AFL(American Fuzzy Lop)是一款开源的fuzzing工具,本节大致总结了一些AFL的实现细节,主要参考:AFL内部实现细节小记。
代码插桩
使用AFL,首先需要通过afl-gcc/afl-clang等工具来编译目标,在这个过程中会对其进行插桩。
我们以afl-gcc为例。如果阅读文件afl-gcc.c便可以发现,其本质上只是一个gcc的wrapper。我们不妨添加一些输出,从而在调用execvp()之前打印全部命令行参数,看看afl-gcc所执行的究竟是什么:
gcc /tmp/hello.c -B /root/src/afl-2.52b -g -O3 -funroll-loops -D__AFL_COMPILER=1 -DFUZZING_BUILD_MODE_UNSAFE_FOR_PRODUCTION=1
可以看到,afl-gcc最终调用gcc,并定义了一些宏,设置了一些参数。其中最关键的就是-B /root/src/afl-2.52b这条。根据gcc --help可知,-B选项用于设置编译器的搜索路径,这里便是设置成/root/src/afl-2.52b(是我设置的环境变量AFL_PATH的值,即AFL目录,因为我没有make install)。
如果了解编译过程,那么就知道把源代码编译成二进制,主要是经过”源代码”->”汇编代码”->”二进制”这样的过程。而将汇编代码编译成为二进制的工具,即为汇编器assembler。Linux系统下的常用汇编器是as。不过,编译完成AFL后,在其目录下也会存在一个as文件,并作为符号链接指向afl-as。所以,如果通过-B选项为gcc设置了搜索路径,那么afl-as便会作为汇编器,执行实际的汇编操作。
所以,AFL的代码插桩,就是在将源文件编译为汇编代码后,通过`afl-as`完成。
接下来,我们继续阅读文件afl-as.c。其大致逻辑是处理汇编代码,在分支处插入桩代码,并最终再调用`as`进行真正的汇编。具体插入代码的部分如下:
fprintf(outf, use_64bit ? trampoline_fmt_64 : trampoline_fmt_32, R(MAP_SIZE));这里通过fprintf()将格式化字符串添加到汇编文件的相应位置。篇幅所限,我们只分析32位的情况,trampoline_fmt_32的具体内容如下:
static const u8* trampoline_fmt_32 =
"\n"
"/* --- AFL TRAMPOLINE (32-BIT) --- */\n"
"\n"
".align 4\n"
"\n"
"leal -16(%%esp), %%esp\n"
"movl %%edi, 0(%%esp)\n"
"movl %%edx, 4(%%esp)\n"
"movl %%ecx, 8(%%esp)\n"
"movl %%eax, 12(%%esp)\n"
"movl $0x%08x, %%ecx\n"
"call __afl_maybe_log\n"
"movl 12(%%esp), %%eax\n"
"movl 8(%%esp), %%ecx\n"
"movl 4(%%esp), %%edx\n"
"movl 0(%%esp), %%edi\n"
"leal 16(%%esp), %%esp\n"
"\n"
"/* --- END --- */\n"
"\n";这一段汇编代码,主要的操作是:
- 保存
edi等寄存器 - 将
ecx的值设置为fprintf()所要打印的变量内容 - 调用方法
__afl_maybe_log() - 恢复寄存器
__afl_maybe_log作为插桩代码所执行的实际内容,会在接下来的多个大点中详细展开,这里我们只分析"movl $0x%08x, %%ecx\n"这条指令。
回到fprintf()命令:
fprintf(outf, use_64bit ? trampoline_fmt_64 : trampoline_fmt_32, R(MAP_SIZE));可知R(MAP_SIZE)即为上述指令将ecx设置的值,即为。根据定义,宏MAP_SIZE为64K,我们在下文中还会看到他;R(x)的定义是(random() % (x)),所以R(MAP_SIZE)即为0到MAP_SIZE之间的一个随机数。【也就是fprintf会把"movl $0x%08x, %%ecx\n"中的fmt即$0x%08x,替换为R(MAP_SIZE)得到的值。也就是相当于movl R(MAP_SIZE)的结果, %%ecx】
因此,在处理到某个分支,需要插入桩代码时,afl-as会生成一个随机数,作为运行时保存在ecx中的值。而这个随机数,便是用于标识这个代码块的key。在后面我们会详细介绍这个key是如何被使用的。
fork server
编译target完成后,就可以通过afl-fuzz开始fuzzing了。其大致思路是,对输入的seed文件不断地变化,并将这些mutated input喂给target执行,检查是否会造成崩溃。因此,fuzzing涉及到大量的fork和执行target的过程。
为了更高效地进行上述过程,AFL实现了一套fork server机制。其基本思路是:启动target进程后,target会运行一个fork server;fuzzer并不负责fork子进程,而是与这个fork server通信,并由fork server来完成fork及继续执行目标的操作。这样设计的最大好处,**就是不需要调用`execve()`,从而节省了载入目标文件和库、解析符号地址等重复性工作**。如果熟悉Android的话,可以将fork server类比为zygote。
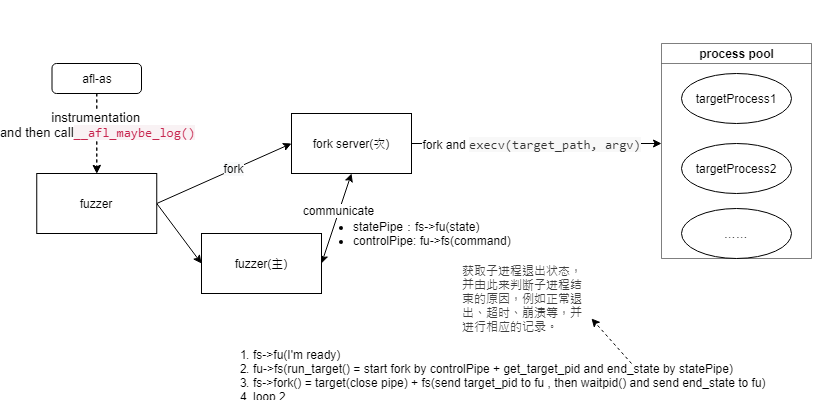
接下来,我们来看看fork server的具体运行原理。首先,fuzzer执行fork()得到父进程和子进程,这里的父进程仍然为fuzzer,子进程则为target进程,即将来的fork server。
forksrv_pid = fork();而父子进程之间,是通过管道进行通信。具体使用了2个管道,一个用于传递状态,另一个用于传递命令:
int st_pipe[2], ctl_pipe[2];对于子进程(fork server),会进行一系列设置,其中包括将上述两个管道分配到预先指定的fd【详见参考资料/dup2】,并最终执行target:
if (!forksrv_pid) {
...
if (dup2(ctl_pipe[0], FORKSRV_FD) < 0) PFATAL("dup2() failed");
if (dup2(st_pipe[1], FORKSRV_FD + 1) < 0) PFATAL("dup2() failed");
...
execv(target_path, argv);对于父进程(fuzzer),则会读取状态管道的信息,如果一切正常,则说明fork server创建完成。
fsrv_st_fd = st_pipe[0];
...
rlen = read(fsrv_st_fd, &status, 4);
...
/* If we have a four-byte "hello" message from the server, we're all set.
Otherwise, try to figure out what went wrong. */
if (rlen == 4) {
OKF("All right - fork server is up.");
return;
}接下来,我们来分析fork server是如何与fuzzer通信的。
fork server侧的具体操作,也是在之前提到的方法__afl_maybe_log()中。首先,通过写入状态管道,fork server会通知fuzzer,其已经准备完毕,可以开始fork了,而这正是上面提到的父进程等待的信息:
"__afl_forkserver:\n"
"\n"
" /* Enter the fork server mode to avoid the overhead of execve() calls. */\n"
"\n"
" pushl %eax\n"
" pushl %ecx\n"
" pushl %edx\n"
"\n"
" /* Phone home and tell the parent that we're OK. (Note that signals with\n"
" no SA_RESTART will mess it up). If this fails, assume that the fd is\n"
" closed because we were execve()d from an instrumented binary, or because\n"
" the parent doesn't want to use the fork server. */\n"
"\n"
" pushl $4 /* length */\n"
" pushl $__afl_temp /* data */\n"
" pushl $" STRINGIFY((FORKSRV_FD + 1)) " /* file desc */\n"
" call write\n"
" addl $12, %esp\n"
"\n"
" cmpl $4, %eax\n"
" jne __afl_fork_resume\n"接下来,fork server进入等待状态__afl_fork_wait_loop,读取命令管道,直到fuzzer通知其开始fork:
"__afl_fork_wait_loop:\n"
"\n"
" /* Wait for parent by reading from the pipe. Abort if read fails. */\n"
"\n"
" pushl $4 /* length */\n"
" pushl $__afl_temp /* data */\n"
" pushl $" STRINGIFY(FORKSRV_FD) " /* file desc */\n"
" call read\n"一旦fork server接收到fuzzer的信息,便调用fork(),得到父进程和子进程:
" call fork\n"
"\n"
" cmpl $0, %eax\n"
" jl __afl_die\n"
" je __afl_fork_resume\n"子进程是实际执行target的进程,其跳转到__afl_fork_resume。在这里会关闭不再需要的管道,并继续执行:
"__afl_fork_resume:\n"
"\n"
" /* In child process: close fds, resume execution. */\n"
"\n"
" pushl $" STRINGIFY(FORKSRV_FD) "\n"
" call close\n"
"\n"
" pushl $" STRINGIFY((FORKSRV_FD + 1)) "\n"
" call close\n"
"\n"
" addl $8, %esp\n"
"\n"
" popl %edx\n"
" popl %ecx\n"
" popl %eax\n"
" jmp __afl_store\n"父进程则仍然作为fork server运行,其会将子进程的pid通过状态管道发送给fuzzer,并等待子进程执行完毕;一旦子进程执行完毕,则再通过状态管道,将其结束状态发送给fuzzer;之后再次进入等待状态__afl_fork_wait_loop:
" /* In parent process: write PID to pipe, then wait for child. */\n"
"\n"
" movl %eax, __afl_fork_pid\n"
"\n"
" pushl $4 /* length */\n"
" pushl $__afl_fork_pid /* data */\n"
" pushl $" STRINGIFY((FORKSRV_FD + 1)) " /* file desc */\n"
" call write\n"
" addl $12, %esp\n"
"\n"
" pushl $0 /* no flags */\n"
" pushl $__afl_temp /* status */\n"
" pushl __afl_fork_pid /* PID */\n"
" call waitpid\n"
" addl $12, %esp\n"
"\n"
" cmpl $0, %eax\n"
" jle __afl_die\n"
"\n"
" /* Relay wait status to pipe, then loop back. */\n"
"\n"
" pushl $4 /* length */\n"
" pushl $__afl_temp /* data */\n"
" pushl $" STRINGIFY((FORKSRV_FD + 1)) " /* file desc */\n"
" call write\n"
" addl $12, %esp\n"
"\n"
" jmp __afl_fork_wait_loop\n"以上就是fork server的主要逻辑,现在我们再回到fuzzer侧。在fork server启动完成后,一旦需要执行某个测试用例,则fuzzer会调用run_target()方法。在此方法中,便是通过命令管道,通知fork server准备fork;并通过状态管道,获取子进程pid:
s32 res;
/* In non-dumb mode, we have the fork server up and running, so simply
tell it to have at it, and then read back PID. */
if ((res = write(fsrv_ctl_fd, &prev_timed_out, 4)) != 4) {
...
if ((res = read(fsrv_st_fd, &child_pid, 4)) != 4) {
...随后,fuzzer再次读取状态管道,获取子进程退出状态,并由此来判断子进程结束的原因,例如正常退出、超时、崩溃等,并进行相应的记录。
if ((res = read(fsrv_st_fd, &status, 4)) != 4) {
...
/* Report outcome to caller. */
if (WIFSIGNALED(status) && !stop_soon) {
kill_signal = WTERMSIG(status);
if (child_timed_out && kill_signal == SIGKILL) return FAULT_TMOUT;
return FAULT_CRASH;
}共享内存
作为fuzzer,AFL并不是像无头苍蝇那样对输入文件无脑地随机变化(其实也支持这种方式,即dumb模式),其最大特点就是会对target进行插桩,以辅助mutated input的生成【变异的字节是很随意的,但是变异和选种的策略是基于覆盖率的】。
具体地,插桩后的target,会记录执行过程中的分支信息;随后,fuzzer便可以根据这些信息,判断这次执行的整体流程和代码覆盖情况。
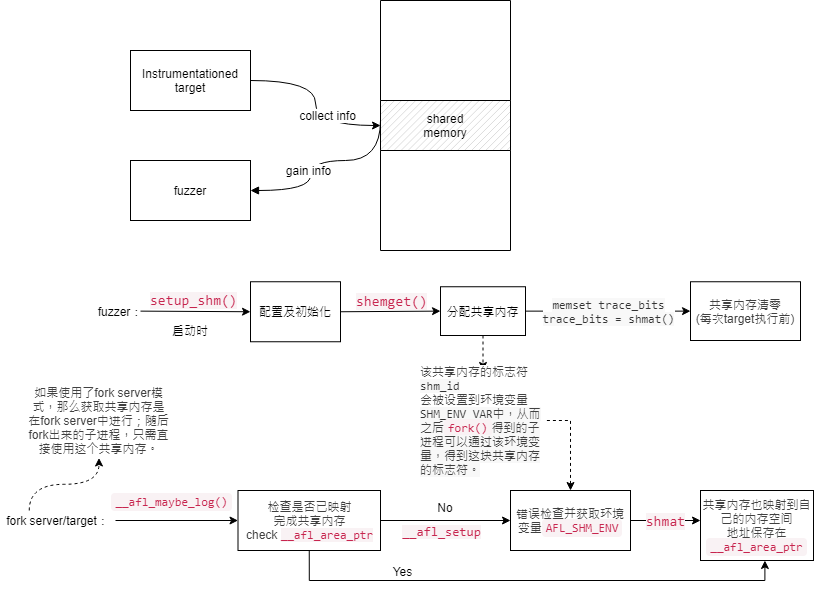
建议先阅读参考资料——Linux进程间通信(六)共享内存
AFL使用共享内存,来完成以上信息在fuzzer和target之间的传递。具体地,fuzzer在启动时,会执行setup_shm()方法进行配置。其首先调用shemget()分配一块共享内存,大小MAP_SIZE为64K:
shm_id = shmget(IPC_PRIVATE, MAP_SIZE, IPC_CREAT | IPC_EXCL | 0600);、
注:所有共享内存相关的函数都需要基于shmget返回的键值操作,即这里的shm_id。
分配成功后,该共享内存的标志符会被设置到环境变量中,从而之后fork()得到的子进程可以通过该环境变量,得到这块共享内存的标志符:
shm_str = alloc_printf("%d", shm_id);
if (!dumb_mode) setenv(SHM_ENV_VAR, shm_str, 1);并且,fuzzer本身,会使用变量trace_bits来保存共享内存的地址【shmat将共享内存从物理内存通过页表更新映射到虚拟内存,返回虚拟内存的地址,而这块共享内存将会用于记录代码分支覆盖率信息】:
trace_bits = shmat(shm_id, NULL, 0);在每次target执行之前,fuzzer首先将该共享内容清零:
memset(trace_bits, 0, MAP_SIZE); 接下来,我们再来看看target是如何获取并使用这块共享内存的。相关代码同样也在上面提到的方法__afl_maybe_log()中。首先,会检查是否已经将共享内存映射完成:
" /* Check if SHM region is already mapped. */\n"
"\n"
" movl __afl_area_ptr, %edx\n"
" testl %edx, %edx\n"
" je __afl_setup\n"__afl_area_ptr中保存的就是共享内存映射到target的内存空间中的地址,如果其不是NULL,便保存在ebx中继续执行【也就是意味着共享内存已经由fork server载入到了target子进程的虚存中】;否则进一步跳转到__afl_setup【即还未映射共享内存】。
__afl_setup处会做一些错误检查,然后获取环境变量AFL_SHM_ENV的内容并将其转为整型。查看其定义便可知,这里获取到的,便是之前fuzzer保存的共享内存的标志符。
"__afl_setup:\n"
"\n"
" /* Do not retry setup if we had previous failures. */\n"
"\n"
" cmpb $0, __afl_setup_failure\n"
" jne __afl_return\n"
"\n"
" /* Map SHM, jumping to __afl_setup_abort if something goes wrong.\n"
" We do not save FPU/MMX/SSE registers here, but hopefully, nobody\n"
" will notice this early in the game. */\n"
"\n"
" pushl %eax\n"
" pushl %ecx\n"
"\n"
" pushl $.AFL_SHM_ENV\n"
" call getenv\n"
" addl $4, %esp\n"
"\n"
" testl %eax, %eax\n"
" je __afl_setup_abort\n"
"\n"
" pushl %eax\n"
" call atoi\n"
" addl $4, %esp\n"最后,通过调用`shmat()`,target将这块共享内存也映射到了自己的内存空间中,并将其地址保存在`__afl_area_ptr`及`edx`中。由此,便完成了fuzzer与target之间共享内存的设置。
" pushl $0 /* shmat flags */\n"
" pushl $0 /* requested addr */\n"
" pushl %eax /* SHM ID */\n"
" call shmat\n"
" addl $12, %esp\n"
"\n"
" cmpl $-1, %eax\n"
" je __afl_setup_abort\n"
"\n"
" /* Store the address of the SHM region. */\n"
"\n"
" movl %eax, __afl_area_ptr\n"
" movl %eax, %edx\n"
"\n"
" popl %ecx\n"
" popl %eax\n"注记:如果使用了fork server模式,那么上述获取共享内存的操作,是在fork server中进行;随后fork出来的子进程,只需直接使用这个共享内存即可。
分支信息的记录
现在,用于通信的共享内存已准备完毕,接下来我们看看具体通信的是什么。
由官网文档可知,AFL是根据二元tuple(跳转的源地址和目标地址)来记录分支信息,从而获取target的执行流程和代码覆盖情况,其伪代码如下:
cur_location = <COMPILE_TIME_RANDOM>;
shared_mem[cur_location ^ prev_location]++;
prev_location = cur_location >> 1; //为什么要>>1,该节结尾会说
我们再回到方法__afl_maybe_log()中。上面提到,在target完成准备工作后,共享内存的地址被保存在寄存器`edx`中。随后执行以下代码:
"__afl_store:\n"
"\n"
" /* Calculate and store hit for the code location specified in ecx. There\n"
" is a double-XOR way of doing this without tainting another register,\n"
" and we use it on 64-bit systems; but it's slower for 32-bit ones. */\n"
"\n"
#ifndef COVERAGE_ONLY //该分支完成了伪代码的操作
" movl __afl_prev_loc, %edi\n" //获得prev_location
" xorl %ecx, %edi\n" //实现cur_location ^ prev_location
" shrl $1, %ecx\n" //实现cur_location >> 1;
" movl %ecx, __afl_prev_loc\n" //更新prev_location
#else
" movl %ecx, %edi\n"
#endif /* ^!COVERAGE_ONLY */
"\n"
#ifdef SKIP_COUNTS //不记录次数,只记录有无
" orb $1, (%edx, %edi, 1)\n"
#else //hash表累计
" incb (%edx, %edi, 1)\n"这里对应的便正是文档中的伪代码。
具体地,变量__afl_prev_loc保存的是前一次跳转的”位置”,其值与ecx做异或后,保存在edi中,并以edx(共享内存)为基址,对edi下标处进行加一操作。而ecx的值右移1位后,保存在了变量__afl_prev_loc中。
那么,这里的ecx,保存的应该就是伪代码中的cur_location了。
**回忆之前介绍代码插桩的部分:**
static const u8* trampoline_fmt_32 =
...
"movl $0x%08x, %%ecx\n"
"call __afl_maybe_log\n"在每个插桩处,afl-as会添加相应指令,将ecx的值设为0到MAP_SIZE之间的某个随机数,从而实现了伪代码中的cur_location = <COMPILE_TIME_RANDOM>;。
注意:由于在汇编生产二进制机器码之前,是通过fprintf来执行R(MAP_SIZE),因此写入/插入汇编代码时,就是 movl $0xkkkkk, %ecx,$0xkkkkk是在生成插桩汇编字符串时就确定的定值,而不是每次运行到插桩代码才重新计算出的R(MAP_SIZE),因此对于每段分支代码都是固定的key。
因此,AFL为每个代码块生成一个随机数,作为其“位置”的记录;随后,对分支处的”源位置“和”目标位置“进行异或,并将异或的结果作为该分支的key,保存每个分支的执行次数【也就是记录了边覆盖率】。
用于保存执行次数的实际上是一个哈希表,大小为MAP_SIZE=64K,当然会存在碰撞的问题;但根据AFL文档中的介绍,对于不是很复杂的目标,碰撞概率还是可以接受的:
Branch cnt | Colliding tuples | Example targets
------------+------------------+-----------------
1,000 | 0.75% | giflib, lzo
2,000 | 1.5% | zlib, tar, xz
5,000 | 3.5% | libpng, libwebp
10,000 | 7% | libxml
20,000 | 14% | sqlite
50,000 | 30% | -如果一个目标过于复杂,那么AFL状态面板中的map_density信息就会有相应的提示:
┬─ map coverage ─┴───────────────────────┤
│ map density : 3.61% / 14.13% │
│ count coverage : 6.35 bits/tuple │
┼─ findings in depth ────────────────────┤这里的map density,就是这张哈希表的密度。可以看到,上面示例中,该次执行的哈希表密度仅为3.61%,即整个哈希表差不多有95%的地方还是空的,所以碰撞的概率很小。不过,如果目标很复杂,map density很大,那么就需要考虑到碰撞的影响了。此种情况下的具体处理方式可见官方文档。
另外,比较有意思的是,AFL需要将cur_location右移1位后,再保存到prev_location中。官方文档中解释了这样做的原因:
- 假设target中存在
A->A和B->B这样两个跳转,如果不右移,那么这两个分支对应的异或后的key都是0,从而无法区分【但实际上这是不同的边覆盖。如果没有prev_location = cur_location >> 1,那么prev_location=cur_location,异或的结果为0;但是因为A和B不同,因此对于目标地址A/B的prev_location分别为A_location »1和B_location »1,产生的cur_location ^ prev_location不为0,且值不同】 - 另一个例子是
A->B和B->A,如果不右移,这两个分支对应的异或后的key也是相同的【A_location^B_location = B_location^A_location】。
由上述分析可知,之前提到的共享内存,被用于保存一张哈希表,target在这张表中记录每个分支的执行数量。随后,当target执行结束后,fuzzer便开始对这张表进行分析,从而判断代码的执行情况。【并在下一次fork之后,清空这张表,重新记录覆盖率信息】
分支信息的分析
首先,fuzzer对trace_bits(共享内存)进行预处理:
classify_counts((u32*)trace_bits);具体地,target是将每个分支的执行次数用1个byte来储存,而fuzzer则进一步把这个执行次数归入以下的buckets中:
static const u8 count_class_lookup8[256] = {
[0] = 0,
[1] = 1,
[2] = 2,
[3] = 4,
[4 ... 7] = 8,
[8 ... 15] = 16,
[16 ... 31] = 32,
[32 ... 127] = 64,
[128 ... 255] = 128
};举个例子,如果某分支执行了1次,那么落入第2个bucket,其计数byte仍为1;如果某分支执行了4次,那么落入第5个bucket,其计数byte将变为8,等等。
这样处理之后,对分支执行次数就会有一个简单的归类。例如,如果对某个测试用例处理时,分支A执行了32次;对另外一个测试用例,分支A执行了33次,那么AFL就会认为这两次的代码覆盖是相同的。当然,这样的简单分类肯定不能区分所有的情况,不过在某种程度上,处理了一些因为循环次数的微小区别,而误判为不同执行结果的情况。
随后,对于某些mutated input来说,如果这次执行没有出现崩溃等异常输出,fuzzer还会**检查其是否新增了执行路径**。具体来说,是对`trace_bits`计算hash并来实现:
u32 cksum = hash32(trace_bits, MAP_SIZE, HASH_CONST);通过比较hash值,就可以判断`trace_bits`是否发生了变化,从而判断此次mutated input是否带来了新路径,为之后的fuzzing提供参考信息。【通过归类,使得微小的差异被消解,大的执行次数差异才会体现出来,但是如果一个byte从无到有,那么很显然hash的值会产生改变】
总结
以上便是对AFL内部细节的一些分析整理,其实还有很多地方值得进一步深入去研究,例如AFL是如何判断一条路径是否是favorite的、如何对seed文件进行变化,等等。如果只是使用AFL进行简单的fuzzing,那么这些细节其实不需要掌握太多;但是如果需要在AFL的基础上进一步针对特定目标进行优化,那么了解AFL的内部工作原理就是必须的了。
参考资料
dup/dup2函数
APUE和man文档都用一句话简明的说出了这两个函数的作用:复制一个现存的文件描述符。
#include <unistd.h>
int dup(int oldfd);
int dup2(int oldfd, int newfd);123
当调用dup函数时,内核在进程中创建一个新的文件描述符,此描述符是当前可用文件描述符的最小数值,这个文件描述符指向oldfd所拥有的文件表项。
dup2和dup的区别就是可以用newfd参数指定新描述符的数值,如果newfd已经打开,则先将其关闭。如果newfd等于oldfd,则dup2返回newfd, 而不关闭它。dup2函数返回的新文件描述符同样与参数oldfd共享同一文件表项。
APUE用另外一个种方法说明了这个问题:
实际上,调用dup(oldfd)等效于,fcntl(oldfd, F_DUPFD, 0),而调用dup2(oldfd, newfd)等效于,close(oldfd);fcntl(oldfd, F_DUPFD, newfd);