usercorn对binary的加载和对binary文件头的解析
go/cmd/main/main.go中package main->func main()作为usercorn的起始运行点。
- 其中调用cmd.Main()运行,调用了cmd包中的Main函数,即为
go/cmd/launcher.go中的Main()
go/cmd/launcher.go中的Main()调用
-
命令参数小于2,则打印usage(),提示如何运行,并退出
-
否则生成commands对象
type command struct { name, desc string main func(args []string) }-
根据命令行输入命令,生成commands对象,可选对象有:
Commands: run | execute a binary cfg | explore a program's control flow graph cgc | execute a Cyber Grand Challenge binary or set com | execute a DOS COM binary fuzz | fuzz acts as an AFL fork server imgtrace | record memory access patterns to image files repl | execute assembly on an interactive command line shellcode | execute a blob of machine code directly trace | manipulate a saved trace file -
因此运行时
cmd, ok := commands[os.Args[1]]生成commands[‘run’]对象->cmd-
如果commands有效则,则将余下参数加入args,调用cmd.main(args)
- 这个main(args)是commands对象中的元素
main func(args []string)。而commands[‘run’]在go/cmd/run/main.go中注册过:func init() { cmd.Register("run", "execute a binary", Main) } - 其中的Main就是同文件下的函数
func Main(args []string) - 故在运行cmd.main(args)时相当于调用了go/cmd/run/main.go中的
Main(args []string),也就是运行了cmd.NewUsercornCmd().Run(args, os.Environ())并在运行后退出
func Main(args []string) { os.Exit(cmd.NewUsercornCmd().Run(args, os.Environ())) } //Main() cmd, ok := commands[os.Args[1]] if ok { //注意这里参数的变化,os.Args[0]指的是usercorn,os.Args[1]指的是run,os.Args[2]指的是elf文件 //下述语句处理以后,agrs变为“usercorn run”、“elf” args := append([]string{strings.Join(os.Args[:2], " ")}, os.Args[2:]...) cmd.main(args) } else { …… } - 这个main(args)是commands对象中的元素
-
否则打印
Command '%s' not found.,并调用usage()且退出
-
-
注:commands相关的Register(key,description,main function)函数在go/cmd/launcher.go中定义,用于构架/初始化赋值commands对象
func NewUsercornCmd()在go/cmd/cmd.go中定义,用于创建usercorncmd对象
- 初始化了Flags对象,其定义在go中的库函数flags中,用于管理命令行参数解析
- 初始化了MakeUsercorn对象,定义接口函数。
- 该函数对usercorn工具运行了stat指令/系统调用os.Stat(elf)`,并new了一个usercorn对象【间接调用了NewUsercorn】
- stat指令:文件/文件系统的详细信息显示,主要用于显示文件或文件系统的详细信息。包括保护模式,节点号,连接数,上一次访问时间等信息,stat命令主要用于显示文件或文件系统的详细信息【看看当前执行的elf文件的权限是否合法,是否可执行】。
- 返回新建的usercorn对象【附带了elf二进制文件和config配置选项】
usercorn.NewUsercorn(exe, cmd.Config)在go/usercorn.go中定义
- 注意:这里只是定义MakeUsercorn,实际在Run中才调用
- 该函数对usercorn工具运行了stat指令/系统调用os.Stat(elf)`,并new了一个usercorn对象【间接调用了NewUsercorn】
- 返回创建的cmd对象【赋值了MakeUsercorn创建初始化函数和Flags参数解析器】
创建完cmd对象后,调用cmd.Run(args, os.Environ()),进行参数解析和os环境变量配置。该函数定义在go/cmd/cmd.go中func (c *UsercornCmd) Run(argv, env []string) int,主要进行了间接调用Run()【根据PC运行了ELF文件】,还在此调用前用前解析了args【这里没有涉及run elf的部分,只是做了其他参数的处理】,进行了各种cmd参数的处理和配置。
通过fs.Parse(argv[1:])对fs.Bool和fs.Var部分设置的解析格式进行了配置,只对argv[1:]的参数进行配置解析,也就是elf二进制文件及以后的部分进行解析,此后获取的args = fs.Args() ,其中args[0]即为elf二进制可执行文件。
对ELF文件的处理,如下:
- 在
Run(args, os.Environ())中调用了corn, err := c.MakeUsercorn(args[0])=c.MakeUsercorn(elf),从而间接调用了NewUsercorn(elf, cmd.Config),其在go/NewUsercorn.go中得到定义 - 该函数首先调用
os.Open(elf),打开elf可执行文件,返回文件操作符f - 调用
loader.Load(f)
在loader包中go/loader/load.go实现了二进制文件的加载,具体而言Load(f)->LoadArch(f,"any")->MatchElf(f)
-
在
/go/loader/elf.go中定义了MatchElf(r io.ReaderAt) bool-
由于不论是什么CPU构架,只要是ELF格式为二进制文件,其文件头四个字节均为
7f 45 4c 46var elfMagic = []byte{0x7f, 0x45, 0x4c, 0x46} bytes.Equal(getMagic(r), elfMagic) -
因此通过上述code,读取二进制文件的magic number和
[]byte{0x7f, 0x45, 0x4c, 0x46}进行比较,相等则返回true -
在go/loader/util.go中定义了
func getMagic(r io.ReaderAt) []byte,其中make了一个4字节大小的变量ret,调用go的io包中ReaderAt(ret,0)方法,从底层输入流的偏移量off=0位置读取len(ret)=4字节数据写入ret,从而得到二进制文件头部的魔数
-
- 如果
MatchElf(r)返回为真,说明该二进制文件是ELF格式的文件,如果返回false,则依次继续判断MatchMachO(r)、MatchMachO(r)、MatchCgc(r),确定二进制文件的格式 - 以ELF二进制文件为例,接下来会继续调用
NewElfLoader(r, arch),此时arch=“any”
在go/loader/elf.go中定义了func NewElfLoader(r io.ReaderAt, arch string) (models.Loader, error),
- 其中,调用了go的标准库elf中的函数
NewFile(r)
type File
type File struct { FileHeader Sections []*Section //链接视图 Progs []*Prog // contains filtered or unexported fields 执行试图 }type FileHeader
type FileHeader struct { Class Class //构架:0:unknown,1:32-bit,2:64-bit Data Data //大小端,0:unknown,1:小端,2:大端 Version Version OSABI OSABI ABIVersion uint8 ByteOrder binary.ByteOrder Type Type //文件类型,0:unknown,1:可重定向,2:可执行文件,3:so,4:core Machine Machine //cpu构架 Entry uint64 //二进制文件入口点,对于ELF_x86,即为<_start>函数开始运行的地址,等于readelf中的Entry point address字段值 }A FileHeader represents an ELF file header.【通过readelf -h elf可以看到各个字段的对应】
func NewFile(r io.ReaderAt) (*File, error)NewFile creates a new File for accessing an ELF binary in an underlying reader. The ELF binary is expected to start at position 0 in the ReaderAt.
-
接下来会根据
file.Machine得到二进制文件的cpu构架的宏,从而得到arch=machineNamevar machineMap = map[elf.Machine]string{ elf.EM_386: "x86", elf.EM_AARCH64: "arm64", elf.EM_ARM: "arm", elf.EM_MIPS: "mips", elf.EM_PPC64: "ppc64", elf.EM_PPC: "ppc", elf.EM_SPARC: "sparc", elf.EM_X86_64: "x86_64", } machineName, ok := machineMap[file.Machine] -
构建二进制文件加载器
ELFloader,l就是对二进制文件头部的封装
l := &ElfLoader{
LoaderBase: LoaderBase{
arch: machineName,
os: "linux",
entry: file.Entry,
byteOrder: file.ByteOrder,
},
file: file,
}
- 此后调用
sr := io.NewSectionReader(r, 0, 1<<63-1),其中r就是elf文件的路径,相当于返回了off~off+n文件字节范围的文件句柄sr,该句柄可以进行针对该文件r的Read,Seek,ReadAt操作
func NewSectionReader(r ReaderAt, off int64, n int64) *SectionReaderNewSectionReader returns a SectionReader that reads from r starting at offset off and stops with EOF after n bytes.
SectionReader implements Read, Seek, and ReadAt on a section of an underlying ReaderAt.
-
此后根据二进制文件32-bitor64-bit构架
switch file.Class,调用binary.Read(sr, file.ByteOrder, &hdr);,该函数会根据hdr【var hdr elf.Header32/64】的结构体类型,和字节序/大小端file.ByteOrder从sr句柄中填充hdr结构体字段,再对应设置二进制文件头部封装l的一系列成员变量。-
主要是对以下内容的设置:
Phoff uint32 /* Program header file offset. */ Shoff uint32 /* Section header file offset. */ Phentsize uint16 /* Size of program header entry. */ Phnum uint16 /* Number of program header entries. */ Shentsize uint16 /* Size of section header entry. */ Shnum uint16 /* Number of section header entries. */
-
利用
l.phentsize*l.phnum计算程序头表的大小,并使用ReadAt,从二进制文件程序头表偏移处l.phdr读取整个程序头表到l.phdr中,返回l,其中包含了对程序头各个部分解析后的字段存储以及程序头本身的内容l.phdr- ELF文件格式分析及各个字段解析
- e_phoff:program header offset, 保持了程序头表在文件中的偏移量(bytes),假如没有程序头表的话,该值为0
- e_shoff:section header offset,保持着段节头表在文件中的偏移量(bytes),如果没有段节头表的话,该值为0
- e_phentsize:program header entry size,保存着在文件的程序头表中一个入口的大小(bytes),所有入口大小都一样。【一个入口指向一个段的起始位置,如补充知识中的图例】
- e_phnum:program header number,保存着程序头表的入口个数,也就是说和e_phentsize的乘积就是表的大小(bytes)。
- e_shentsize: section header entry size,section段节头大小(bytes),一个段节头在段节头表中的一个入口,所有入口同样大小【一个入口指向一个节的起始位置,如补充知识中的图例】
- e_shnum:section header number,保存着在段节头表中的入口数目,与e_shentsize乘积是section头表的大小,如果没有section头表,该值为0
此后程序一直返回l到go/usercorn.go中的NewUsercorn,得到l, err := loader.Load(f)。
此后调用NewUsercornRaw(l,config),其中的config,来自于对命令行各个参数选项的解析值,具体在go/cmd/cmd.go中func (c *UsercornCmd) Run(argv, env []string)中进行了设置。
-
通过之前对elf header的解析,从而读取
arch和OS【其中l.Arch()和l.OS()定义在go/loader/loader.go中定义】,通过go/arch/arch.go中定义的GetArch(arch_name,os)构建a=arch对象,o=os对象- 根据arch,得到各个构架下对应的.go文件的全局变量Arch,其中包含了Name,Bits,Cpu,Dis,Asm,PC,SP,Regs的宏定义等
- 根据os,在Arch中找到对应OS成员,返回os对象o
-
接下来调用
cpu, err := a.Cpu.New(),调用unicorn的CPU接口,构建一个指定构架的CPU->&unicorn.Builder{Arch: uc.ARCH_ARM, Mode: uc.MODE_ARM}。 -
此后调用了
task := NewTask(cpu, a, OS, l.ByteOrder()),该函数在go/task.go中定义,初始化了一个Task对象,具体如下:func NewTask(c cpu.Cpu, arch *models.Arch, os *models.OS, order binary.ByteOrder) *Task { return &Task{ Cpu: c, arch: arch, os: os, bits: arch.Bits, Bsz: arch.Bits / 8, order: order, } } -
然后初始化了一个Usercorn对象`u`,把cmd.config赋值给u.config,初始化了一个Debug对象
debug -
此后调用
u.trace, err = trace.NewTrace(u, &config.Trace),其中的函数在go/models/trace/trace.go中定义。- 获取了对应构架中的所有寄存器宏
enums := u.Arch().RegEnums() - 新建了&Trace对象,包括寄存器组宏,PC宏,配置config,keyframe{regEnums: enums}
- keytrame的对象结构体和相关函数在go/models/trace/keyframe.go中定义
- 调用
t.keyframe.reset()初始化keyframe,具体是分配了各种成员变量的存储空间 - 新建NewMemIO对象【使用了”github.com/lunixbochs/ghostrace/ghost/memio”】,初始化自定义的两个回调函数,未来使用u.memio访问内存的时候就会自动调用对应内存操作的回调函数
- ReadAt()回调函数
- 判断从addr开始,读取len(p)的大小的内存是否满足读权限要求【猜测】,并且读取数据到p中
- 同时通过
u.trace.OnMemReadSize(addr, uint32(len(p)))把读取内存的操作记录到u.trace中,该函数定义在go/models/trace/trace.go中,进行了t.Append(&OpMemRead{addr, size}, false)的操作
- WriteAt()回调函数
- 判断从addr开始,写入len(p)的大小的数据到内存中,查看是否满足写权限要求【猜测】,并且完成内存写操作
- 同时通过
u.trace.OnMemWrite(addr, p)把写内存的操作记录到u.trace中,该函数定义在go/models/trace/trace.go中,进行了t.Append(&OpMemWrite{addr, data}, false)的操作
- 因此memio完成了内存读写,并记录对内存的读写操作,最后返回读写长度
- ReadAt()回调函数
- 调用
OS.Kernels(u)来加载kernel
- 获取了对应构架中的所有寄存器宏
接下来根据filepath.Abs(exe)得到可执行文件的绝对路径,添加到u.exe中,并存储二进制文件LEF头u.loader = l,此后调用u.mapBinary(f, false)进行二进制文件的各个段的映射,其中f为f, err := os.Open(exe)打开二进制文件后的操作句柄。
-
该函数定义在go/usercorn.go中
-
首先通过u.loader获取elf头
-
调用l.Type()返回loader.EXEC,故设置dynamic = false
-
此后调用
l.Segments(),该函数定义在go/loader/elf.go中,返回得到段信息对象segments []models.SegmentData和error【此时只是处理了段信息的内部结构表示,还没有完成段的映射】。-
首先新建
e.file.Progs大小的[]models.SegmentData类型变量ret -
e.file.Progs,来自于在go/loader/elf.go中定义NewElfLoader()内调用的
file, err := elf.NewFile(r) -
其中
struct file.Progs在官方文档中有体现type File struct { FileHeader Sections []*Section Progs []*Prog // contains filtered or unexported fields } type Prog struct { ProgHeader // Embed ReaderAt for ReadAt method. // Do not embed SectionReader directly // to avoid having Read and Seek. // If a client wants Read and Seek it must use // Open() to avoid fighting over the seek offset // with other clients. io.ReaderAt // contains filtered or unexported fields } type ProgHeader struct { Type ProgType //描述段的类型,例如 //PT_LOAD ProgType = 1表示可加载的段 //PT_DYNAMIC ProgType = 2 表示存储了动态链接信息的段/* Dynamic linking information segment. */ //PT_TLS ProgType = 7 线程局部存储段/* Thread local storage segment */ Flags ProgFlag //该段的访问权限,PF_X,PF_W,PF_R Off uint64 Vaddr uint64 Paddr uint64 Filesz uint64 Memsz uint64 Align uint64 } -
遍历所有
e.file.Progs,如果段类型不是需要加载的段,则continue -
否则调用progs.Open(),定义如下,返回一个对二进制文件body部分的操作器,包含Reader和Seeker【sets the offset for the next Read or Write to offset】:
func (p *Prog) Open() io.ReadSeekerOpen returns a new ReadSeeker reading the ELF program body.
-
根据
prog.Flags段的访问权限设置prot-
elf.PF_R=>prot = 1 -
elf.PF_W=>prot = 2 -
elf.PF_X =>prot = 4
-
-
处理段头ProgHeader中的其他内容,形成models.SegmentData,加入到ret中,返回包含段头信息的集合
ret = append(ret, models.SegmentData{ Off: prog.Off, Addr: prog.Vaddr, Size: prog.Memsz, Prot: prot, DataFunc: func() ([]byte, error) { data := make([]byte, filesz) _, err := stream.Read(data) // swallow EOF so we can still load broken binaries if err == io.EOF { err = nil } return data, err }, }) -
程序头表各个字段含义:
p_offset 此数据成员给出本段内容在文件中的位置,即段内容的开始位置相对于文件 开头的偏移量。 p_vaddr 此数据成员给出本段内容的开始位置在进程空间中的虚拟地址。 p_paddr 此数据成员给出本段内容的开始位置在进程空间中的物理地址。对于目前大 多数现代操作系统而言,应用程序中段的物理地址事先是不可知的,所以目前这个 成员多数情况下保留不用,或者被操作系统改作它用。 p_filesz 此数据成员给出本段内容在文件中的大小,单位是字节,可以是 0。 p_memsz 此数据成员给出本段内容在内容镜像中的大小,单位是字节,可以是 0。 p_flags 此数据成员给出了本段内容的属性/标志位。 p_align 对于可装载的段来说,其 p_vaddr 和 p_offset 的值至少要向内存页面大小对 齐。此数据成员指明本段内容如何在内存和文件中对齐。如果该值为 0 或 1,表明 没有对齐要求;否则,p_align 应该是一个正整数,并且是 2 的幂次数。p_vaddr 和 p_offset 在对 p_align 取模后应该相等。
-
-
返回到usercorn.go中的mapBinary函数内,接下来设置low=0xffffffffffffffff=-1,high=0x0,遍历各个段,设置所有段所在虚拟空间的最低地址和最高地址
- 根据该段起始的虚拟地址,修改low和high值
- size==0,continue
- seg.Addr<low,更新low
- seg.Addr+seg.Size>high,更新high
-
获取loadBias,来自于命令行,如果运行usercorn run的时候没有进行设置,则默认
u.config.ForceBase为0 -
由于此时isInterp为false,因此以下部分不会运行。
- 重新设置loadBias,来自于
u.config.ForceInterpBase - 如果
loadBias <= barrier=u.brk + 8*1024*1024,那么要求最低为barrier
- 重新设置loadBias,来自于
-
以下部分只有动态链接库.so程序才会运行,对于elf文件,dynamic=false
- 设置mapLow=low【所有段虚拟地址的最小值】
- 如果loadBias有设置,不为0,那么maplow=loadBias。
- 否则,如果mapLow=0,即low=0时,那么设置mapLow=0x1000000
- 此后调用
u.MemReserve(mapLow, high-low, false),具体的定义没有找到,猜测功能和go/task.go中的func (t *Task) MemReserve(addr, size uint64, fixed bool) (*cpu.Page, error)类似- 释放掉addr~size部分的内存,并为这一片内存生成一个新page对象返回
- 设置loadBias=page.Addr - low
-
dsec=“exe”
-
遍历所有segments信息集合
- 获取段的权限prot
- 创建一个文件描述符对象,用于构建指定范围内的文件映射
fileDesc := &cpu.FileDesc{Name: f.Name(), Off: seg.Off, Len: seg.Size} - 对于elf文件并且未设置初始bias,则LoadBias=0
- 那么现在进行文件映射
_, err = u.Mmap(loadBias+seg.Addr, seg.Size, prot, true, desc, fileDesc),该定义并未找到,但是过程类似于go/task.go中的func (t *Task) Mmap(addr, size uint64, prot int, fixed bool, desc string, file *cpu.FileDesc)- 映射地址为0+seg.Addr=seg.Addr
- 完成addr和size的对齐
- 释放addr~addr+size空间的内容,并且返回这篇空间形成新page
- 设置这个page的desc【“exe”】,file【文件名,文件偏移,偏移往后size】
- 调用
t.Cpu.MemMap进行真正的指定范围文件映射,该函数定义在go/cpu/unicorn/unicorn.go中,实际调用了u.Unicorn.MemMapProt(addr, size, prot) - 将映射的page加入
t.memsim.Mem中管理,并设置对应于这个page的备用hook【??】
-
以上是完成了elf文件各个段的映射【注意,还没有写入数据,仅仅是进行了映射。】
-
构建merged变量,遍历所有段信息segments集合,通过合并覆盖段,构建新的段信息集合merged【合并同类段,得到最后的大段信息集合】。
- 估计是在处理多个线程分割大段为小段的情况。
- 例如,一般进程的栈空间会被多线程拆分为多个小的栈,要将这些栈merged成为一个栈。但是这里讨论的是段。
s2.Overlaps(s)和s2.Merge(s)定义在go/models/segments中
-
遍历段信息segments集合,调用
data, err = seg.Data();,根据go/models/segment.go中可知实际调用的是DataFunc()func (s *SegmentData) Data() ([]byte, error) { return s.DataFunc() } -
其中获得了针对段的ReadSeeker,可以读取到每个段中的数据,返回data。
-
在调用
u.MemWrite(loadBias+seg.Addr, data),该函数定义在go/usercorn.go中func (u *Usercorn) MemWrite(addr uint64, p []byte) error { _, err := u.memio.WriteAt(p, addr) return err } //p=data,包括了该段的数据u.memio.WriteAt(p, addr)定义在go/usercorn.go中,间接调用了u.Task.MemWrite(addr, p);- 在go/task.go中定义的
func (t *Task) MemWrite(addr uint64, p []byte),再调用了err := t.Cpu.MemWrite(addr, p),其定义在go/models/cpu/mem.go中 - 再调用了定义在go/models/cpu/memsim.go中的
m.Sim.Write(addr, p, 0),通过copy(mm.Data[o:], p)完成了真正的内存写
-
得到映射后的程序运行入口地址
entry = loadBias + l.Entry(),如果没有设置LoadBias,则依旧为l.Entry() -
如果有解释器
interpreter,则还需要映射这个解释器 -
否则直接返回
return 0, entry, loadBias, entry, nil
回到func NewUsercorn(exe string, config *models.Config) (models.Usercorn, error),得到u.entry=u.binEntry=l.Entry(),u.base=0。
接下来要做的事情是确定brk,初始设置u.brk=0,获取段信息集合segments,并遍历。
-
由于.text是没有可写权限的,.rodata也没有,只有再往上的.data或.bss有,而堆的位置在虚拟空间上看,是在他们顶部放置的
-
因此判断
seg.Prot&cpu.PROT_WRITE != 0,计算该段高地址为addr := u.base + seg.Addr + seg.Size,如果addr > u.brk,就设置u.brk = addr,一直找到可写段中的最高地址作为堆底。 -
做对齐操作
if u.brk > 0 { mask := uint64(4096) u.brk = (u.brk + mask) & ^(mask - 1) } -
故可以通过
u.brk获得堆顶地址【最初是堆底地址】
最后通过u.RegWrite(u.Arch().PC, u.Entry()),其中u.Entry()在go/usercorn.go中定义返回u.entry,即从ELF文件头中读取的起始运行地址:_start地址,写入到u.Arch().PC中。
至此,func NewUsercorn(…)运行完毕,返回usercorn对象u,此后会返回到go/cmd/cmd.go中corn, err := c.MakeUsercorn(args[0])继续运行,通过c.Usercorn = corn 在c *UsercornCmd中记录usercorn对象。
接下来根据命令行的一些参数做一些处理,设置defer函数处理释放操作。由于c.SetupUsercorn()和c.RunUsercorn()初始为nil【一开始NewUsercornCmd只设置了MakeUsercorn,其他函数成员都为nil】,因此执行corn.Run()
此后进入/go/usercorn.go运行Run()。
if c.RunUsercorn != nil { //由于RunUsercorn==nil,则
err = c.RunUsercorn()
} else {
err = corn.Run() //note:调用usercorn.go中的run
}
在Run()中进行了trace和hook相关的配置处理,调用Start(pc, u.exit),从pc处开始运行二进制文件,至此二进制文件加载过程结束。【其中遗留了一些对trace方面和其他命令行参数处理的解析】
pc, _ := u.RegRead(u.arch.PC)
//note:運行pc
err = u.Start(pc, u.exit)
//go/usercorn.go中Start的实现
func (u *Usercorn) Start(pc, end uint64) error {
u.running = true
err := u.Cpu.Start(pc, end) //具体在unicorn中实现
u.running = false
return err
}
注:其中u.Cpu.Start(pc, end)在unicorn中实现,可追溯到各二进制文件arch不同,产生不同的CPU emulator,例如ARM构架参数Cpu: &unicorn.Builder{Arch: uc.ARCH_ARM, Mode: uc.MODE_ARM},获取unicorn.Builder以执行Start(pc, end)
补充知识
init和main
- 第一行代码 *package
* 定义了包名。你必须在源文件中非注释的第一行指明这个文件属于哪个包,如:package main。**package main表示一个可独立执行的程序,每个 Go 应用程序都包含一个名为 main 的包。** - 下一行 import “fmt” 告诉 Go 编译器这个程序需要使用 fmt 包(的函数,或其他元素),fmt 包实现了格式化 IO(输入/输出)的函数。
- 下一行 func main() 是程序开始执行的函数。main 函数是每一个可执行程序所必须包含的,一般来说都是在启动后第一个执行的函数(如果有 init() 函数则会先执行该函数)。
defer机制
go语言中的defer提供了在函数返回前执行操作的机制,在需要资源回收的场景非常方便易用(比如文件关闭,socket链接资源十分,数据库回话关闭回收等),在定义资源的地方就可以设置好资源的操作,代码放在一起,减小忘记引起内存泄漏的可能。 defer机制虽然好用,但却不是免费的,首先性能会比直接函数调用差很多;其次,defer机制中返回值求值也是一个容易出错的地方。
return指令的执行分三步,第一步拷贝return值到返回值内存地址,第二步会调用runtime.deferreturn去执行前面注册的defer函数,第三部再执行ret汇编指令。
无论defer在函数中的哪个位置定义,都会在最终紧接着ret指令之前被执行。
gdb调试usercorn
运行usercorn gdb<port>,进入gdb,键入target remote localhost:<port>
go语言标准库函数简介
ELF文件格式
首先,ELF文件格式提供了两种视图,分别是链接视图和执行视图。
链接视图是以节(section)为单位,执行视图是以段(segment)为单位。
链接视图就是在链接时用到的视图,而执行视图则是在执行时用到的视图。
下图左侧的视角是从链接来看的,右侧的视角是执行来看的。总个文件可以分为四个部分:
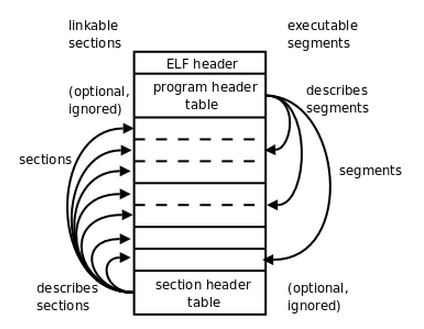
- ELF header: 描述整个文件的组织。
- 【执行视图】Program Header Table: 描述文件中的各种segments,用来告诉系统如何创建进程映像的。
- sections 或者 segments:segments是从运行的角度来描述elf文件,sections是从链接的角度来描述elf文件,也就是说,在链接阶段,我们可以忽略program header table来处理此文件,在运行阶段可以忽略section header table来处理此程序(所以很多加固手段删除了section header table)。从图中我们也可以看出,segments与sections是包含的关系,一个segment包含若干个section。
- 【链接视图】Section Header Table: 包含了文件各个section的属性信息。
程序头部表(Program Header Table),如果存在的话,告诉系统如何创建进程映像。
节区头部表(Section Header Table)包含了描述文件节区的信息,比如大小、偏移等。
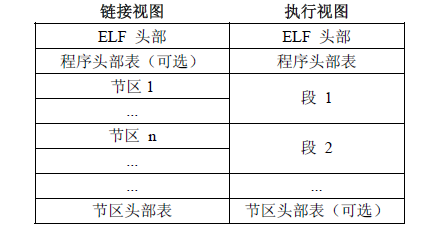
ELF文件各种表解析
堆分配回收相关glibc函数
realloc
realloc() 函数用来重新分配内存空间,其原型为:
void* realloc (void* ptr, size_t size);
【参数说明】ptr 为需要重新分配的内存空间指针,size 为新的内存空间的大小。
realloc() 对 ptr 指向的内存重新分配 size 大小的空间,size 可比原来的大或者小,还可以不变(如果你无聊的话)。当 malloc()、calloc()分配的内存空间不够用时,就可以用 realloc() 来调整已分配的内存。
如果 ptr 为 NULL,它的效果和 malloc() 相同,即分配 size 字节的内存空间。
如果 size 的值为 0,那么 ptr 指向的内存空间就会被释放,但是由于没有开辟新的内存空间,所以会返回空指针;类似于调用free()。
几点注意:
- 指针 ptr 必须是在动态内存空间分配成功的指针,形如如下的指针是不可以的:int *i; int a[2];会导致运行时错误,可以简单的这样记忆:用 malloc()、calloc()、realloc() 分配成功的指针才能被 realloc() 函数接受。
- 成功分配内存后 ptr 将被系统回收,一定不可再对 ptr 指针做任何操作,包括 free();相反的,可以对 realloc() 函数的返回值进行正常操作。
- 如果是扩大内存操作会把 ptr 指向的内存中的数据复制到新地址(新地址也可能会和原地址相同,但依旧不能对原指针进行任何操作);如果是缩小内存操作,原始据会被复制并截取新长度。
【返回值】分配成功返回新的内存地址,可能与 ptr 相同,也可能不同;失败则返回 NULL。
calloc()
calloc() 函数用来动态地分配内存空间并初始化为 0,其原型为:
void* calloc (size_t num, size_t size);
calloc() 在内存中动态地分配 num 个长度为 size 的连续空间,并将每一个字节都初始化为 0。所以它的结果是分配了 num*size 个字节长度的内存空间,并且每个字节的值都是0。
如果 size 的值为 0,那么返回值会因标准库实现的不同而不同,可能是 NULL,也可能不是,但返回的指针不应该再次被引用。
char *ptr = (char *)calloc(10, 10); // 分配100个字节的内存空间
calloc() 与 malloc()的一个重要区别是:calloc() 在动态分配完内存后,自动初始化该内存空间为零,而 malloc() 不初始化,里边数据是未知的垃圾数据。下面的两种写法是等价的:
// calloc() 分配内存空间并初始化
char *str1 = (char *)calloc(10, 2);
// malloc() 分配内存空间并用 memset() 初始化
char *str2 = (char *)malloc(20);
memset(str2, 0, 20);
malloc()
malloc() 函数用来动态地分配内存空间其原型为:
void* malloc (size_t size);
【参数说明】size 为需要分配的内存空间的大小,以字节(Byte)计。
push操作是先入栈 再将ESP-4
esp指向栈上下一个空位置,还是当前有数据位置
pwndbg> n
0x08048116 in main ()
LEGEND: STACK | HEAP | CODE | DATA | RWX | RODATA
─────────────────────────────────[ REGISTERS ]──────────────────────────────────
EAX 0xffffcde4 —▸ 0xffffcff2 ◂— '/home/spiderman/usercorn/bins/x86.linux.elf'
EBX 0x0
ECX 0xffffcdd8 ◂— 0x1
EDX 0x0
EDI 0x1
ESI 0xffffcde4 —▸ 0xffffcff2 ◂— '/home/spiderman/usercorn/bins/x86.linux.elf'
EBP 0xffffcdc8 ◂— 0x0
ESP 0xffffcd74 —▸ 0x8048f3f ◂— ja 0x8048fb0 /* 'world' */
EIP 0x8048116 (main+30) ◂— push 0x8048f45
───────────────────────────────────[ DISASM ]───────────────────────────────────
0x8048109 <main+17> sub esp, 0x40
0x804810c <main+20> mov edi, dword ptr [ecx]
0x804810e <main+22> mov esi, dword ptr [ecx + 4]
0x8048111 <main+25> push 0x8048f3f
► 0x8048116 <main+30> push 0x8048f45
0x804811b <main+35> call printf <0x8048726>
0x8048120 <main+40> pop ecx
0x8048121 <main+41> pop ebx
0x8048122 <main+42> xor ebx, ebx
0x8048124 <main+44> push edi
0x8048125 <main+45> push 0x8048f5c
───────────────────────────────────[ STACK ]────────────────────────────────────
00:0000│ esp 0xffffcd74 —▸ 0x8048f3f ◂— ja 0x8048fb0 /* 'world' */
01:0004│ 0xffffcd78 ◂— 0x0
... ↓
可知esp指向栈顶,有数据的位置。