT_COLS 80
#define CRT_SIZE (CRT_ROWS * CRT_COLS) //认为屏幕是25行*80列大小的
*/
static void
cga_putc(int c)
{
// if no attribute given, then use black on white
if (!(c & ~0xFF)) //输出的字符应当在0~255
c |= 0x0700;
//crt_pos存储当前缓冲区最后一个存储字符的index,crt_buf为缓冲区数组
//第8行当c为'\b'时,代表是输入了退格,所以此时要把缓冲区最后一个字节的指针减一,相当于丢弃当前最后一个输入的字符。
//当c为'\t'时,我要输出5个空格给缓冲区。
//如果不是特殊字符,那么就把字符的内容直接输入到缓冲区。
switch (c & 0xff) {
case '\b':
if (crt_pos > 0) {
crt_pos--;
crt_buf[crt_pos] = (c & ~0xff) | ' ';
}
break;
case '\n':
crt_pos += CRT_COLS;
/* fallthru */
case '\r':
crt_pos -= (crt_pos % CRT_COLS);
break;
case '\t':
cons_putc(' ');
cons_putc(' ');
cons_putc(' ');
cons_putc(' ');
cons_putc(' ');
break;
default:
crt_buf[crt_pos++] = c; /* write the character */
break;
}
// What is the purpose of this?
//这段代码的作用就是在当写满一个屏幕的时候,把整个已输出字符串往上滚动一行。
if (crt_pos >= CRT_SIZE) {
int i;
//把从第1~n行的内容复制到0~(n-1)行【但是第n行未变化】
//把crt_buf + CRT_COLS地址复制到crt_buf地址,复制的大小(CRT_SIZE - CRT_COLS) * sizeof(uint16_t),少一行的size
//通过这一行代码完成了整个屏幕向上移动一行的操作。
memmove(crt_buf, crt_buf + CRT_COLS, (CRT_SIZE - CRT_COLS) * sizeof(uint16_t));
//输出一行CRT_COLS大小的空格,即把刚刚未变化的n行清空
for (i = CRT_SIZE - CRT_COLS; i < CRT_SIZE; i++)
crt_buf[i] = 0x0700 | ' ';
//清空了最后一行,crt_pos同步减少
crt_pos -= CRT_COLS;
}
/* move that little blinky thing */
//addr_6845在cga_init初始化,初始化为MONO_BASE/0x3B4或CGA_BASE/0x3D4【cga_init函数的功能就是选定特定的屏幕。比如vga, cga等。】
//MDA CRT index register(EGA/VGA)或CRT (6845) index register(EGA/VGA)
//这寄存器选择了0x3B5端口作为CGA设备数据寄存器,设置了光标的水平、垂直的位置等
//总之能操作输出到显卡(显示屏)
outb(addr_6845, 14);
outb(addr_6845 + 1, crt_pos >> 8);
outb(addr_6845, 15);
outb(addr_6845 + 1, crt_pos);
}
首先 !(c & ~0xFF) 是否在 0 ~ 255 之前。\b很容易理解,就是退格键【delete一个字符】,让缓冲区 crt_buf 的下标 crt_pos 减1。其他的同理,case都是格式操作。default就是往缓冲区里写入字符c。之后就是当缓存超过CRT_SIZE,就是用 memmove复制内存内容。
最后四句代码是将缓冲区的内容输出到显示屏。
综上:cputchar就是把一个字符输出到显示屏控制台
https://www.jianshu.com/p/1782e14a0766
printffmt.c源码
printf.c中使用了printffmt中很多函数。因此现在解析printffmt.c源码。
这是简化的原始的printf-style格式化输出实现,被printf.c中的printf,sprintf,fprintf等共同使用。内核和用户程序也使用此代码。
首先来看 kern/printf.c 里引用的 vprintfmt函数。
int vcprintf(const char *fmt, va_list ap)
{
int cnt = 0;
vprintfmt((void*)putch, &cnt, fmt, ap); //引用printffmt.c中的vprintffmt函数
return cnt;
}
vprintfmt(void (*putch)(int, void*), void *putdat, const char *fmt, va_list ap)
先说一下它的四个输入参数:
void (*putch)(int, void*)函数指针,putch间接调用cputchar,向控制台输出一个字符- void *putdat
- 在vcprintf里传入的参数putdat,是cnt的地址【&cnt】,cnt是用来做计数器的。
- 最终会return cnt;【返回已经输出的字符个数】
- 回顾可知,以前用printf的返回值,是输出的字符个数。
- 因此每调用一次putch输出一个字符,*cnt++
- const char *fmt 格式化字符串
- va_list ap 多个输入参数【下述具体分析】
回到正题:
实现%o
原来由于三个putch X,因此输出的是XXX
// unsigned decimal、无符号十进制整数
//参考u的写法
case 'u':
num = getuint(&ap, lflag);
base = 10;
goto number;
// (unsigned) octal
case 'o':
/* Replace this with your code.
putch('X', putdat);
putch('X', putdat);
putch('X', putdat);
*/
//仿照u的实现,修改为
num = getuint(&ap, lflag);
base = 8;
goto number;
break;
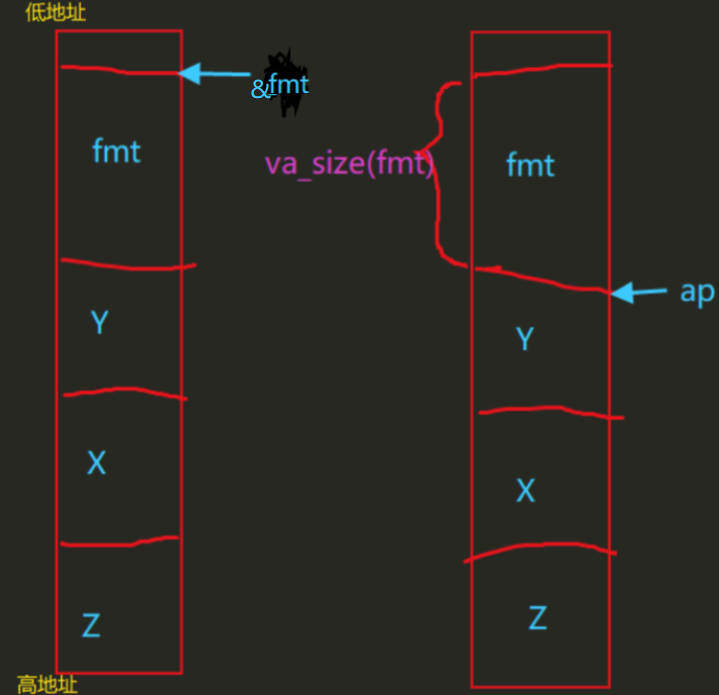
Question 3
fmt指向了格式化字符串”x %d, y %x, z %d\n” ap指向了局部变量并且初始值为1
//单步跟踪以下代码的执行:
int x = 1,y = 3,z = 4;
cprintf(“x%d,y%x,z%d \ n”,x,y,z);
//在调用cprintf()时,fmt指向什么? ap指向什么?
仔细读一下cprintf函数【位于printf.c中】代码实现就可以了
// Simple implementation of cprintf console output for the kernel,
// based on printfmt() and the kernel console's cputchar().
#include <inc/types.h>
#include <inc/stdio.h>
#include <inc/stdarg.h>
static void
putch(int ch, int *cnt)
{
cputchar(ch);
*cnt++;
}
int
vcprintf(const char *fmt, va_list ap)
{
int cnt = 0;
vprintfmt((void*)putch, &cnt, fmt, ap);
return cnt;
}
int
cprintf(const char *fmt, ...)
{
va_list ap;
int cnt;
va_start(ap, fmt);
cnt = vcprintf(fmt, ap);
va_end(ap);
return cnt;
}
这里面va_list的宏位于#include <inc/stdarg.h>中:
typedef __builtin_va_list va_list;
#define va_start(ap, last) __builtin_va_start(ap, last)
#define va_arg(ap, type) __builtin_va_arg(ap, type)
#define va_end(ap) __builtin_va_end(ap)
结果发现这几个宏都是由GCC来提供了。【可以回看mit 6.828 2007版本的代码,以分析】
具体如下:
// va_list 指针定义为char *可以指向任意一个内存地址。【因为是单个字节】
typedef char * va_list;
// 类型大小,注意这里是与CPU位数=sizeof(long)对齐的作用。【32位】
//先运算(sizeof(type) + sizeof(long) - 1) / sizeof(long))
//再*sizeof(long)=*4
#define __va_size(type) \
(((sizeof(type) + sizeof(long) - 1) / sizeof(long)) * sizeof(long))
//也就是说:如果是压栈一个char,也是压入一个long。
//所以需要注意字长。也就是所以单位是以long对齐的。
//比如压入了5个char。也是需要用到2个long【在32位机器上】
// 将ap指针向高地址移动sizeof(last)距离
//其实用于cprintf中就是指示了除去format后的剩余参数从哪里开始放
#define va_start(ap, last) \
((ap) = (va_list)&(last) + __va_size(last))
// va_arg就是用来取参数的起始地址的。然后返回type类型。
// 从整个表达式等价于(*(type*)ap)返回
// 但是实际上使ap指针向高地址移动一个参数大小。
#define va_arg(ap, type) \
(*(type *)((ap) += __va_size(type), (ap) - __va_size(type)))
// 空指令,没有什么用
#define va_end(ap) ((void)0)
现在回到cprintf函数
int cprintf(const char *fmt, ...)
{
va_list ap;
int cnt;
va_start(ap, fmt);
cnt = vcprintf(fmt, ap);
va_end(ap);
return cnt;
}
一开始va_start(fmt, ap)
//va_start(fmt, ap) 作用如下
#define va_start(ap, last) \
((ap) = (va_list)&(last) + __va_size(last))
//展开就是
ap = (char *)(&fmt) + align_long(fmt);
接下来执行cnt = vcprintf(fmt, ap);,vcprintf间接调用了vprintfmt((void*)putch, &cnt, fmt, ap);【cnt在vcprintf中初始化为0,用于计数;而后返回到cprintf中赋值给cnt】
void vprintfmt(void (*putch)(int, void*), void *putdat, const char *fmt, va_list ap)
{
while (1) {
// 如果只是fmt中的一般的字符串,直接输出。fmt++【向高地址增长】
while ((ch = *(unsigned char *) fmt++) != '%') {
if (ch == '\0')
return;
putch(ch, putdat);//在putch中*putdat++
}
// 如果发现是%c等
reswitch:
// 先把%号跳掉,取出'c'
switch (ch = *(unsigned char *) fmt++) {
// ..
case 'c':
putch(va_arg(ap, int), putdat);//等价于putch((*(int*)ap),putdat)
break;
}
}
}
通过%c就知道应该从栈中取出一个参数char类型。
首先先思考(op1,op2)在c中的作用
看一个例子:
int b=3,a=5;
cout<<(a++,b-1)<<endl;
cout<<a<<" "<<b<<endl;
//结果输出
//2
//6 3
int a=5;
cout<<(a++,a-1)<<endl;
cout<<a<<endl;
//结果输出
//5
//6
因此(op1,op2)的作用是,先执行op1【真实执行】,再执行op2【暂时执行】,返回op2的值
但是实际op2中修改的内容不会对(,)之后的代码有影响。
因此对于va_arg(ap, type) 展开:
(*(type *)((ap) += __va_size(type), (ap) - __va_size(type)))
的执行结果是以ap位置没有变动的值返回【即返回*(type*)ap,但是实际实现op1,导致ap指向下一个参数。
//因此putch(va_arg(ap, int), putdat);具体实现为:
char temp = *(char*)ap;
putch(temp, putdat); // 输出到console上。
//putch(int ch, int *cnt)是以int传参的,因此进行va_arg(ap, int)而不是char
ap += align_long(char);
//执行完成之后。
+-----------------+
| |
| fmt |
| |
| |
+-----------------+
| |
| X |
| |
| |
+-----------------+ <------+ap
| |
| Y | 这个x会被%d提出来进行输出。
| |
| |
+-----------------+
| |
| Z |
| |
| |
+-----------------+
ap的作用实际上就是利用fmt里面的%依次把后面的类型提出来。然后去栈中找到参数。一个一个输出。
Question 4
运行如下代码会输出什么?
unsigned int i = 0x00646c72;
cprintf("H%x Wo%s", 57616, &i);
首先%x是输出16进制。
- 57616 = 0xE110。
- i = 0x00646c72 那么如果把i占用的4byte转换成为char[4]数组。结果就是:char str[4] = {0x72, 0x6c, 0x64, 0x00}; // = {‘r’, ‘l’, ‘d’, \0}
- 所以输出就是He110 World
Question 6
假设GCC改变了它的调用约定,以便它按声明顺序【也就是先压栈fmt再压栈X,Y,Z】在堆栈上推送参数,以便最后推送最后一个参数。你将如何更改cprintf或其接口,以便仍然可以传递可变数量的参数?
修改va_list相关宏定义就行了,加改成减,减改成加。
说一说其他%,如何进行不同进制的输出
对于%u,%o,%p进制转化时怎么做的呢?
case 'd':
num = getint(&ap, lflag);
if ((long long) num < 0) {
putch('-', putdat);
num = -(long long) num;
}
base = 10;
goto number;
// unsigned decimal
case 'u':
num = getuint(&ap, lflag);
base = 10;
goto number;
// (unsigned) octal
case 'o':
num = getuint(&ap,lflag);
base = 8;
goto number;
// pointer
case 'p':
putch('0', putdat);
putch('x', putdat);
num = (unsigned long long)
(uintptr_t) va_arg(ap, void *);
base = 16;
goto number;
// (unsigned) hexadecimal
case 'x':
num = getuint(&ap, lflag);
base = 16;
number:
printnum(putch, putdat, num, base, width, padc);
break;
以上多种进制,都走到了number,由number调用printnum输出各种进制的纯数字。
在goto number之前,把进行了类型转化getuint(&ap,lflag),输出负号或者0x这类字符,剩下纯数字
void
vprintfmt(void (*putch)(int, void*), void *putdat, const char *fmt, va_list ap)
{
//……
case 'l':
lflag++;
goto reswitch;
//……
//记录是ll,还是l,即l的个数=lflag
}
static unsigned long long
getuint(va_list *ap, int lflag)
{ //进行了类型转化,如%ld、%lld,并返回了起始地址
//虽然实际ap加了一个参数大小的偏移
//但是实际只使用了返回值,没有用ap
if (lflag >= 2)
return va_arg(*ap, unsigned long long);
else if (lflag)
return va_arg(*ap, unsigned long);
else
return va_arg(*ap, unsigned int);
}
在goto number后调用了printnum(putch, putdat, num, base, width, padc);进行数字部分的输出
通过num/base和num%base进行进制转化和分离,递归处理,先输出高位再输出低位
static void
printnum(void (*putch)(int, void*), void *putdat,
unsigned long long num, unsigned base, int width, int padc)
{
// first recursively print all preceding (more significant) digits
if (num >= base) {//如果num超过进制base,就递归输出num/base
printnum(putch, putdat, num / base, base, width - 1, padc);
} else {
// print any needed pad characters before first digit
//输出一些指定的填充字符,由width决定填充数量
//在vprintffmt中指定了padc = ' ';width=-1,默认不填充
while (--width > 0)
putch(padc, putdat);//输出填充字符
}
// then print this (the least significant) digit
//"0123456789abcdef"[num % base],就是string[i],字符串索引
putch("0123456789abcdef"[num % base], putdat); //输出num%base部分【低位】
}
2.The Stack
终于要到结尾了。
Exercise 9
这一部分是研究内核是在哪初始化堆栈【即初始化堆栈的位置】,找出堆栈存放在内存的位置。内核是如何保存一块空间给堆栈的?堆栈指针指向这块区域的哪儿?
回到kern/entry.S,通过objdump -f obj/kern/kernel可以知道二进制内核ELF文件的入口点是0x0010000c
kernel: 文件格式 elf32-i386 体系结构:i386, 标志 0x00000112: EXEC_P, HAS_SYMS, D_PAGED 起始地址 0x0010000c
因此 b *0x10000c 下断点进入kernel/entry.S【内核运行的起始点】
si 一步步执行,在 0x10002d: jmp *%eax 之后,下一条指令变为 0xf010002f
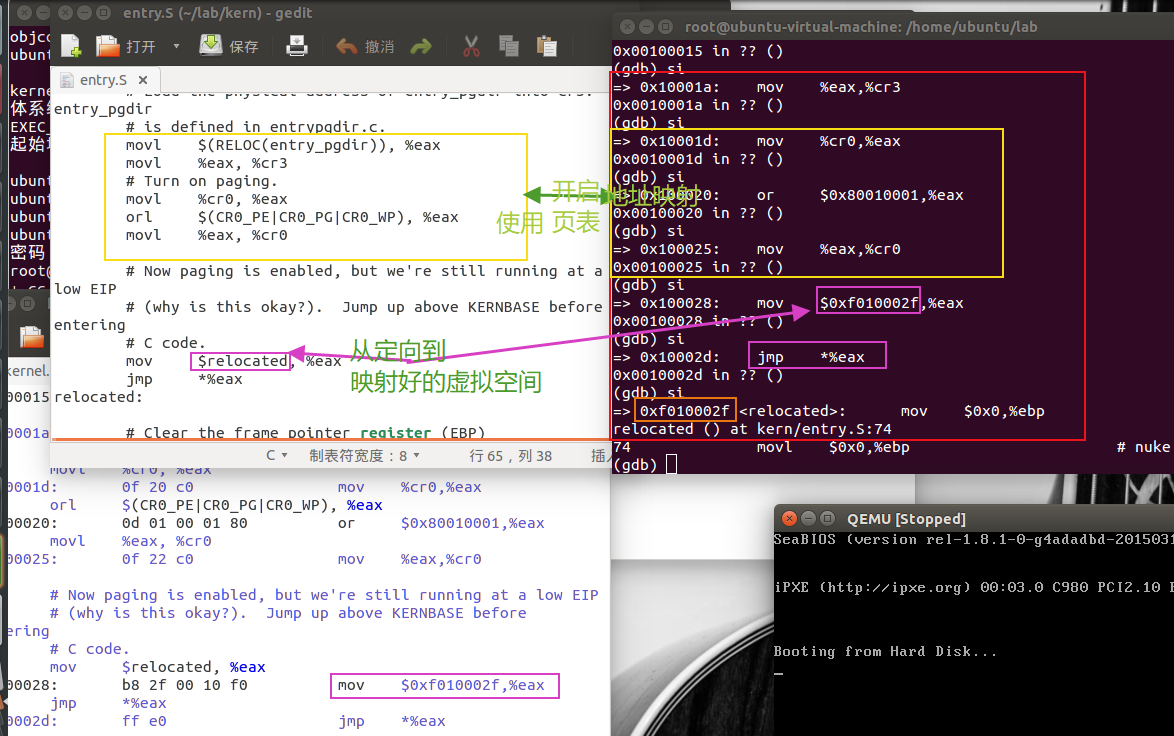
通过 gdb 发现 0xf0100034 <relocated+5>: mov $0xf0110000,%esp, 也就是说%esp,栈顶指针的值=$bootstacktop=0xf0110000。
并且可知,最早的ebp=0
也就是说内核仅通过设置esp寄存器的值为栈预留空间。
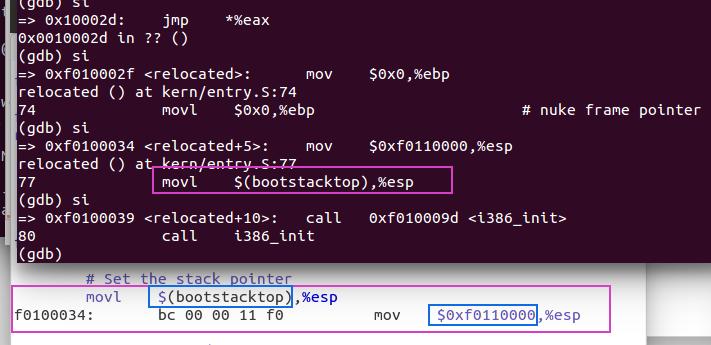
//entry.S最底部
.data
###################################################################
# boot stack
###################################################################
.p2align PGSHIFT # force page alignment
.globl bootstack
bootstack:
.space KSTKSIZE
.globl bootstacktop
bootstacktop:
KSTKSIZE 应该就是堆栈的大小,在 inc/memlayout.h 里提到了堆栈。
// All physical memory mapped at this address
#define KERNBASE 0xF0000000 //kernel映射到虚拟空间的基地址【高地址方向由kernel覆盖】
// Kernel stack.内核栈挨着内核代码,向低地址增长
#define KSTACKTOP KERNBASE
#define KSTKSIZE (8*PGSIZE) // size of a kernel stack
#define KSTKGAP (8*PGSIZE) // size of a kernel stack guard
//PGSIZE位于mmu.h #define PGSIZE 4096
因此将kernel栈放置在紧邻kernel代码的低地址方向,布局如下:
* |~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~| RW/--
* | | RW/--
* | Remapped Physical Memory | RW/--
* | 【其中有kernel在0x100000】 | RW/--
* |【这是页表从0-0x400000映射的位置】| RW/--
* KERNBASE, ----> +------------------------------+ 0xf0000000 --+
* KSTACKTOP | CPU0's Kernel Stack | RW/-- KSTKSIZE |
* | - - - - - - - - - - - - - - -| |
在设置好内核栈以后,kernel会跳转到i386_init执行【call 0xf010009d
由于内核栈已经可用,那么就可以调用c函数了,如memset或cprintf
void
i386_init(void)
{
f010009d: 55 push %ebp
f010009e: 89 e5 mov %esp,%ebp
f01000a0: 83 ec 18 sub $0x18,%esp
extern char edata[], end[];
//设置bss段全为0,用memset操作
// Before doing anything else, complete the ELF loading process.
// Clear the uninitialized global data (BSS) section of our program.
// This ensures that all static/global variables start out zero.
memset(edata, 0, end - edata);
f01000a3: b8 40 29 11 f0 mov $0xf0112940,%eax
f01000a8: 2d 00 23 11 f0 sub $0xf0112300,%eax
f01000ad: 89 44 24 08 mov %eax,0x8(%esp)
f01000b1: c7 44 24 04 00 00 00 movl $0x0,0x4(%esp)
f01000b8: 00
f01000b9: c7 04 24 00 23 11 f0 movl $0xf0112300,(%esp)
f01000c0: e8 72 13 00 00 call f0101437 <memset>
// Initialize the console.初始化控制台,包括获取光标位置,设置CGA缓存内存区等
// Can't call cprintf until after we do this!否则我们不能使用cprintf函数
cons_init();
f01000c5: e8 a5 04 00 00 call f010056f <cons_init>
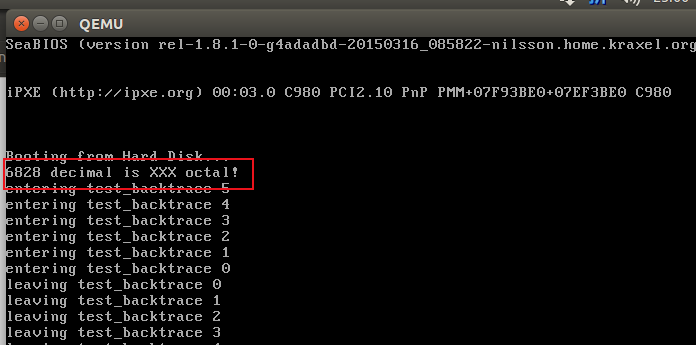
cprintf("6828 decimal is %o octal!\n", 6828);
f01000ca: c7 44 24 04 ac 1a 00 movl $0x1aac,0x4(%esp)
f01000d1: 00
f01000d2: c7 04 24 17 19 10 f0 movl $0xf0101917,(%esp)
f01000d9: e8 53 08 00 00 call f0100931 <cprintf>//在上一节解析过,这里是kernel的第一次cprintf使用,在控制台打印6828 decimal is 15254 octal!
// Test the stack backtrace function (lab 1 only)
test_backtrace(5);
f01000de: c7 04 24 05 00 00 00 movl $0x5,(%esp)
f01000e5: e8 56 ff ff ff call f0100040 <test_backtrace>
//后面还有很多……
Exercise 10.
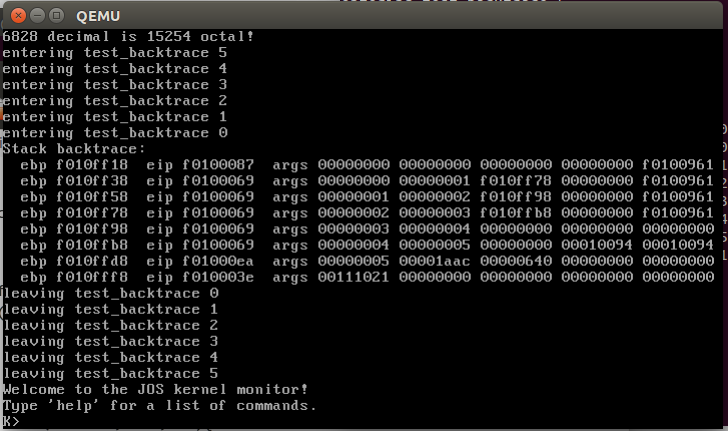
要熟悉x86上的C调用约定,在obj / kern / kernel.asm中找到test_backtrace函数的地址,在那里设置一个断点,并检查每次在内核启动后调用它时会发生什么。
这个函数完全是为了分析c函数的调用和回溯而写的,本身不是kernel必须的。
// Test the stack backtrace function (lab 1 only)
void
test_backtrace(int x)
{
cprintf("entering test_backtrace %d\n", x);
if (x > 0)
test_backtrace(x-1);
else
mon_backtrace(0, 0, 0);//这个函数只有定义,实现为空,需要自定义
cprintf("leaving test_backtrace %d\n", x);
}
(gdb) si => 0xf01000e5 <i386_init+72>: call 0xf0100040
0xf01000e5 39 test_backtrace(5); (gdb) b *0xf0100040 Breakpoint 2 at 0xf0100040: file kern/init.c, line 13. (gdb) info r ebp ebp 0xf010fff8 0xf010fff8 (gdb) info r esp esp 0xf010ffe0 0xf010ffe0 (gdb) c Continuing.
这段做pwn已经很熟悉了,不分析了。
实现mon_backtrace()
这个函数的原型已经在kern/monitor.c中【kern编译完就是kernel.out,反汇编变成kernel.asm】。可以完全用C语言完成,并且尝试使用inc / x86.h中的read_ebp()函数。还必须将此新函数挂钩到内核监视器的命令列表中,以便用户可以交互地调用它。
static inline uint32_t
read_ebp(void) //通过内嵌汇编,%0 为 =r【输出部分】即输出到ebp变量。return ebp
{
uint32_t ebp;
asm volatile("movl %%ebp,%0" : "=r" (ebp)); //%%:转义为%
return ebp;
}
mon_backtrace的实现思路是:通过read_ebp获取ebp指针,打印eip返回地址ebp+4,及其后的5个参数
int
mon_backtrace(int argc, char **argv, struct Trapframe *tf)
{
uint32_t ebp = read_ebp();//从read_ebp中确定应该使用uint32_t类型
cprintf("Stack backtrace:\n");
while((int)ebp!=0){//由于构造内核栈的时候ebp初始为0,因此ebp=0时表示已经回溯到最顶上
uint32_t eip = *((uint32_t *)ebp+1);//相当于ebp+4,32位指针++,偏移4字节
uint32_t args[5];
for(int i=2;i<=6;i++){
args[i-2]=*((uint32_t *)ebp+i);
}
cprintf(" ebp %08x eip %08x args %08x %08x %08x %08x %08x\n",ebp,eip,args[0],args[1],args[2],args[3],args[4]);
ebp=*((uint32_t *)ebp);//回溯到上一个栈帧
}
return 0;
}
补充指针
- 如果int * p =(int *)100,则(int)p + 1和(int)(p + 1)是不同的数字:第一个是101,第二个是104。
- int * p =(int *)100给指针复制为地址100
- (int)p+1,先执行(int) p 得到当前地址100,再+1=101
- (int)(p + 1),先执行p+1,由int p[i]->p[i+1],因此加了4,得到104
- 向指针添加整数时,如第二种情况,整数隐式乘以指针指向的对象的大小。
- p [i]被定义为与*(p + i)相同,指的是p指向的存储器中的第i个对象。
- &p [i]与(p + i)相同,产生p指向的存储器中第i个对象的地址
注意:虽然大多数C程序从不需要在指针和整数之间进行转换,但操作系统经常这样做。
Exercise 12
参考:
- https://www.shuzhiduo.com/A/amd024WqJg/
- https://jiyou.github.io/blog/2018/04/15/mit.6.828/jos-lab1/
修正mon_backtrace(),对每个栈帧,显示与eip对应的函数名称,源文件名和行号。并将一个backtrace命令添加到内核监视器。
在实践中,经常想知道与这些地址对应的函数名称。例如,可能想知道哪些函数可能包含导致内核崩溃的错误。
为了帮助你实现此功能,我们提供了函数debuginfo_eip()【通过插入对stab_binsearch的调用来完成debuginfo_eip的实现,以查找地址的对应行号。】,它在符号表中查找eip并返回该地址的调试信息。该函数在kern / kdebug.c中定义。
在debuginfo_eip中,__ STAB_ *来自哪里?
在文件kern / kernel.ld中查找__STAB_ *
- ld文件的解析:https://blog.csdn.net/shenjin_s/article/details/88712249
运行以下命令:
objdump -h obj / kern / kernel objdump -G obj / kern / kernel gcc -pipe -nostdinc -O2 -fno-builtin -I。 -MD -Wall -Wno-format -DJOS_KERNEL -gstabs -c -S kern / init.c
观察看看init.s里面是一堆stab结构
在boot loader调用bootmain加载内核的时候,就使用readseg读取各个段的二进制数据/代码了。其中就有符号表stab。
kernel.ld链接脚本中,.stabstr段载入了符号表stabstr:
.stabstr : {
PROVIDE(__STABSTR_BEGIN__ = .);
*(.stabstr);
PROVIDE(__STABSTR_END__ = .);
BYTE(0) /* Force the linker to allocate space
for this section */
}
STAB调试格式
调试数据格式是用来存储有关已编译计算机程序的信息的一种方式,这些信息将用于高级调试器。现代调试数据格式存储了足够多的信息来支持源代码级别的调试。
有多种调试格式可供使用。STAB、COFF、PECOFF、OMF、IEEE695 以及 DWARF 的三种版本是一些常见的选择。接下来我们将讨论如何从STAB格式中提取调试消息。
STAB
调试信息的传统格式被称为 STAB(符号表)。STAB 信息保存在 ELF 文件的 `.stab` 和 `.stabstr` 部分。
STAB 调试格式是一种记录不完整的半标准格式,用于调试 COFF 和 ELF 对象文件中的信息。调试信息是作为对象文件的符号表的一部分进行存储的,因此复杂性和范围是有限的。尽管如此,STAB 在旧的 UNIX 和兼容系统上仍然是一种常见的调试格式。
对于某些对象文件格式,调试信息被封装到统称为 STAB 指令的汇编程序指令中,这些指令分布在生成的代码中。STAB 是 a.out 和 XCOFF 对象文件格式的调试信息的本机格式。GNU 工具也可以在 COFF 和 ECOFF 对象文件格式中生成 STAB。
汇编程序创建了两个自定义部分:
- .stab,包含一组具有固定长度的结构,每个 stab 包含一个结构
- .stabstr,包含所有可变长度的字符串,这些字符串在 .stab 部分是通过 stab 引用的。
STAB 二进制数据的字节顺序取决于对象文件格式。
程序的结构
组成使用 STAB 编码的程序结构的元素包括主函数的名称、源名称和 include 文件的名称、行号、过程名称和类型,以及代码的起始和结束块。
大多数语言允许主程序使用任意名称。`N_MAIN` STAB 类型会告诉调试器在程序中使用的主程序名称。只有字符串字段是至关重要的;它表示构成主程序的函数的名称。大多数 C 编译器不会使用该 STAB(它们希望调试器假设该名称是主程序的名称),但是一些 C 编译器会发出 N_MAIN STAB 来获得主函数。
在出现其他任何 STAB 之前,必须用一个 STAB 指定源文件。这一信息包含在 STAB 类型 N_SO 的符号中。字符串字段包含文件的名称。符号的值是与该文件对应的文本部分的起始地址。
`N_SLINE` 符号表示源代码行的起始位置。`desc` 字段包含行号,而 `value` 包含源代码行的起始部分的代码地址。在大多数机器上,该地址是**绝对地址**;对于 STAB,该地址相是对于出现 N_SLINE 符号的函数的相对地址。
以下所有 STAB 通常对函数使用 N_FUN 符号类型:
其他常见的部分包括:
N_SLINE, N_XLINE是行号【第一个和最后一个】N_LBRAC是左括号,即函数的开始部分N_RBRAC是右括号,即函数的结束部分N_SOL是所有包含在该ELF二进制文件中的文件
从 STAB 格式获取信息
接下来的步骤是扫描每个二进制文件中的调试信息,并判断哪些文件名构成该二进制文件。对于每个文件,将捕捉每个函数的所有函数名称和行号(第一个行号和最后一个行号)。可以使用相连的列表存储这些信息。
1.STAB 格式的信息
- 对二进制文件进行扫描,查看文件中的 stab 部分。
- 如果找到
N_SOL,则表示二进制文件中包含该文件的名称,并且文件名可以存储到该符号中。 - 在获取文件名后,下一步是获取该文件中包含的所有函数。
- `N_FUN` 表示 stab 部分中的函数。如果我们从
N_SOL符号(文件名)后获得该符号,则意味着以上文件(名)遇到一个函数。函数名和细节可以存储在N_FUN中。
- `N_FUN` 表示 stab 部分中的函数。如果我们从
- 此后,如果返回 `N_LBRAC` 符号,该符号表示一个左括号和函数的开始部分。现在可以确定,上述函数将从这里开始。紧随着该符号的是 `N_SLINE` 或 `N_XLINE`,它们表示函数中的代码行,即第一个行号和最后一个行号,或者需要的话,所有行号都可以存储在该符号中。
在几个行号条目之后(N_SLINE 或 N_XLINE),将捕捉到 `N_RBRAC` 符号。如果遇到该符号,则表示函数的结束。此时,将捕捉到一个信息集,
对于二进制文件来说,该信息集包含一个 included 文件名、一个函数以及函数的细节。简单来说,我们可以获取 included 文件中的所有函数,以及该二进制文件中的所有 included 文件的细节。要获取有关二进制文件的完整信息,则需要执行以上这些步骤。
符号表存储了二进制文件中所有符号(函数)的细节。以下展示了从 STAB 格式收集一个函数的信息。
清单 1. 显示 STAB 类型的简单程序
`abcd.c ----> Symbol is N_SOL``int function_name(int a, int b) ------> Symbol is N_FUN``{ ----> Symbol is N_LBRAC`` ``int i; ----->Symbol is N_SLINE`` ``i = a+b;`` ``return i;``} -----> Symbol is N_RBRAC`
【以下】图 1 和图 2中的流程图显示了从 STAB 格式收集信息的算法。
首先获取下一个 stab 部分,然后:
- 到达 stab 部分的末端后,将从不同 stab 部分收集到的所有信息整合在一起,然后将它们存储到数据结构中。如果没有到达 stab 部分的末端,则执行以下操作:
- 检查该部分是否为 = N_SOL,如果是,则提取源文件名并返回到初始部分。
- 如果不等于 N_SOL,那么是否等于 = N_UNDF/N_ENDM?如果是,则重新设置当前函数。返回到初始部分。
- 如果不等于 = N_UNDF/N_ENDM,则检查它是否 = N_FUN,如果等于该值的话,则寻找子程序名。如果需要的话,请存储 stab 数。返回到初始部分。
- 如果该部分不等于 N_FUN,则检查它是否等于 N_LBRAC,如果是等于该值的话,那么它表示子程序的开始部分。(如果已经捕捉到 N_FUN 部分,那么可以为此设置一个标记)。返回到初始部分。
- 如果该部分不等于 N_LBRAC,则检查它是否等于 N_SLINE/n_XLINE;N_LBRAC 之后还有许多代码行。如果等于该值的话,则存储子程序的第一行和最后一行代码,以及行号。返回到初始部分。
- 如果该部分不等于 N_SLINE/n_XLINE,则检查它是否等于 N_RBRAC。如果等于该值的话,那么它表示函数的结束部分。返回到初始部分。如果该部分不等于 N_RBRAC,则忽略这个 stab 部分并回到初始部分。
图 1. 从 STAB 提取调试信息的流程图

图 2. 从 STAB 提取调试信息的流程图(续)

通过 objdump -G obj/kern/kernel | more 可以查看到kernel的所有stab
// Entries in the STABS table are formatted as follows.
struct Stab {
uint32_t n_strx; // index into string table of name 在.stabstr的偏移
uint8_t n_type; // type of symbol
uint8_t n_other; // misc info (usually empty)
uint16_t n_desc; // description field-->行号
uintptr_t n_value; // value of symbol --> 这里就是指地址。
}; //stab结构
比如:
1 SOL 0 0 f010000c 18 kern/entry.S
//偏移、类型【N_SOL、文件名】、通常为空、文件内所在行号、地址【0xf010000c,kernel入口点entry】
注意:`LYSM`表示函数局部变量符号。SLINE表示函数内部行。
lib/string.c/strcpy函数
char *
strcpy(char *dst, const char *src)
{
char *ret;
ret = dst;
while ((*dst++ = *src++) != '\0')
/* do nothing */;
return ret;
}
解析之后得到
1131 FUN 0 0 f0101a69 6099 strcpy:F(0,20)=*(0,2)
1132 PSYM 0 0 00000008 6121 dst:p(0,20) <--- 栈中的偏移
1133 PSYM 0 0 0000000c 6133 src:p(0,19) <--- 栈中的偏移
1134 SLINE 0 33 00000000 0 // 00000000 ---> 33, 这里33就是表示函数定义的行号。
1135 SLINE 0 36 00000006 0 // 第一行代码相对文件的行号。
1136 SLINE 0 37 0000000c 0
1137 SLINE 0 37 0000000d 0
1138 SLINE 0 39 0000002b 0
1139 SLINE 0 40 0000002e 0
1140 LSYM 0 0 fffffffc 6145 ret:(0,20) <-局部变量ret
1141 LBRAC 0 0 00000000 0
1142 RBRAC 0 0 00000030 0
解析debuginfo_eip
debuginfo_eip实际是通过stab_binsreach实现的,这里kdebug.c中有一个说明和示例:
// stab_binsearch(stabs, region_left, region_right, type, addr)
// 就是指定region_left-region_right检索范围,找到类型为type,并且包含addr的stab
// Some stab types are arranged in increasing order by instruction
// address. For example, N_FUN stabs (stab entries with n_type ==
// N_FUN), which mark functions, and N_SO stabs, which mark source files.
//
// Given an instruction address, this function finds the single stab
// entry of type 'type' that contains that address.
// 给出指令的地址,此函数会找到一条指定type的stab,包含这个地址
// The search takes place within the range [*region_left, *region_right].
// Thus, to search an entire set of N stabs, you might do:
// 检索会覆盖left和right,这两个既作为传参又用于返回。left匹配包含addr的stab
// 而right指向下一个stab之前的位置
// left = 0;
// right = N - 1; /* rightmost stab */
// stab_binsearch(stabs, &left, &right, type, addr);
//
// The search modifies *region_left and *region_right to bracket the
// 'addr'. *region_left points to the matching stab that contains
// 'addr', and *region_right points just before the next stab. If
// *region_left > *region_right, then 'addr' is not contained in any
// matching stab.
//
// For example, given these N_SO stabs:
// Index Type Address
// 0 SO f0100000
// 13 SO f0100040
// 117 SO f0100176
// 118 SO f0100178
// 555 SO f0100652
// 556 SO f0100654
// 657 SO f0100849
// this code:
// left = 0, right = 657;
// stab_binsearch(stabs, &left, &right, N_SO, 0xf0100184);
// will exit setting left = 118, right = 554.
// 以上都是SO类型,要找0-657之间的,包含地址0xf0100184的stab,那么就是118起始的这个stab,right赋值为下一个stab之前=555-1=554
具体地kdebug.c/debuginfo_eip,给出addr,找到这个地址对应的函数所在文件名,文件内行号,函数名称以及eip与函数的第一条指令的偏移量。其实就是对符号表【一堆stab】的搜索。
int
debuginfo_eip(uintptr_t addr, struct Eipdebuginfo *info)
{
const struct Stab *stabs, *stab_end;
const char *stabstr, *stabstr_end;
int lfile, rfile, lfun, rfun, lline, rline;
// Initialize *info
info->eip_file = "<unknown>";
info->eip_line = 0;
info->eip_fn_name = "<unknown>";
info->eip_fn_namelen = 9;
info->eip_fn_addr = addr;
info->eip_fn_narg = 0;
// Find the relevant set of stabs
if (addr >= ULIM) {
stabs = __STAB_BEGIN__;
stab_end = __STAB_END__;
stabstr = __STABSTR_BEGIN__;
stabstr_end = __STABSTR_END__;
} else {
// Can't search for user-level addresses yet!
panic("User address");
}
// String table validity checks
if (stabstr_end <= stabstr || stabstr_end[-1] != 0)
return -1;
//以上初始化并且找到STAB符号表后
// Now we find the right stabs that define the function containing
// 'eip'. First, we find the basic source file containing 'eip'.
// Then, we look in that source file for the function. Then we look
// for the line number.
//首先找到源文件N_SO->该文件中的N_FUN->在找行号SLINE
// Search the entire set of stabs for the source file (type N_SO).
lfile = 0;
rfile = (stab_end - stabs) - 1;//符号表偏移
stab_binsearch(stabs, &lfile, &rfile, N_SO, addr);
if (lfile == 0)
return -1;
// Search within that file's stabs for the function definition
// (N_FUN).
lfun = lfile;
rfun = rfile;
stab_binsearch(stabs, &lfun, &rfun, N_FUN, addr);
if (lfun <= rfun) {
// stabs[lfun] points to the function name
// in the string table, but check bounds just in case.
if (stabs[lfun].n_strx < stabstr_end - stabstr)
info->eip_fn_name = stabstr + stabs[lfun].n_strx;
info->eip_fn_addr = stabs[lfun].n_value;
addr -= info->eip_fn_addr;
// Search within the function definition for the line number.
lline = lfun;
rline = rfun;
} else {
// Couldn't find function stab! Maybe we're in an assembly
// file. Search the whole file for the line number.
info->eip_fn_addr = addr;
lline = lfile;
rline = rfile;
}
// Ignore stuff after the colon.
info->eip_fn_namelen = strfind(info->eip_fn_name, ':') - info->eip_fn_name;
//至此已经确定addr所在的fun的起始行lline和结束行rline
// Search within [lline, rline] for the line number stab.
// If found, set info->eip_line to the right line number.
// If not found, return -1.
// 在lline-rline中确定addr行号,如果找到设置info->eip_line=该行号
// 否则返回-1
// Hint:
// There's a particular stabs type used for line numbers.
// Look at the STABS documentation and <inc/stab.h> to find
// which one.
// Your code here.【这里需要填写,确定addr所在行号】
stab_binsearch(stabs,&lline,&rline,N_SLINE,addr);
if(lline<=rline){//info就是一个参数,用于存储需要获取的调试信息,引用返回给调用者
info->eip_line = stabs[rline].n_desc;
}
else
return -1;
// Search backwards from the line number for the relevant filename
// stab.
// We can't just use the "lfile" stab because inlined functions
// can interpolate code from a different file!
// Such included source files use the N_SOL stab type.
while (lline >= lfile
&& stabs[lline].n_type != N_SOL
&& (stabs[lline].n_type != N_SO || !stabs[lline].n_value))
lline--;
if (lline >= lfile && stabs[lline].n_strx < stabstr_end - stabstr)
info->eip_file = stabstr + stabs[lline].n_strx;
// Set eip_fn_narg to the number of arguments taken by the function,
// or 0 if there was no containing function.
if (lfun < rfun)
for (lline = lfun + 1;
lline < rfun && stabs[lline].n_type == N_PSYM;
lline++)
info->eip_fn_narg++;
return 0;
}
修改mon_backtrace【使用debuginfo_eip]
int
mon_backtrace(int argc, char **argv, struct Trapframe *tf)
{
// Your code here.
uint32_t ebp = read_ebp();//从read_ebp中确定应该使用uint32_t类型
cprintf("Stack backtrace:\n");
while((int)ebp!=0){//由于构造内核栈的时候ebp初始为0,因此ebp=0时表示已经回溯到最顶上
uint32_t eip = *((uint32_t *)ebp+1);//相当于ebp+4,32位指针++,偏移4字节
uint32_t args[5];
for(int i=2;i<=6;i++){
args[i-2]=*((uint32_t *)ebp+i);
}
cprintf(" ebp %08x eip %08x args %08x %08x %08x %08x %08x\n",ebp,eip,args[0],args[1],args[2],args[3],args[4]);
//修改部分
struct Eipdebuginfo info;
if(!debuginfo_eip(eip,&info)){
cprintf("%s:%d: %.*s+%d\n",info.eip_file,info.eip_line,info.eip_fn_namelen,info.eip_fn_name,eip - info.eip_fn_addr);
}//如果没有找到返回-1,则会输出<unknown>+0
//
ebp=*((uint32_t *)ebp);//回溯到上一个栈帧
}
注:printf("%.*s", length, string) prints at most length characters of string. Take a look at the printf man page to find out why this works.【至多打印len字符,可以观察printffmt.c分析】
在终端下实现backtrace命令
将backtrace嵌入终端中,使其可以被调用。只需要修改 kern/monitor.c 的
static struct Command commands[] = {
{ "help", "Display this list of commands", mon_help },
{ "kerninfo", "Display information about the kernel", mon_kerninfo },
//增加以下
{ "backtrace", "Display a listing of function call frames", mon_backtrace},
};
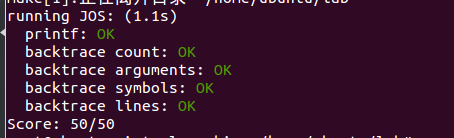
The End——make grade