Lab3
you will implement the basic kernel facilities required to get a protected user-mode environment (i.e., “process”) running.
You will enhance the JOS kernel to set up the data structures to keep track of user environments, create a single user environment, load a program image into it, and start it running.
You will also make the JOS kernel capable of handling any system calls the user environment makes and handling any other exceptions it causes.
综上,需要实现的基本内核功能如下:
- 进程运行
- 追踪用户环境
- 加载程序镜像
- 处理系统调用和异常
要完成lab3需要关注以下源文件:
inc/ env.h Public definitions for user-mode environments
trap.h Public definitions for trap handling
syscall.h Public definitions for system calls from user environments to the kernel
lib.h Public definitions for the user-mode support library
kern/ env.h Kernel-private definitions for user-mode environments
env.c Kernel code implementing user-mode environments
trap.h Kernel-private trap handling definitions
trap.c Trap handling code
trapentry.S Assembly-language trap handler entry-points
syscall.h Kernel-private definitions for system call handling
syscall.c System call implementation code
lib/ Makefrag Makefile fragment to build user-mode library, obj/lib/libjos.a
entry.S Assembly-language entry-point for user environments
libmain.c User-mode library setup code called from entry.S
syscall.c User-mode system call stub functions
console.c User-mode implementations of putchar and getchar, providing console I/O
exit.c User-mode implementation of exit
panic.c User-mode implementation of panic
user/ * Various test programs to check kernel lab 3 code
本实验由PartA和PartB两部分组成。
提交当前lab2修改的部分,并切换到lab3.
cd ~/lab
git commit -am 'changes to lab2 after handin'
Created commit 734fab7: changes to lab2 after handin
4 files changed, 42 insertions(+), 9 deletions(-)
git pull
Already up-to-date.
git checkout -b lab3 origin/lab3
Branch lab3 set up to track remote branch refs/remotes/origin/lab3.
Switched to a new branch "lab3"
git merge lab2
Merge made by recursive.
kern/pmap.c | 42 +++++++++++++++++++
1 files changed, 42 insertions(+), 0 deletions(-)
Part A: User Environments and Exception Handling
文件inc/env.h包含了JOS内核对用户环境【类似于用户进程】的基本定义,即内核使用Env数据结构来追踪每个用户环境。
在本实验中,最初只会创建一个环境,但您需要设计JOS内核以支持多个环境; lab4将通过允许用户环境fork其他环境来利用此功能。
用户环境变量
主要涉及inc/env.h和kern/env.c两个文件。前者是用户环境变量的变量定义,后者是有关的kern管理用户环境所需的变量。
// An environment ID 'envid_t' has three parts:
//
// +1+---------------21-----------------+--------10--------+
// |0| Uniqueifier | Environment |
// | | | Index |
// +------------------------------------+------------------+
// \--- ENVX(eid) --/
//
// The environment index ENVX(eid) equals the environment's index in the
// 'envs[]' array. The uniqueifier distinguishes environments that were
// created at different times, but share the same environment index.
//
// All real environments are greater than 0 (so the sign bit is zero).
// envid_ts less than 0 signify errors. The envid_t == 0 is special, and
// stands for the current environment.
#define LOG2NENV 10
#define NENV (1 << LOG2NENV) //JOS可同时管理的最大active environments数量
#define ENVX(envid) ((envid) & (NENV - 1)) //获取ENVX字段
environment ID标识了某种特定的环境,每个环境都有各自唯一的ID。可知一个environment ID有三个组成部分:
- environment index,即ENVX(eid),就是
envs[]数组的下标 - uniqueifier字段用于区别共享相同用户环境的、不同时间创建的环境【比如不同时间创建的父子进程】
- 第一个bit标识了环境的属性:
- 为0则表示当前环境
- 为负,非法
- 为正,表示所有的真实环境。
接下来就是kern管理用户环境所需的变量:
struct Env *envs = NULL; // All environments
struct Env *curenv = NULL; // The current env
static struct Env *env_free_list; // Free environment list
Once JOS gets up and running, the `envs` pointer points to an array of `Env` structures representing all the environments in the system.
the JOS kernel will support a maximum of NENV simultaneously active environments.
The JOS kernel keeps all of the inactive Env structures on the env_free_list.
- 这使得环境的分配和释放很简单,只需要从free list中删除或添加。
The kernel uses the curenv symbol to keep track of the currently executing environment at any given time. 【在启动过程中,在第一个环境被创建之前,这个字段一直保持NULL】
Environment State
Env结构在inc/env.h定义如下(将来的实验中将添加更多字段):
struct Env {
struct Trapframe env_tf; // Saved registers
struct Env *env_link; // Next free Env
envid_t env_id; // Unique environment identifier
envid_t env_parent_id; // env_id of this env's parent
enum EnvType env_type; // Indicates special system environments
unsigned env_status; // Status of the environment
uint32_t env_runs; // Number of times environment has run
// Address space
pde_t *env_pgdir; // Kernel virtual address of page dir
};
-
env_tf:
-
defined in
inc/trap.h存储未运行该环境时的寄存器数据:holds the saved register values for the environment while that environment is not running: i.e., when the kernel or a different environment is running.
-
内核会负责保存从用户模式到内核模式的寄存器数据,以便之后这个环境被重新启动时可以恢复到他被切换前的状态。
-
-
env_link:
env_free_list中的next指针- This is a link to the next
Envon theenv_free_list. env_free_listpoints to the first free environment on the list.
-
env_id:
- kernel会创建一个唯一标识某个环境的字段【uniquely identifiers】、
- 也就是
environment ID,该结构中有envs数组的index - After a user environment terminates, the kernel may re-allocate the same
Envstructure to a different environment - but the new environment will have a differentenv_idfrom the old one even though the new environment is re-using the same slot in the `envs` array. - 如果某个Env结构体被回收后重用了,这个env_id字段和之前的环境也不会相同,就是使用了相同的
envsarray slot【应该说的是environment ID的index一样,Uniqueifier也不同】。
-
env_parent_id:
- 存储了创建这个环境的父环境env_id
- In this way the environments can form a “family tree,”
- 这对于制定允许哪些环境对谁执行操作的相关安全决策很有用。
-
env_type:
-
用于区别特殊环境
-
For most environments, it will be
ENV_TYPE_USER. -
We’ll introduce a few more types for special system service environments in later labs.
-
// Special environment types enum EnvType { ENV_TYPE_USER = 0, };
-
-
env_status:
This variable holds one of the following values:
-
ENV_FREE: 不活跃状态,放置于env_free_listIndicates that the
Envstructure is inactive, and therefore on theenv_free_list. -
ENV_RUNNABLE:等待被调度Indicates that the
Envstructure represents an environment that is waiting to run on the processor. -
ENV_RUNNING:当前正在运行Indicates that the
Envstructure represents the currently running environment. -
ENV_NOT_RUNNABLE:active但没准备好被调度,可能在等待IO、IPCIndicates that the
Envstructure represents a currently active environment, but it is not currently ready to run: for example, because it is waiting for an interprocess communication (IPC) from another environment. -
ENV_DYING:zombie环境Indicates that the
Envstructure represents a zombie environment. A zombie environment will be freed the next time it traps to the kernel. We will not use this flag until Lab 4.
-
-
env_pgdir:
- This variable holds the kernel virtual address of this environment’s page directory.
- 存储了kernel管理环境的页目录
Like a Unix process, a JOS environment couples the concepts of “thread” and “address space”.
- The thread is defined primarily by the saved registers (the
env_tffield), - and the address space is defined by the page directory and page tables pointed to by
env_pgdir.
JOS environment和Unix的进程概念相似,需要保存页目录【context】以及寄存器值
To run an environment, the kernel must set up the CPU with *both* the saved registers and the appropriate address space.
Our struct Env is analogous to struct proc in xv6.
-
Both structures hold the environment’s (i.e., process’s) user-mode register state in a
Trapframestructure. -
struct PushRegs { /* registers as pushed by pusha */ uint32_t reg_edi; uint32_t reg_esi; uint32_t reg_ebp; //…… uint32_t reg_eax; } __attribute__((packed)); struct Trapframe { struct PushRegs tf_regs; uint16_t tf_es; uint16_t tf_padding1; uint16_t tf_ds; //c …… } __attribute__((packed)); //tarp.h中定义
In JOS, individual environments do not have their own kernel stacks as processes do in xv6. There can be only one JOS environment active in the kernel at a time, so JOS needs only a *single* kernel stack.
JOS只有一个内核栈,和xv6不同不是一个用户环境对应一个内核栈。
Allocating the Environments Array
在实验2中,我们实现了mem_init()为pages[]数组分配内存,用于记录哪些pages是free、哪些pages是alloc的。
Exercise1.现在我们需要修改mem_init():
- 分配
Env,大小为NENV - 然后需要把
envs分配到UENVS(defined ininc/memlayout.h) ,且mapped为可读,使得用户进程可以读取这个数组。
//位于/kern/pmap.c -> mem_init()
// Make 'envs' point to an array of size 'NENV' of 'struct Env'.
// LAB 3: Your code here.
envs = (struct Env*)boot_alloc(sizeof(struct Env)*NENV);
memset(envs,0,sizeof(struct Env)*NENV;
// Map the 'envs' array read-only by the user at linear address UENVS
// (ie. perm = PTE_U | PTE_P).
// Permissions:
// - the new image at UENVS -- kernel R, user R
// - envs itself -- kernel RW, user NONE
// LAB 3: Your code here.
boot_map_region(kern_pgdir,UENVS,ROUNDUP(NENV * sizeof(struct Env),PGSIZE),PADDR(envs),PTE_U);
完成这一步以后,内存的情况如下:
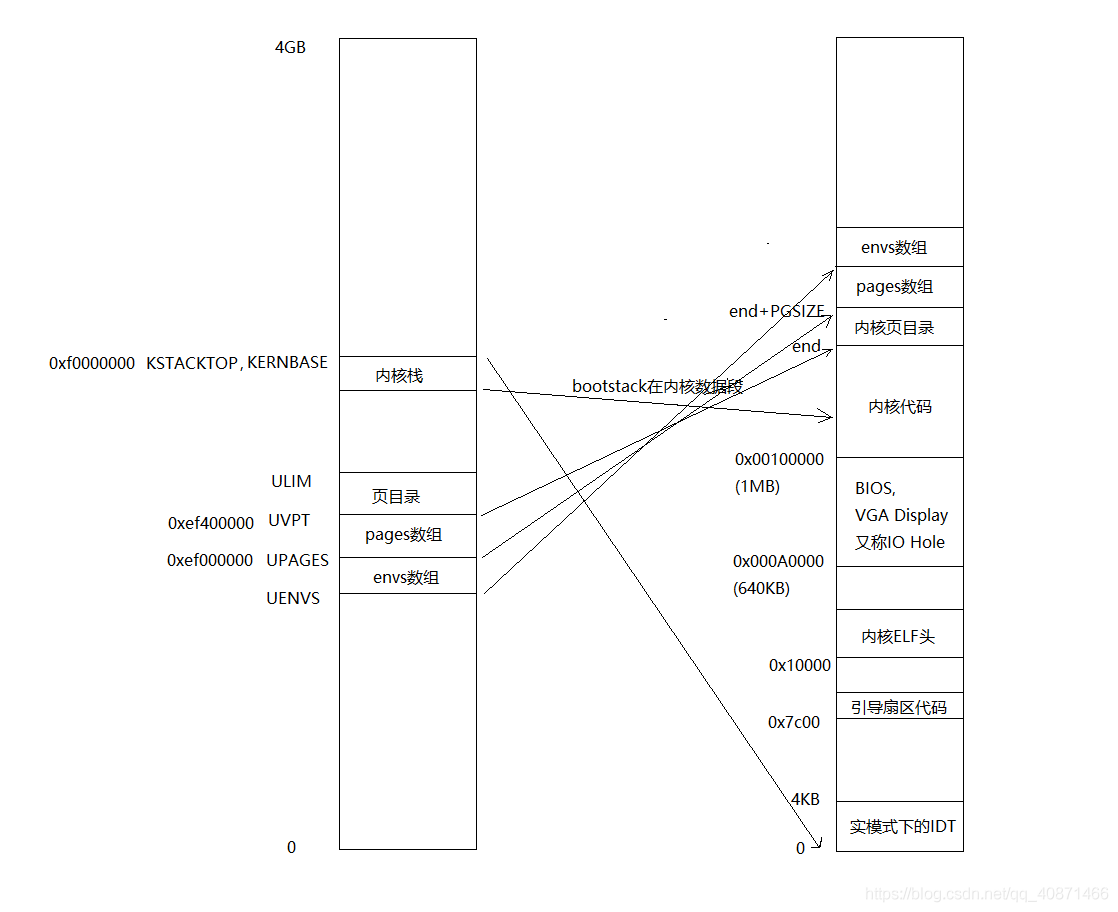
更全面一点:
同pages一样,这里需要在物理内存中为User Environments分配内存来保存Env信息,在Lab2中,在Boot Loader引导加载了内核数据以及代码之后,我们在其后给Kernel Page Directory和Page Info分配了物理内存。
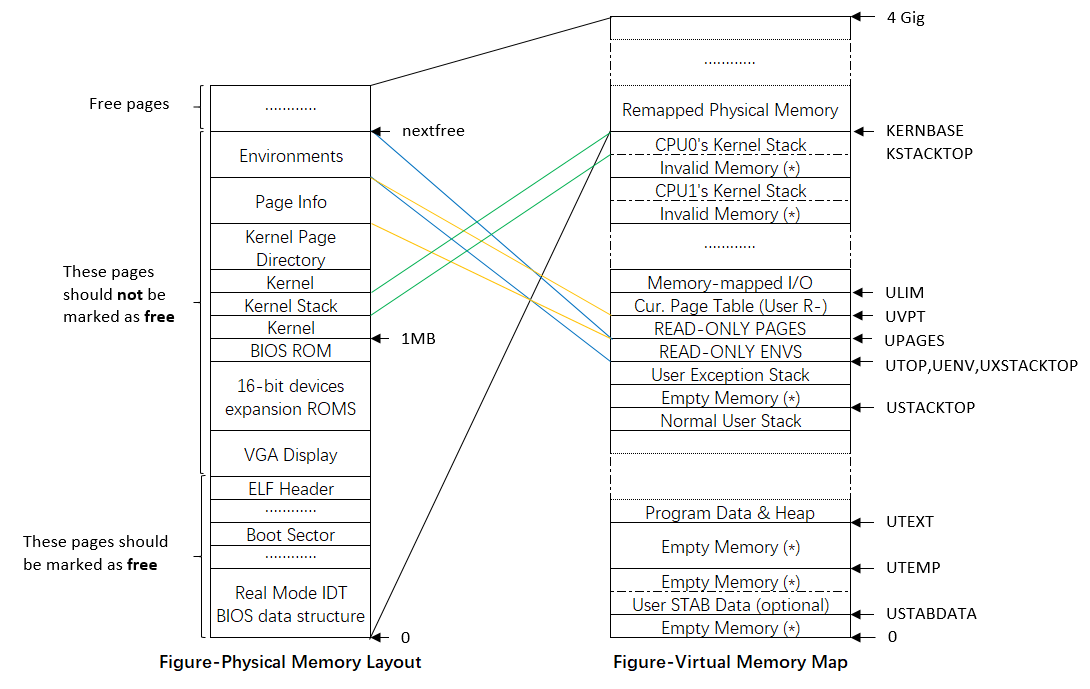
Exercise1实际上就是完成了上图Environments内存的分配,并且将其映射到了图示位置,按道理来说,envs此时应该指向Environments的起始地址,但是由于boot_alloc()返回的是虚拟地址,即实际的物理地址+KERNBASE,因此envs对应的实际物理内存地址需要用宏PADDR(envs)得到。(在KERNBASE之上映射了从0开始的最多2GB的物理内存空间!)
除此之外,还有几个细节部分:
- Kernel Page Directory的物理地址同样会保存在控制寄存器%cr3中,这样通过向%cr3控制寄存器写入不同的值,就能在User Page Directory和Kernel Page Directory之间切换了,并且能辅助实现用户环境的切换,因为正如许多操作系统课程所说,每个进程都会有一张独立的Page Directory,这也是后续的Exercise需要实现的。
- Cur.Page Table是每个User Program独有的Page Table,也就是说,当创建一个environment时,会使用
page_alloc()为该environment分配一页作为其独立的Page Table,并且将其映射到UVPT,同时将这种映射关系写入到每个environment独立的Page directory中,你可能注意到,并没有地方映射每个environment的Page directory,因此需要environment自己保留相应的page directory虚拟地址,在具体实现中就是Env结构体的env_pgdir指针了。
Creating and Running Environments
接下来,我们要在/kern/env.c完成一些代码以便于允许用户环境/用户进程。Because we do not yet have a filesystem, we will set up the kernel to load a static binary image that is embedded within the kernel itself. JOS embeds this binary in the kernel as a ELF executable image.
由于我们现在还没有文件系统,因此作者提前把一些binary静态编译之后嵌入了kernel中。考虑这种情况。比如内核里面需要包含一个独立的程序。但是内核本身就是一个大的程序。那么如何把这个小程序放到内核里面去。
The Lab 3 GNUmakefile generates a number of binary images in the obj/user/ directory. If you look at kern/Makefrag, you will notice some magic that “links” these binaries directly into the kernel executable as if they were .o files.
链接器命令行上的-b binary选项使这些文件链接为raw,即未解释的二进制文件,而不是作为编译器生成的常规.o文件。(就链接程序而言,这些文件根本不必是ELF,它们可以是任何东西,例如文本文件或图片!)
如果您在构建内核之后查看obj / kern / kernel.sym, 您会注意到,链接器“神奇地”产生了许多有趣的符号,它们的名称晦涩难懂,例如_binary_obj_user_hello_start,_binary_obj_user_hello_end和_binary_obj_user_hello_size。 链接器通过处理二进制文件的文件名来生成这些符号名。 这些符号为常规内核代码提供了一种引用嵌入式二进制文件的方式。
void
i386_init(void)
{
extern char edata[], end[];、
/*…… */
mem_init();
// Lab 3 user environment initialization functions
env_init();
trap_init();
/*…… */
// We only have one user environment for now, so just run it.
env_run(&envs[0]); //在kern/init.c中i386_init()函数运行了嵌入的kernel中的binary中某一个。但是在建立这个binary用户环境的关键函数还没有完全实现,下面需要完成他们。
}
Exercise2.在文件env.c中补足以下函数:
env_init():初始化envs数组中的所有结构体Env并把他们都加入env_free_list。调用env_init_percpu设置段寄存器,内核为特权级别0、用户为特权级别3。env_setup_vm():为每个用户环境(environment,即用户进程)设置页目录并初始化新用户环境的地址空间的kernel部分。region_alloc():为用户环境分配且映射物理内存。load_icode():解析ELF binary image【类似于boot loader的功能】,并且把它加载用户环境的用户地址空间中。env_create():使用env_alloc()分配用户环境,并且调用load_icode加载ELF binary到用户环境中。env_run():以用户模式启动允许给定的用户环境。
Tips:cprintf verb
%euseful – it prints a description corresponding to an error code. For example,r = -E_NO_MEM; panic("env_alloc: %e", r);will panic with the message “env_alloc: out of memory”.
env_init()
这个函数的作用很简单,就是完成如下功能。
// Mark all environments in 'envs' as free, set their env_ids to 0,
// 把env_ids = 0
// and insert them into the env_free_list.
// Make sure the environments are in the free list in the same order
// 注意顺序,链表的是顺序与数组的顺序是完全一致的。
// they are in the envs array (i.e., so that the first call to
// env_alloc() returns envs[0]).
// 比如第一次申请的时候,肯定拿到的是envs[0]
//
void
env_init(void)
{
memset(envs, 0, sizeof(envs));
env_free_list = NULL;
for (int i = NENV - 1; i >= 0; i--) {
envs[i].env_link = env_free_list;
env_free_list = &envs[i];
}
assert(env_free_list == envs);
// Per-CPU part of the initialization
env_init_percpu();
}
这里犯过的一个错误是
for (uint32_t i = NENV - 1; i >= 0; i--) {
}
这样操作,实际上是会造成溢出。这个循环也就会一直出问题。
env_setup_vm()
这个函数的功能实际上就是给进程分配页目录表。
//
// Initialize the kernel virtual memory layout for environment e.
// Allocate a page directory, set e->env_pgdir accordingly,
// and initialize the kernel portion of the new environment's address space.
// Do NOT (yet) map anything into the user portion
// of the environment's virtual address space.
//
// Returns 0 on success, < 0 on error. Errors include:
// -E_NO_MEM if page directory or table could not be allocated.
//
static int
env_setup_vm(struct Env *e)
{
int i;
struct PageInfo *p = NULL;
// Allocate a page for the page directory
if (!(p = page_alloc(ALLOC_ZERO)))
return -E_NO_MEM;
// Now, set e->env_pgdir and initialize the page directory.
//
// Hint:
// - The VA space of all envs is identical above UTOP
// (except at UVPT, which we've set below).
// See inc/memlayout.h for permissions and layout.
// Can you use kern_pgdir as a template? Hint: Yes.
// (Make sure you got the permissions right in Lab 2.)
// - The initial VA below UTOP is empty.
// - You do not need to make any more calls to page_alloc.
// - Note: In general, pp_ref is not maintained for
// physical pages mapped only above UTOP, but env_pgdir
// is an exception -- you need to increment env_pgdir's
// pp_ref for env_free to work correctly.
// - The functions in kern/pmap.h are handy.
// LAB 3: Your code here.
// 要点:高于UTOP的虚拟地址都是一样的。因为给内核用了。但是UVPT除外。
// 这里需要利用kern_pgdir作为一个模板
// 确保kern_pgdir里面的权限是正确设置的。
// 1. 小于UTOP的地址是空的
// 2. 不需要调用page_alloc
// 3. pp_ref高于UTOP的部分是不维护的。因为只有内核在用。
// 但是env_pgdir用到的页是个例外,因为可能其他进程的页表会引用到
// 所以需要p->pp_ref++;之后env_free时也要考虑到pp_ref。
e->env_pgdir = page2kva(p);
p->pp_ref++;
memcpy(e->env_pgdir, kern_pgdir, PGSIZE);
// UVPT maps the env's own page table read-only.
// Permissions: kernel R, user R
e->env_pgdir[PDX(UVPT)] = PADDR(e->env_pgdir) | PTE_P | PTE_U;
//换回指针需要重新设置
return 0;
}
注意这里也是像内核一样,把UVPT这块空间映射到了页目录表这里。通过这样一个映射。进程在查看自己的内存信息的时候,可以直接通过UVPT这个地址得到。这样可以发现,内核并没有提供一个叫get\_pgdir(void \*\*pgdir)这样的一个系统调用给用户进程。而是通过一种共享内存的方式来实现的。而在linux系统里面,很多信息则是通过/proc, /sysfs这两个文件系统接口来提供的。
region_alloc()
region_alloc函数的功能就是填充va起始的虚拟地址。并需要找到长度为len的物理内存地址来填满。设置虚拟地址和这段物理地址的映射关系。
函数总的来说,还是比较简单。毕竟只是一个lab。并不需要考虑页面不够的情况。
唯一需要处理的就是把地址对齐之后,然后一页一页地开始处理。
//
// Allocate len bytes of physical memory for environment env,
// and map it at virtual address va in the environment's address space.
// Does not zero or otherwise initialize the mapped pages in any way.
// Pages should be writable by user and kernel.
// Panic if any allocation attempt fails.
//
static void
region_alloc(struct Env *e, void *va, size_t len)
{
// LAB 3: Your code here.
// (But only if you need it for load_icode.)
//
// Hint: It is easier to use region_alloc if the caller can pass
// 'va' and 'len' values that are not page-aligned.
// You should round va down, and round (va + len) up.
// (Watch out for corner-cases!)
// 分配len字节的物理地址给进程env,并且要映射到虚拟地址va。
// 不要初始化这个映射的页面。
// 页面要可读,可写
// 如果分配失败要panic.
// region_alloc
void *v = ROUNDDOWN(va, PGSIZE);
size_t l = ROUNDUP(len, PGSIZE);
for (uint32_t i = 0; i < l; i += PGSIZE) {
struct PageInfo *p = page_alloc(0); //分配物理空间给进程
if (!p) {
panic("region_alloc :%e", -E_NO_MEM);
}
assert(!page_insert(e->env_pgdir, p, v, PTE_U | PTE_W)); //在用户环境e的页表中将物理页面映射到虚拟地址v中
v += PGSIZE;
// 不要溢出
assert(v > va && i < len);
}
}
注意对于溢出的检查和处理。
load_icode()
load_icode函数本身是用来加载整个程序的。因为程序是ELF格式的。
ELF里面提明了需要加载的段内存地址ph->p_va,要加载的段的长度ph->p_filesz等信息。
仔细读一下注释就可以把代码写出来。
//
// Set up the initial program binary, stack, and processor flags
// for a user process.
// 设置一个初始的程序代码段,栈,CPU标志位给用户程序。
// This function is ONLY called during kernel initialization,
// before running the first user-mode environment.
// 这个函数只会在内核初始化的时候被调用。并且是在第一次跳到用户
// 模式环境之前。
//
// This function loads all loadable segments from the ELF binary image
// into the environment's user memory, starting at the appropriate
// virtual addresses indicated in the ELF program header.
//
// 这个函数加载所有从ELF二进制里面可加载的段到用户环境的内存里面。
// 加载到合适的想到的虚拟地址那里去。
//
// At the same time it clears to zero any portions of these segments
// that are marked in the program header as being mapped
// but not actually present in the ELF file - i.e., the program's bss section.
//
// 同时这个程序也会把应该清0的段对应的内存进行清0操作。比如程序里面的
// bss段。
//
// All this is very similar to what our boot loader does, except the boot
// loader also needs to read the code from disk. Take a look at
// boot/main.c to get ideas.
//
// 实际上这个跟我们前面在bootloader里面做的事情是很像的。这个时候可以看
// 看boot/main.c。
//
// Finally, this function maps one page for the program's initial stack.
//
// 最后会加载一页做为程序初始的栈。
//
// load_icode panics if it encounters problems.
// - How might load_icode fail? What might be wrong with the given input?
// 在什么情况下load_icode会挂掉。
// 给定的输入可能会出啥问题。
//
static void
load_icode(struct Env *e, uint8_t *binary)
{
// Hints:
// Load each program segment into virtual memory
// at the address specified in the ELF segment header.
//
// ELF header里面记录了所有的段的信息。
//
// You should only load segments with ph->p_type == ELF_PROG_LOAD.
//
// 只加载:ph->p_type = ELF_PROG_LOAD
//
// Each segment's virtual address can be found in ph->p_va
// and its size in memory can be found in ph->p_memsz.
//
// 段的虚拟地址: ph->p_va
// 段大小: ph->p_memsz
//
// The ph->p_filesz bytes from the ELF binary, starting at
// 'binary + ph->p_offset', should be copied to virtual address
// ph->p_va.
//
// 段起始: binary + ph->p_offset
// 段长: ph->p_filesz
//
// Any remaining memory bytes should be cleared to zero.
// (The ELF header should have ph->p_filesz <= ph->p_memsz.)
//
// 清零段:ph->p_filesz <= ph->p_memsz
//
// Use functions from the previous lab to allocate and map pages.
//
// All page protection bits should be user read/write for now.
//
// 页权限: PTE_U | PTE_W
//
// ELF segments are not necessarily page-aligned, but you can
// assume for this function that no two segments will touch
// the same virtual page.
//
// ELF段不需要页对齐:不会有两个段指向同样的虚拟地址
//
// You may find a function like region_alloc useful.
//
// region_alloc有用
//
// Loading the segments is much simpler if you can move data
// directly into the virtual addresses stored in the ELF binary.
// So which page directory should be in force during
// this function?
//
// 加载段还是比较简单的,比如可以把数据直接从含有ELF虚拟地址空间复制过去。
//所以这个时候应该加载的是哪个页目录表?!!!【使用lcr3加载页目录,就是用户环境设置的那个页目录,在env_setup_vm()中初始化,以kernel_pgdir为模板,修改了UVPT部分】
//设置了当前使用的页目录,才可以把当前用户环境中的虚拟地址和物理地址的映射关系存储下来。
// You must also do something with the program's entry point,
// to make sure that the environment starts executing there.
// What? (See env_run() and env_pop_tf() below.)
//
// 你必须要利用program entry来做一些事情,以确保后面从这里开始执行。
// env_run & env_pop_tf().
// LAB 3: Your code here.
struct Elf *ELFHDR = (struct Elf*)binary;
assert(ELFHDR->e_magic == ELF_MAGIC);
struct Proghdr *ph, *eph;
// load each program segment (ignores ph flags)
ph = (struct Proghdr *) ((uint8_t *) ELFHDR + ELFHDR->e_phoff);
eph = ph + ELFHDR->e_phnum;
lcr3(PADDR(e->env_pgdir)); //设置页目录
for (; ph < eph; ph++) {
if (ph->p_type == ELF_PROG_LOAD) {
region_alloc(e, (void*)(ph->p_va), ph->p_memsz); //使用page_alloc分配物理空间,并设置虚拟地址ph->p_va和分配的物理地址的映射关系到e->env_pgdir中。
uint8_t *src = binary + ph->p_offset; //从binary文件中读取数据
uint8_t *dst = (uint8_t*)ph->p_va;
// 由于页面可能不是连续的,所以这里这种拷贝方式不工作
// uint8_t *dst = page2kva(page_lookup(e->env_pgdir, (void *)(ph->p_va), NULL));
memcpy(dst, src, ph->p_filesz); //上面只是设置了映射和分配了空间。真实的数据写入在这里。
if (ph->p_filesz < ph->p_memsz) {
memset(dst + ph->p_filesz, 0, ph->p_memsz - ph->p_filesz);
}
}
}
lcr3(PADDR(kern_pgdir)); //在用户环境e中映射完成binary后,回到kernel的页目录。【在kernel的环境视角没有映射binary的页表项】
e->env_tf.tf_eip = ELFHDR->e_entry; //切换回kernel环境后,设置用户环境e的寄存器eip为elf文件的entry。
// Now map one page for the program's initial stack
// at virtual address USTACKTOP - PGSIZE.
// LAB 3: Your code here.
region_alloc(e, (void*)(USTACKTOP - PGSIZE), PGSIZE); //为用户环境e分配栈的物理空间,并设置对应页映射。栈是向下增长的,因此从栈帧顶部UXSTACKTOP-PGSIZE最低地址分配,PGSIZE大小。
}
env_create()
该函数是上面实现函数的综合使用。创建一个进程描述符/用户环境e,并且映射binary。
//
// Allocates a new env with env_alloc, loads the named elf
// binary into it with load_icode, and sets its env_type.
// This function is ONLY called during kernel initialization,
// before running the first user-mode environment.
// The new env's parent ID is set to 0.
//
void
env_create(uint8_t *binary, enum EnvType type)
{
// LAB 3: Your code here.
struct Env *init_task = NULL;
// 必须成功
assert(!env_alloc(&init_task, 0)); //第二个参数为父用户环境的id
init_task->env_parent_id = 0;
init_task->env_type = type;
load_icode(init_task, binary);
}
这里就是申请一个进程描述符,然后把相应的代码加载上去。
env_run()
完成上下文切换:调度到用户进程上执行。
//
// Context switch from curenv to env e.
//从当前env切换到指定的env【也就是上下文切换】
// Note: if this is the first call to env_run, curenv is NULL.
//
// This function does not return.
//
void
env_run(struct Env *e)
{
// Step 1: If this is a context switch (a new environment is running):
// 1. Set the current environment (if any) back to
// ENV_RUNNABLE if it is ENV_RUNNING (think about
// what other states it can be in),
// 2. Set 'curenv' to the new environment,
// 3. Set its status to ENV_RUNNING,
// 4. Update its 'env_runs' counter,
// 5. Use lcr3() to switch to its address space.
// Step 2: Use env_pop_tf() to restore the environment's
// registers and drop into user mode in the
// environment.
// Hint: This function loads the new environment's state from
// e->env_tf. Go back through the code you wrote above
// and make sure you have set the relevant parts of
// e->env_tf to sensible values.
// LAB 3: Your code here.
if (curenv != NULL && curenv->env_status == ENV_RUNNING) {
curenv->env_status = ENV_RUNNABLE;
}
curenv = e;
curenv->env_status = ENV_RUNNING;
e->env_runs++;
lcr3(PADDR(e->env_pgdir));//加载新页表。
env_pop_tf(&(e->env_tf)); //从e->env_tf中加载新环境所需要的寄存器信息。
// panic("env_run not yet implemented");
}
这里其实就是做了一个非常简单的进程切换。把当前curenv进程切换到要运行的进程e上面。
过程还是比较简单,直接把页目录表加载上去之后,就开始跑了。
Below is a call graph of the code up to the point where the user code is invoked. Make sure you understand the purpose of each step.
以下是直至用户代码被调用之前的CG:
- start (kern/entry.S)
- i386_init (kern/init.c)
- cons_init
- mem_init
- env_init
- trap_init (still incomplete at this point)
- ENV_CREATE->env_create
- env_run
- env_pop_tf
完成后,您应该编译内核并在QEMU下运行它。 如果一切顺利,您的系统应进入用户空间并执行hello二进制文件,直到使用int指令进行系统调用为止。
注意:当
hello world打算退出的时候,就会调用sys_exit系统调用。中断还没有设置时,就会遇以保护错误。
遇到系统调用时,会有麻烦,因为JOS尚未设置硬件以允许从用户空间到内核的切换。 当CPU发现尚未设置该系统调用的中断处理函数时,它将生成一个常规保护异常【a general protection exception】,并发现它不能处理该异常,接着生成一个双重故障异常【a double fault exception】,但又发现它还是不能处理该异常, 最终放弃——“三重错误”【triple fault】。 通常,然后您会看到CPU复位和系统重启。 尽管这对于legacy applications很重要(see this blog post for an explanation of why),,但这对于内核开发是一件痛苦的事。因此,使用6.828 patched QEMU,您将看到寄存器转储和“三重错误”信息【a register dump and a “Triple fault.” message】。
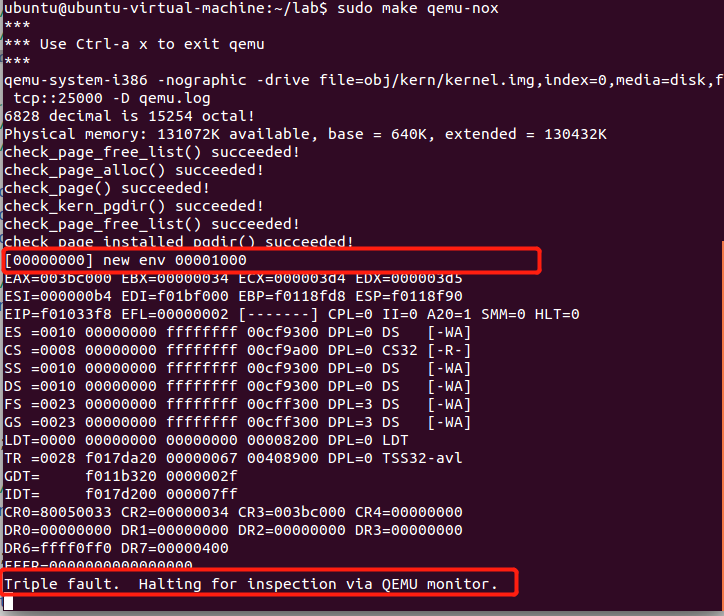
我们将在之后解决此问题,但是现在我们可以使用调试器检查是否进入了用户模式。
使用make qemu-gdb并在env_pop_tf处设置一个GDB断点,env_pop_tf应该是您在实际进入用户模式之前命中的最后一个函数。 然后使用si单步执行函数,CPU应在iret指令之后进入用户模式。
然后,您应该在用户环境的可执行文件中看到第一条指令——lib/entry.S文件中start标签处的cmpl指令。然后使用b *0x...在int $0x30处设置断点【是系统调用sys_cputs()产生的中断in hello (see obj/user/hello.asm for the user-space address)】
Handling Interrupts and Exceptions
int $0x30是用户空间的第一个系统调用。因此在i386_init()中调用env_init()->env_create()->env_run()之后就回不到内核态了。因此需要实现基本的异常和系统调用处理函数,以便内核可以从用户代码中恢复对处理器的控制。
在本实验中,我们通常会按照英特尔的术语来描述中断,异常等。但是,诸如异常,陷阱,中断,故障和中止之类的术语在多个不同的体系结构或操作系统之间是没有标准含义的,并且不考虑它们之间在特定架构上的细微差别。当您在本练习之外看到这些术语时,其含义可能会略有不同。
Exceptions and interrupts are both “protected control transfers,” which cause the processor to switch from user to kernel mode (CPL=0) without giving the user-mode code any opportunity to interfere with the functioning of the kernel or other environments.
In order to ensure that these protected control transfers are actually protected, the processor’s interrupt/exception mechanism is designed so that the code currently running when the interrupt or exception occurs does not get to choose arbitrarily where the kernel is entered or how. Instead, the processor ensures that the kernel can be entered only under carefully controlled conditions.
在X86上,有两种机制来处理异常或中断,以避免用户态代码随意进入内核的某个位置:
-
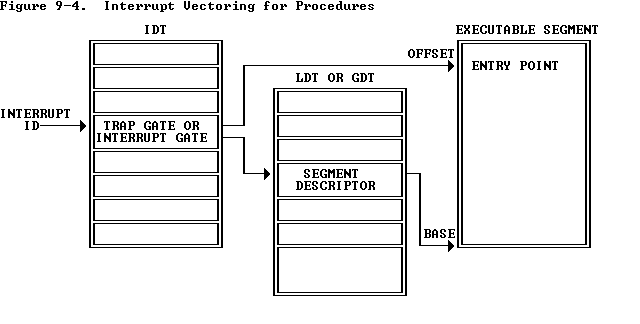
The Interrupt Descriptor Table(IDT)【详见:参考-中断和异常(Exceptions and Interrupts)】
- 类似于GDT,IDT表由内核在某一内核专用的内存中存储。From the appropriate entry in this table the processor loads:、
- 设置EIP到内核中对应的异常处理函数:the value to load into the instruction pointer (
EIP) register, pointing to the kernel code designated to handle that type of exception. - 设置CS中的处理异常的特权级:the value to load into the code segment (
CS) register, which includes in bits 0-1 the privilege level at which the exception handler is to run. (In JOS, all exceptions are handled in kernel mode, privilege level 0.)
-
TSS: 处理器需要一个位置来保存中断或异常发生之前的旧处理器状态,例如在处理器调用异常处理程序之前的
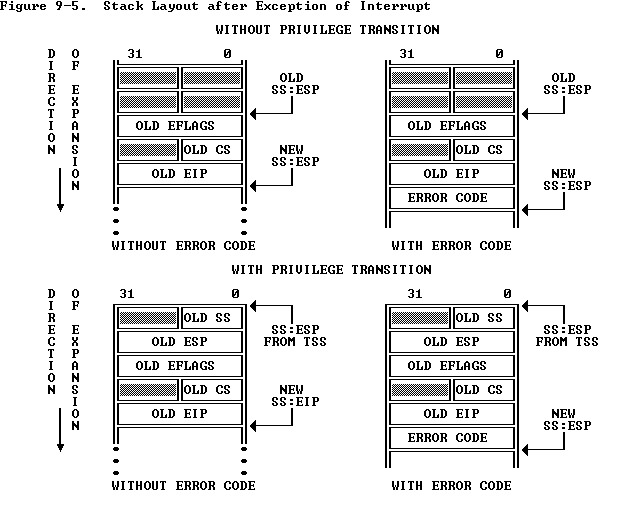
EIP和CS的原始值,以便异常处理程序可以恢复旧状态并从被中断的位置继续执行。但是,存储旧CPU状态的位置必须好好保护,避免受到非特权级用户代码的影响;否则,错误的或恶意的用户代码可能会损害内核。因此,当x86处理器执行中断或陷阱导致特权级别从用户模式更改为内核模式时,它还会切换到内核内存的栈中。当发生中断或异常时,处理器将旧的
SS,ESP,EFLAGS,CS,EIP和可选的错误代码(error code)push到这个新的内核栈上。一个称为任务状态段(TSS)的结构体指向了新的内核栈上存储了旧段选择器和和旧栈位置的地方。然后,处理器从中断描述符中加载CS和EIP,并将ESP和SS设置为新栈的位置。尽管TSS很大,可以用于多种用途,但是JOS仅使用它来定义内核栈【处理器从用户模式转换到内核模式时应切换到的内核栈】。由于在x86 JOS中,“内核模式”是特权级别0,处理器使用
ESP0和SS0的TSS字段在进入内核模式时定位内核栈。JOS不使用任何其他TSS字段。
Types of Exceptions and Interrupts
所有异常和不可屏蔽中断(NMI)使用IDT中0到31之间的中断向量【由处理器内部产生,如14号页错误】。31以上的中断向量是软件中断(INT指令)或外部设备产生的异步硬件中断。
在本节中,我们将扩展 JOS 来处理处理器内部生成的异常和NMI(对应IDT的0~31)。下一节将扩展JOS以处理48号中断向量【是一种软件中断】,JOS (随便选的一个号)将其作为系统调用中断向量。在实验4中,我们将扩展 JOS 来处理外部设备产生的硬件中断,例如时钟中断。
例子
假设处理器在用户环境中执行代码,遇到一个试图除以零的 divide 指令。
-
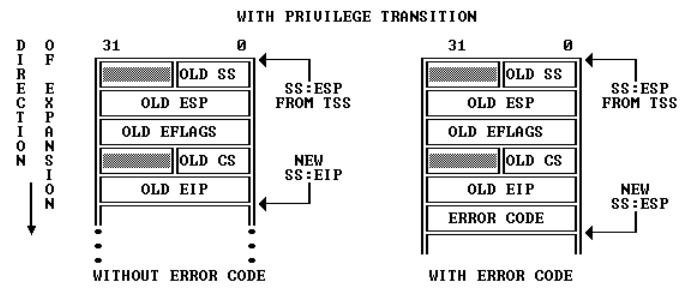
处理器首先进行栈帧切换,切换到内核栈【由TSS的SS0和ESP0字段来告知内核栈的位置,前者存储了
GD_KD=0x10【Kernel data的Global descriptor numbers】、后者存储了KSTACKTOP】 -
处理器push异常号到内核栈上【从
KSTACKTOP起始】+--------------------+ KSTACKTOP //存储旧信息到内核栈上[由TSS指向] | 0x00000 | old SS | " - 4 | old ESP | " - 8 | old EFLAGS | " - 12 | 0x00000 | old CS | " - 16 | old EIP | " - 20 <---- ESP -
由于我们在处理除0错误,在x86构架下对应的中断处理号为0,因此找到IDT中的entry 0得到处理函数,设置
CS:EIP指向这个处理函数。 -
由中断处理函数获得控制权,处理异常【如处理结果:终止用户环境】。
-
注意,处理上述图中在内核栈帧上push的五个word外,有时候还会push错误代码【error code】,可以参阅80386手册,以确定处理器为哪些异常号push错误代码【并不是都会push错误代码的】。
-
当处理器push一个错误代码的情况下,异常处理程序初始运行时,内核栈的情况如下所示:
+--------------------+ KSTACKTOP | 0x00000 | old SS | " - 4 | old ESP | " - 8 | old EFLAGS | " - 12 | 0x00000 | old CS | " - 16 | old EIP | " - 20 | error code | " - 24 <---- ESP +--------------------+
-
Nested Exceptions and Interrupts
CPU可以在内核模式或者用户模式接受异常和中断。但是只有从用户模式进入内核的时候,x86处理器会在push old寄存器信息之前先切换栈帧【切换成内核栈以后,才会push regs】,然后基于IDT调用合适的异常处理函数。如果处理器在中断或异常发生时已经处于内核模式(即CS 寄存器的低2位已经为零) ,那么 CPU 只是在同一个内核堆栈上推送更多的值【已经处于内核栈了,不需要再切换】,而且不需要push SS栈段寄存器和ESP。通过这种方式,内核可以很好地处理由内核本身内部代码引起的嵌套异常。
+--------------------+ <---- old ESP
| old EFLAGS | " - 4
| 0x00000 | old CS | " - 8
| old EIP | " - 12
+--------------------+
//如果需要,还会push error code
对于处理器的nested exception 处理能力,需要小心的是。如果处理器在内核模式下发生异常,并且由于缺少栈空间等原因无法将其旧状态推入内核栈,那么处理器就无法恢复,因此只能自行重置。内核的设计应该避免这种情况的发生。
Setting Up the IDT
通过上述了解,应该已经对JOS的IDT和异常处理有一些了解了。For now, you will set up the IDT to handle interrupt vectors 0-31 (the processor exceptions). We’ll handle system call interrupts later in this lab and add interrupts 32-47 (the device IRQs) in a later lab。
中断和异常相关的定义:
- inc/trap.h:definitions that may also be useful to user-level programs and libraries
- kern/trap.h:definitions that are strictly private to the kernel
Note: Some of the exceptions in the range 0-31 are defined by Intel to be reserved. Since they will never be generated by the processor【被intel保留,为CPU异常,OS不可用】, it doesn't really matter how you handle them. Do whatever you think is cleanest.
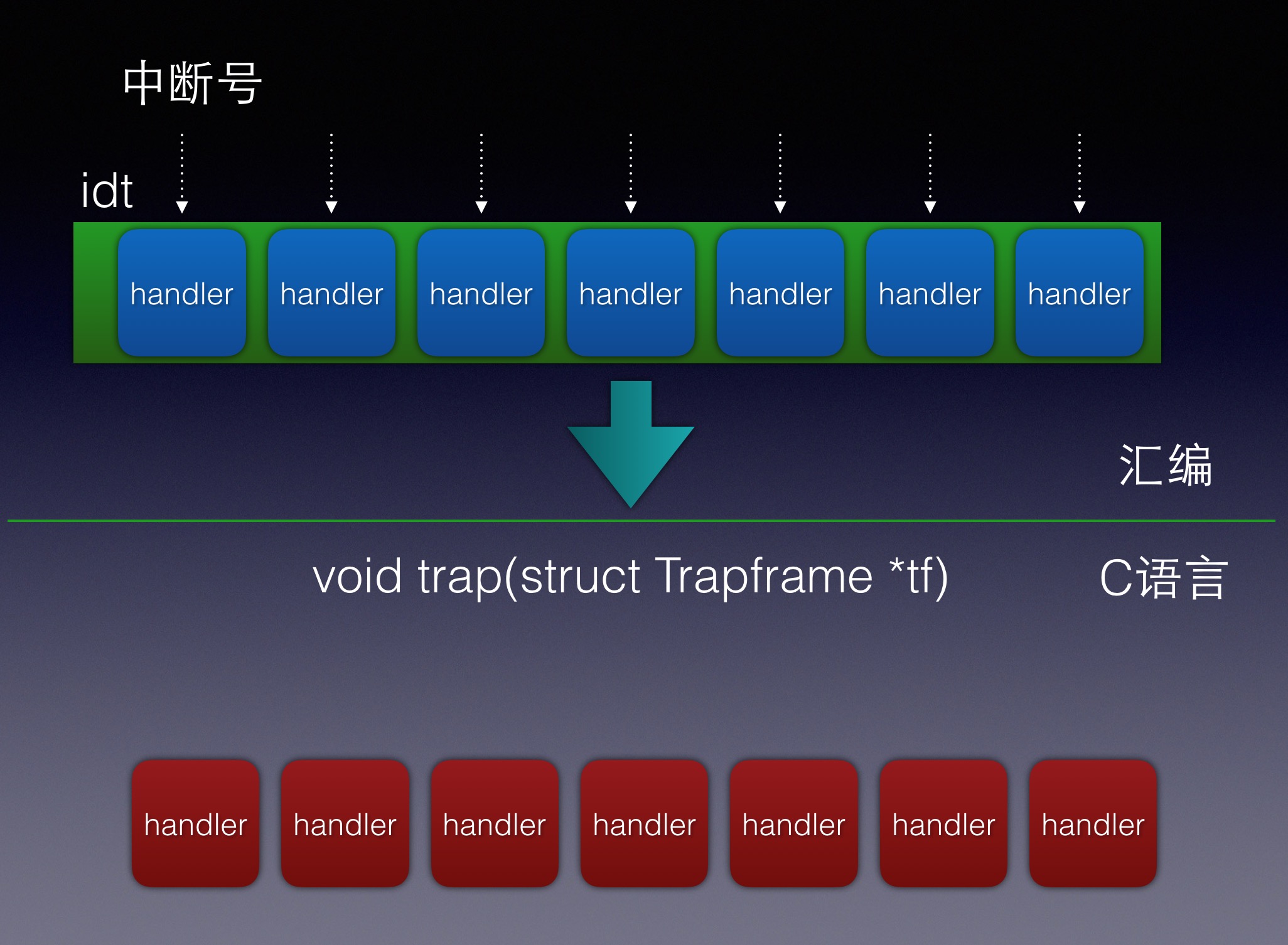
接下来需要实现的整体控制流如下:
IDT trapentry.S trap.c
+----------------+
| &handler1 |---------> handler1: trap (struct Trapframe *tf)
| | // do stuff {
| | call trap // handle the exception/interrupt
| | // ... }
+----------------+
| &handler2 |--------> handler2:
| | // do stuff
| | call trap
| | // ...
+----------------+
.
.
.
+----------------+
| &handlerX |--------> handlerX:
| | // do stuff
| | call trap
| | // ...
+----------------+
每一个异常或者中断都有自己的handler【在trapentry.S 中】,trap_init()应该使用这些handler的地址来初始化IDT表。每一个handler应该在栈上建立一个struct Trapframe结构体(详见inc/trap.h),然后使用指向这个Trapframe的指针为参数来调用trap(),之后trap()会来处理处理异常/中断或分配到特定的handler function。
Exercise 4. Edit
trapentry.Sandtrap.cand implement the features described above.
总结
基于上述了解,当发生中断的时候,要完成两件事:
- 切换到内核栈【本来在内核栈的话就不动】 => 通过TSS找到SS0、ESP0定位内核栈,push旧的状态:
SS,ESP,EFLAGS,CS,EIP和可选的错误代码(error code)到内核栈
如果是在ring 0,那么直接使用当前的ss/esp
如果是在ring 3, 那么使用当前tss段里面的ss0/esp0。然后开始压栈
- 定位到中断处理函数 => 根据中断ID号定位IDT中的表项得到GDT/LDT selector和offset,再到GDT/LDT中查找段描述符【CS、Limit】,确定代码段中的处理函数位置。

Exercise 4
首先查看kern/trap.h和inc/trap.h文件中的定义
- kern/trap.h:定义IDT表和trap_init()、page_fault_handler()等函数
- inc/trap.h:定义了中断号、IRQ号、PushRegs【pusha指令】以及Trapframe结构体
Edit trapentry.S
The macros
TRAPHANDLERandTRAPHANDLER_NOECintrapentry.Sshould help you, as well as the T_* defines ininc/trap.h. You will need to add an entry point intrapentry.S(using those macros) for each trap defined ininc/trap.h, and you’ll have to provide_alltrapswhich theTRAPHANDLERmacros refer to.
引入了这些头文件,因此.S中可能会用到这些头文件中的宏定义等。
#include <inc/mmu.h>
#include <inc/memlayout.h>
#include <inc/trap.h>
首先是TRAPHANDLER,定义了一个全局可见的函数,来处理trap。其功能如下:
- push a trap number to stack
- jump to _alltraps
#define TRAPHANDLER(name, num) \
.globl name; /* define global symbol for 'name' */ \
.type name, @function; /* symbol type is function */ \
.align 2; /* align function definition */ \
name: /* function starts here */ \
pushl $(num); \
jmp _alltraps
//,global定义了全局的名称name。类型是function。且是4字节对齐的。
//根据参数的情况决定了name的具体值,在程序中的表现就是标签。
// NAME(); 则跳转到这个name:继续执行
/*
You can declare the function with
* void NAME();
* where NAME is the argument passed to TRAPHANDLER.
*/
然后是TRAPHANDLER_NOEC【后缀表示NO ERROR CODE】,因此和前一个的函数的区别在于CPU会额外push 0,因此栈帧的布局是类似的。
#define TRAPHANDLER_NOEC(name, num) \
.globl name; \
.type name, @function; \
.align 2; \
name: \
pushl $0; \
pushl $(num); \
jmp _alltraps
Use TRAPHANDLER for traps where the CPU automatically pushes an error code.
Use TRAPHANDLER_NOEC for traps where the CPU doesn’t push an error code.
这两个宏的本意是用来声明中断处理函数的。这个时候可以根据硬件中断的描述【见附录】编写代码如下:
TRAPHANDLER_NOEC(T_DIVIDE_handler,T_DIVIDE) #0
TRAPHANDLER_NOEC(T_DEBUG_handler,T_DEBUG)
TRAPHANDLER_NOEC(T_NMI_handler,T_NMI)
TRAPHANDLER_NOEC(T_BRKPT_handler,T_BRKPT)
TRAPHANDLER_NOEC(T_OFLOW_handler,T_OFLOW)
TRAPHANDLER_NOEC(T_BOUND_handler,T_BOUND)
TRAPHANDLER_NOEC(T_ILLOP_handler,T_ILLOP)
TRAPHANDLER_NOEC(T_DEVICE_handler,T_DEVICE)
TRAPHANDLER(T_DBLFLT_handler,T_DBLFLT)
TRAPHANDLER(T_TSS_handler,T_TSS)
TRAPHANDLER(T_SEGNP_handler,T_SEGNP)
TRAPHANDLER(T_STACK_handler,T_STACK)
TRAPHANDLER(T_GPFLT_handler,T_GPFLT)
TRAPHANDLER(T_PGFLT_handler,T_PGFLT) #14
TRAPHANDLER_NOEC(T_FPERR_handler,T_FPERR)
TRAPHANDLER(T_ALIGN_handler, T_ALIGN)
TRAPHANDLER_NOEC(T_MCHK_handler, T_MCHK)
TRAPHANDLER_NOEC(T_SIMDERR_handler, T_SIMDERR)
TRAPHANDLER_NOEC(T_SYSCALL_handler, T_SYSCALL) #48。这里不要忘了系统调用号T_SYSCALL的设置。
接下来是TRAPHANDLER和TRAPHANDLER_NOEC中会使用到的_alltraps。
在进行到这一步的时候,已经完成了栈切换,处于异常处理过程中,然后通过TRAPHANDLER和TRAPHANDLER_NOEC决定是否push error code,因此现在的栈帧情况如下:
+--------------------+ KSTACKTOP
| 0x00000 | old SS | " - 4
| old ESP | " - 8
| old EFLAGS | " - 12
| 0x00000 | old CS | " - 16
| old EIP | " - 20
| [error code] | " - 24 <---- ESP
+--------------------+
然后进入了_alltraps,需要将Trapframe中剩下的元素push到栈上,然后调用trap。
回顾之前的分析整个操作系统的中断控制流程为:
- trap_init() 先将所有中断处理函数的起始地址放到中断向量表IDT中。
- 当中断发生时,不管是外部中断还是内部中断,处理器捕捉到该中断,进入内核态,根据中断向量去查询中断向量表IDT,找到对应的表项
- 保存被中断的程序的上下文
Trapframe到内核栈中,调用这个表项中指明的中断处理函数。- 每一个handler应该在栈上建立一个
struct Trapframe结构体(详见inc/trap.h),然后使用指向这个Trapframe的指针为参数来调用trap(),之后trap()会来处理处理异常/中断或分配到特定的handler function。
- 每一个handler应该在栈上建立一个
- 执行中断处理函数。
- 执行完成后,恢复被中断的进程的上下文,返回用户态,继续运行这个进程。
总的来说,_alltraps就是在完成栈帧切换后继续push完Trapframe中剩下的元素,并将Trapframe作为参数调用trap来处理异常。
//硬件栈是从上往下增长,一个结构体,最下面的元素是最先入栈。
struct Trapframe {
struct PushRegs tf_regs;
uint16_t tf_es;
uint16_t tf_padding1;
uint16_t tf_ds;
uint16_t tf_padding2; //从这里开始继续push
uint32_t tf_trapno; //显然根据当前栈帧的情况,已经push到这里了【以下已经push完了】
//tarpno就是之前的宏push的num,中断号。
/* below here defined by x86 hardware */
//这些元素,有些是硬件压入栈的。有些是两个宏压入栈的。
uint32_t tf_err;
uintptr_t tf_eip;
uint16_t tf_cs;
uint16_t tf_padding3;
uint32_t tf_eflags;
/* below here only when crossing rings, such as from user to kernel */
//以下在栈帧切换的时候已经push了【如果没有切换就不会push,详见附录】
uintptr_t tf_esp;
uint16_t tf_ss;
uint16_t tf_padding4;
} __attribute__((packed));
因此在transentry.S中接着写:
/*
* 注意压栈的顺序是从struct Trapframe的底部往上压
* 看一下前面的宏,已经压参数,压到了tf_trapno这里了。
* 注意:使用pusha指令
*/
_alltraps:
/*
* 注意这里直接用了pushl前面自动补0【pushw是16bits】
* 如果要严格的对应
* - pushw $0 //tf_padding2
* - pushw %ds //tf_ds
* - pushw $0 //tf_padding1
* - pushw %es //tf_es
*/
pushl %ds
pushl %es
pushal //tf_regs【所有通用寄存器】
/*
* 这里是因为后面要调用trap函数
* 1.
* trap函数的定义是trap(struct Trapframe *tf)
* 参数是一个指针,因此把刚刚push进去的Trapframe结构体的首地址【也就是当前栈顶】传进去。
* 这个时候压入pushl %esp这个寄存器的内容。
* 也就刚好是真正的指向struct Trapframe这个object的起始地址
* 2.
* 如果trap函数的定义是trap(struct Trapframe tfObject)
* 那么这个pushl %esp是没有必要压进去的
*/
pushl %esp
/*然后指向内核数据段
* 硬件上中断门描述符进来的时候
* 已经把CPU设置成了GD_KT也就是内核代码段。【目前还没有实现,后面会在trap_init中体现】
* 这个是硬件操作
*/
movw $GD_KD, %ax //$GD_KD为 kernel data的Global descriptor numbers【selector】
movw %ax, %ds //段寄存器的大小为16bits【虽然还有隐藏的部分,用于缓存描述符】
movw %ax, %es //彻底完成内核模式的转换
call trap
/* 操作完成之后,
* 没有必要要按照反方向的顺序返回
* 因为trap函数最终会走到env_pop_tf()这个函数
* movl $tf, %esp
* popal
* popl %es
* popl %ds
* addl $0x08, %esp
* iret
*/
到这里位置,我们已经完成了以下要求:
Your
_alltrapsshould:
- push values to make the stack look like a struct Trapframe
- load
GD_KDinto%dsand%espushl %espto pass a pointer to the Trapframe as an argument to trap()call trap(cantrapever return?)
Edit trap_init()
现在我们剩下一项工作:
You will also need to modify trap_init() to initialize the idt to point to each of these entry points defined in trapentry.S; the SETGATE macro will be helpful here.
就是在trap_init()中初始化IDT表,用上我们在trapentry.S中定义的handler entries。
在kern/trap.c中,定义了IDT表:
/* Interrupt descriptor table. (Must be built at run time because
* shifted function addresses can't be represented in relocation records.)
*/
struct Gatedesc idt[256] = { { 0 } };
struct Pseudodesc idt_pd = {
sizeof(idt) - 1, (uint32_t) idt
};
这里的IDT就是存放256个中断描述符的地方,现在要在trap_init的时候,把在trapentry.S中定义的中断描述符填上去。
填补中断描述符的时候会用到SETGATE:
// Set up a normal interrupt/trap gate descriptor.
//这个函数是用于设置一个中断门描述或者陷阱门描述符【详见附录】
//简单来说,中断门和陷阱门描述中断/异常处理程序的入口点。
//第一个参数就是用来区别中断门和陷阱门类型的。两者的差异在于IF标志。
//中断门清除了IF标志,从而关闭了将来会发生的可屏蔽中断。
// - istrap: 1 for a trap (= exception) gate, 0 for an interrupt gate.
// see section 9.6.1.3 of the i386 reference: "The difference between
// an interrupt gate and a trap gate is in the effect on IF (the
// interrupt-enable flag). An interrupt that vectors through an
// interrupt gate resets IF, thereby preventing other interrupts from
// interfering with the current interrupt handler. A subsequent IRET
// instruction restores IF to the value in the EFLAGS image on the
// stack. An interrupt through a trap gate does not change IF."
//设置为了handler设置代码段寄存器。
// - sel: Code segment selector for interrupt/trap handler
// - off: Offset in code segment for interrupt/trap handler
// - dpl: Descriptor Privilege Level -
// the privilege level required for software to invoke
// this interrupt/trap gate explicitly using an int instruction.
#define SETGATE(gate, istrap, sel, off, dpl) \
{ \
(gate).gd_off_15_0 = (uint32_t) (off) & 0xffff; \
(gate).gd_sel = (sel); \
(gate).gd_args = 0; \
(gate).gd_rsv1 = 0; \
(gate).gd_type = (istrap) ? STS_TG32 : STS_IG32; \
(gate).gd_s = 0; \
(gate).gd_dpl = (dpl); \
(gate).gd_p = 1; \
(gate).gd_off_31_16 = (uint32_t) (off) >> 16; \
}
了解了SETGATE之后,我们在trap_init中填补IDT表:
void
trap_init(void)
{
extern struct Segdesc gdt[];
// LAB 3: Your code here.
void T_DIVIDE_handler();
void T_DEBUG_handler();
void T_NMI_handler();
void T_BRKPT_handler();
void T_OFLOW_handler();
void T_BOUND_handler();
void T_ILLOP_handler();
void T_DEVICE_handler();
void T_DBLFLT_handler();
void T_TSS_handler();
void T_SEGNP_handler();
void T_STACK_handler();
void T_GPFLT_handler();
void T_PGFLT_handler();
void T_FPERR_handler();
void T_ALIGN_handler();
void T_MCHK_handler();
void T_SIMDERR_handler();
void T_SYSCALL_handler();
//GD_KT为kernel text的Global descriptor numbers
//也就说明了中断和异常都是在内核态的代码段进行的处理的。
//第四个参数T_DIVIDE_handler是代码段中的offset,对应了trapentry.S中的label
//最后一个参数是可以触发这种异常的级别,一般都是ring0,除了系统调用是ring3
SETGATE(idt[T_DIVIDE], 0, GD_KT, T_DIVIDE_handler, 0);
SETGATE(idt[T_DEBUG], 0, GD_KT, T_DEBUG_handler, 0);
SETGATE(idt[T_NMI], 0, GD_KT, T_NMI_handler, 0);
SETGATE(idt[T_BRKPT], 1, GD_KT, T_BRKPT_handler, 0); //trap门
SETGATE(idt[T_OFLOW], 1, GD_KT, T_OFLOW_handler, 0); //trap门【详见附录中断号具体描述】
SETGATE(idt[T_BOUND], 0, GD_KT, T_BOUND_handler, 0);
SETGATE(idt[T_ILLOP], 0, GD_KT, T_ILLOP_handler, 0);
SETGATE(idt[T_DEVICE], 0, GD_KT, T_DEVICE_handler, 0);
SETGATE(idt[T_DBLFLT], 0, GD_KT, T_DBLFLT_handler, 0);
SETGATE(idt[T_TSS], 0, GD_KT, T_TSS_handler, 0);
SETGATE(idt[T_SEGNP], 0, GD_KT, T_SEGNP_handler, 0);
SETGATE(idt[T_STACK], 0, GD_KT, T_STACK_handler, 0);
SETGATE(idt[T_GPFLT], 0, GD_KT, T_GPFLT_handler, 0);
SETGATE(idt[T_PGFLT], 0, GD_KT, T_PGFLT_handler, 0);
SETGATE(idt[T_FPERR], 0, GD_KT, T_FPERR_handler, 0);
SETGATE(idt[T_ALIGN], 0, GD_KT, T_ALIGN_handler, 0);
SETGATE(idt[T_MCHK], 0, GD_KT, T_MCHK_handler, 0);
SETGATE(idt[T_SIMDERR], 0, GD_KT, T_SIMDERR_handler, 0);
SETGATE(idt[T_SYSCALL], 1, GD_KT, T_SYSCALL_handler, 3);
// Per-CPU setup
trap_init_percpu();
}
// Initialize and load the per-CPU TSS and IDT
void
trap_init_percpu(void)
{
// Setup a TSS so that we get the right stack
// when we trap to the kernel.
ts.ts_esp0 = KSTACKTOP; //设置了TSS中存储的内核栈段信息
ts.ts_ss0 = GD_KD;
ts.ts_iomb = sizeof(struct Taskstate);
// Initialize the TSS slot of the gdt.
gdt[GD_TSS0 >> 3] = SEG16(STS_T32A, (uint32_t) (&ts),
sizeof(struct Taskstate) - 1, 0);
gdt[GD_TSS0 >> 3].sd_s = 0;
// Load the TSS selector (like other segment selectors, the
// bottom three bits are special; we leave them 0)
ltr(GD_TSS0); //TR寄存器指向TSS任务描述符
// Load the IDT
lidt(&idt_pd); //idt表入口和idt大小
}
到这里就完了IDT表的设置和异常处理的入口了。
可以进行user目录下会产生异常的程序的一些测试,如user/divzero。
You should be able to get make grade to succeed on the divzero, softint, and badsegment tests at this point。
这个时候可以总结一下了。
- 发生中断或者trap,从LIDT(load IDT寄存器)里面找到IDT。
- 根据中断号找到这一项,即IDT[中断号]
- 根据IDT[中断号],eg: SETGATE(idt[T_MCHK], 0, GD_KT, T_MCHK_handler, 0); 取出当时设置的中断处理函数
- 跳转到中断函数T_MCHK_handler。
- 中断处理函数再跳转到trap函数。
- trap函数再根据Trapframe中的tf->trapno中断号来决定分发给哪个函数。
- 之后会实现
trap_dispatch分发中断。
- 之后会实现
也就是如下图:
Challenge
参考:https://qinstaunch.github.io/2020/01/16/MIT-6-828-LAB3-User-Environments/#OSELAB3_B.6.Question【这里说的Question解答也很好】
Question
-
What is the purpose of having an individual handler function for each exception/interrupt? (i.e., if all exceptions/interrupts were delivered to the same handler, what feature that exists in the current implementation could not be provided?)
不同的中断需要的操作是不同的;特别是error code,有的压入,有的不压入,如果用同一个handler处理,需要两套Trapframe结构体,并且需要特判,增加了程序的复杂度。最最关键的,我们无法得知trapno,也就无法判断到底发生了啥中断,无法做分发。
-
Did you have to do anything to make the
user/softintprogram behave correctly? The grade script expects it to produce a general protection fault (trap 13), butsoftint’s code saysint $14. Why should this produce interrupt vector 13? What happens if the kernel actually allowssoftint’sint $14instruction to invoke the kernel’s page fault handler (which is interrupt vector 14)?答:Because the current system(user/softint) is running on user mode, 特权级DPL is 3. But INT instruction is system instruction, its privilege is 0. The user cannot invoke
int $14, thus leading to General Protection(trap 13)。所有的gate中,除了系统调用门,其他的门,都只允许从特权级进入。在本程序试图进入14号特权门的时候,检查发现特权级不够,所以触发了一般保护错误。这样的设计是合理的,因为一旦允许用户自行触发缺页错误,操作系统将会很容易被攻击【莫名提升了权限】。
/usr/softint直接触发了14号中断缺页错误,但是该程序运行在用户态下,特权级为3,而INT $14特权级为0,这会引发General Protection Exception。除了系统调用外其他中断不允许直接由用户程序触发。// buggy program - causes an illegal software interrupt #include <inc/lib.h> void umain(int argc, char **argv) { asm volatile("int $14"); // page fault }
参考
lab报告
- https://linux.cn/article-10307-1.html
- https://zhuanlan.zhihu.com/p/74028717
- https://jiyou.github.io/blog/2018/04/28/mit.6.828/jos-lab3/
推荐的github仓库及解析:
- https://github.com/SimpCosm/6.828
- https://github.com/clann24/jos
- https://github.com/SmallPond/MIT6.828_OS
- https://github.com/shishujuan/mit6.828-2017
中断和异常(Exceptions and Interrupts)
The difference between interrupts and exceptions is that interrupts are used to handle asynchronous events external to the processor, but exceptions handle conditions detected by the processor itself in the course of executing instructions.
There are two sources for external interrupts and two sources for exceptions:
- Interrupts
- Maskable interrupts, which are signalled via the INTR pin.【可屏蔽中断】
- Nonmaskable interrupts, which are signalled via the NMI (Non-Maskable Interrupt) pin.【不可屏蔽中断】
- Exceptions
- Processor detected. These are further classified as faults, traps, and aborts.
- 根据异常报告的方式和是否重启异常指令来进行细分。
- Faults:reported “before” the instruction causing the exception + permits the instruction to be restarted.
- Traps:reported at the instruction boundary immediately after the instruction in which the exception was detected.
- Aborts:permits neither precise location of the instruction causing the exception nor restart of the program that caused the exception.
- Programmed. The instructions INTO, INT 3, INT n, and BOUND can trigger exceptions. These instructions are often called “software interrupts”, but the processor handles them as exceptions.
- Processor detected. These are further classified as faults, traps, and aborts.
不可屏蔽中断和异常的异常标识符为0~31;可屏蔽中断的异常控制器由外部中断控制器来负责分配,范围为32~255。
Interrupt and Exception ID Assignments
Identifier Description
0 Divide error
1 Debug exceptions
2 Nonmaskable interrupt
3 Breakpoint (one-byte INT 3 instruction)
4 Overflow (INTO instruction)
5 Bounds check (BOUND instruction)
6 Invalid opcode
7 Coprocessor not available
8 Double fault
9 (reserved)
10 Invalid TSS
11 Segment not present
12 Stack exception
13 General protection
14 Page fault
15 (reserved)
16 Coprecessor error
17-31 (reserved)
32-255 Available for external interrupts via INTR pin
----------------------------------------------------------
Priority Among Simultaneous Interrupts and Exceptions
Priority Class of Interrupt or Exception【优先级情况】
HIGHEST Faults except debug faults
Trap instructions INTO, INT n, INT 3
Debug traps for this instruction
Debug faults for next instruction
NMI interrupt
LOWEST INTR interrupt
处理器仅在一条指令的结束与下一条指令的开始之间处理中断和异常。
当处理不可屏蔽中断NMI时,会忽略其他的NMI信号,直到iret指令完成;而在处理可屏蔽中断INTR时,根据IF flags的情况【指令CLI和STI等可以改变IF flags】来决定是否可以接收外部中断。而EFFLAGS寄存器中的RF标志位可以用于设置debug faults,用于指令调试。
中断描述符表(IDT)将每个中断或异常标识符与服务于相关事件的指令的描述符相关联。
The interrupt descriptor table (IDT) associates each interrupt or exception identifier with a descriptor for the instructions that service the associated event。
每个条目的大小为8字节,一共支持256个条目,且index为中断/异常ID*8。
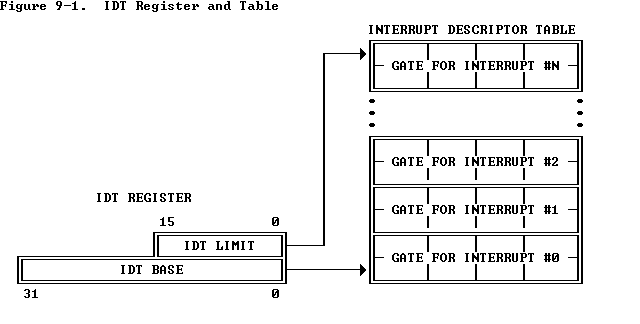
中断向量表/中断描述符表IDT可以位于物理内存的任何位置,且由IDTR寄存器来标识位置【指令LIDT和SIDT用于操作IDT,指令的操作数由两部分组成:高6字节为IDT的base addr,低2字节为IDT的Limit长度】。
- LIDT (Load IDT register) loads the IDT register with the linear base address and limit values contained in the memory operand. This instruction can be executed only when the CPL is zero. It is normally used by the initialization logic of an operating system when creating an IDT. An operating system may also use it to change from one IDT to another.
- SIDT (Store IDT register) copies the base and limit value stored in IDTR to a memory location. This instruction can be executed at any privilege level.
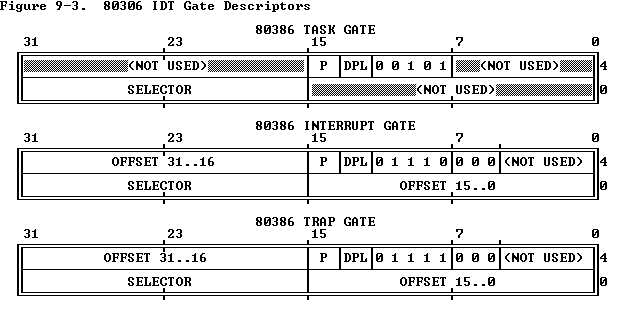
IDT条目可以是三种类型的描述符:Task gates、Interrupt gates、Trap gates。
中断处理:中断门会指示中断处理程序,这个中断处理程序将会在现在所执行任务的上下文内被调用。过程如下:捕获到的中断ID用于索引IDT,在IDT表项——中断门中找到selector作为GDT+LDT的索引,从而找到可执行段基地址,再加上中断门中的Offset字段确定中断处理程序的入口。
中断处理过程也使用stack来存储返回到原始程序所需的信息。当中断处理程序执行完,从栈帧中弹出存储的信息,从而回到原始程序【使用iret指令,还会pop出eflags寄存器】。
图中的Error Code主要包含了SELECTOR index。根据最低的几个标志位的不同,决定索引的表项是IDT【得到门描述符】还是直接索引GDT/LDT。
如果有权限的变化,就是需要压入old ss、old esp等
中断号具体描述
:id :type :errorCode :info
:0 :Fault :No :Divide Error
:1 :Fault/Trap :No :Debug Exception
:2 :Interrupt :No :NMI Interrupt
:3 :Trap :No :Breakpoint
:4 :Trap :No :Overflow
:5 :Fault :No :Bound Check
:6 :Fault :No :Illegal Opcode
:7 :Fault :No :Device Not available
:8 :Abort :Yes :Double Fault
:10 :Fault :Yes :Invalid TSS
:11 :Fault :Yes :Segment Not Present
:12 :Fault :Yes :Stack Exception
:13 :Fault :Yes :General Protection Fault
:14 :Fault :Yes :Page Fault
:16 :Fault :No :Floating Point Error
:17 :Fault :Yes :Alignment Check
:18 :Abort :No :Machine Check
:19 :Fault :No :Simd Floating Point Error
硬件中断IRQ
中断既然是体系结构的机制,就需要有硬件支持。x86由2个8259A芯片级联支持,支持16种硬件产生的中断,通过IRQ n表示,IRQ就是中断号,又有被称为中断线,是硬件中断独有的。
1、0~31:处理cpu异常和非屏蔽中断,它实际上被Intel保留,操作系统不可使用。
2、32~127:由外部硬件触发,它又分为可屏蔽中断(INTR)和非可屏蔽中断(NMI)。
3、128:linux用于系统,当执行int 0x80时,就会陷入内核态执行system_call。
对于硬件中断来说,中断向量号 = IRQ + 32,因为前31个是cpu异常。IRQ0对应的中断向量号是32(0x20)。

参考:https://zhuanlan.zhihu.com/p/80903637
中断描述符类型
IDT包含三种类型的中断描述符:任务门、中断门、陷阱门。
参考:https://pdos.csail.mit.edu/6.828/2018/readings/i386/s09_05.htm
Intel 80386中文手册:https://www.kancloud.cn/wizardforcel/intel-80386-ref-manual/123813
TSS:https://blog.csdn.net/MJ_Lee/article/details/104419980
任务门(task gate)
当中断信号发生时,必须取代当前进程的那个进程的TSS选择符存放在任务门中。
中断门(interrupt gate)
包含段选择符和中断或异常处理程序的段内偏移量.当控制权转移到一个适当的段时,处理器清IF标志,从而关闭将来会发生的可屏蔽中断.
陷阱门(Trap gate)
与中断门相似,只是控制权传递到一个适当的段时处理器不修改IF标志.
中断门和陷阱门描述中断/异常处理程序的人口点。中断门和陷阱门内的选择子必须指向代码段描述符,门内的偏移就是对应代码段的人口点的偏移。中断门和陷阱门只有在中断描述符表IDT中才有效。